5.9. Failover and Failback
Failover means automatically detaching PostgreSQLbackend node which is not accessible by Pgpool-II. This happens automatically regardless the configuration parameter settings and is so called automatic failover process. Pgpool-II confirms the inaccessibility of PostgreSQL backend node by using following methods:
Regular health check process (see Section 5.8 for more details). The heath check process tries to connect from Pgpool-II to PostgreSQL node to confirm its healthiness. If it fails to connect, it is possible that there's something wrong with network connection between Pgpool-II and PostgreSQL, and/or PostgreSQL does not work properly. Pgpool-II does not distinguish each case and just decides that the particular PostgreSQL node is not available if health check fails.
An error occurs while connecting to PostgreSQL, or network level errors occur while communicating with it. Pgpool-II will just disconnect the session to client if failover_on_backend_error is off in that case However.
In the case When clients already connect to Pgpool-II and PostgreSQL is shutdown (please note that if no client connects to Pgpool-II at all, shutting down of PostgreSQL does not trigger a failover).
If failover_command is configured and a failover happens, failover_command gets executed. failover_command should be provided by user. From 4.1 an example script for failover command is provided as failover.sh.sample which can be a good starting point for you.
The major role of failover command is choosing new primary server from existing standby servers and promoting it for example. Another example would be let the administrator know that a failover happens by sending a mail.
While a failover could happen when a failure occurs, it is possible to trigger it by hand. This is called a switch over. For instance, switching over a PostgreSQL to take its backup would be possible. Note that switching over just sets the status to down and never bringing PostgreSQL down. A switch over can be triggered by using pcp_detach_node command.
A PostgreSQL node detached by failover or switch over will never return to the previous state (attached state) automatically in the default setting. Restarting Pgpool-II with -D option or running pcp_attach_node makes it to the attached state again. It is recommended to confirm the replication_state of SHOW POOL NODES is "streaming" before doing that. The state indicates that the standby server is properly connected to the primary server through streaming replication and both databases are in sync.
From 4.1 a new parameter auto_failback can be used to do above automatically. See auto_failback for more details.
5.9.1. Failover and Failback Settings
- failover_command (string)
Specifies a user command to run when a PostgreSQL backend node gets detached. Pgpool-II replaces the following special characters with the backend specific information.
Table 5-6. failover command options
Special character Description %d DB node ID of the detached node %h Hostname of the detached node %p Port number of the detached node %D Database cluster directory of the detached node %M Old master node ID %m New master node ID %H Hostname of the new master node %P Old primary node ID %r Port number of the new master node %R Database cluster directory of the new master node %N Hostname of the old primary node (Pgpool-II 4.1 or after) %S Port number of the old primary node (Pgpool-II 4.1 or after) %% '%' character Note: The "master node" refers to a node which has the "youngest (or the smallest) node id" among live the database nodes. In streaming replication mode, this may be different from primary node. In Table 5-6, %m is the new master node chosen by Pgpool-II. It is the node being assigned the youngest (smallest) node id which is alive. For example if you have 3 nodes, namely node 0, 1, 2. Suppose node 1 the primary and all of them are healthy (no down node). If node 1 fails, failover_command is called with %m = 0. And, if all standby nodes are down and primary node failover happens, failover_command is called with %m = -1 and %H,%R,$r = "".
Note: When a failover is performed, basically Pgpool-II kills all its child processes, which will in turn terminate all the active sessions to Pgpool-II. After that Pgpool-II invokes the failover_command and after the command completion Pgpool-II starts new child processes which makes it ready again to accept client connections.
However from Pgpool-II 3.6, in the steaming replication mode, client sessions will not be disconnected any more when a failover occurs if the session does not use the failed standby server. Please note that if a query is sent while failover is processing, the session will be disconnected. If the primary server goes down, still all sessions will be disconnected. Health check timeout case will also cause the full session disconnection. Other health check error, including retry over case does not trigger full session disconnection.
Note: You can run psql (or whatever command) against backend to retrieve some information in the script, but you cannot run psql against Pgpool-II itself, since the script is called from Pgpool-II and it needs to run while Pgpool-II is working on failover.
A complete failover_command example can be found in Section 8.3.
This parameter can be changed by reloading the Pgpool-II configurations.
- failback_command (string)
Specifies a user command to run when a PostgreSQL backend node gets attached to Pgpool-II. Pgpool-II replaces the following special characters with the backend specific information. before executing the command.
Table 5-7. failback command options
Special character Description %d DB node ID of the attached node %h Hostname of the attached node %p Port number of the attached node %D Database cluster directory of the attached node %M Old master node ID %m New master node ID %H Hostname of the new master node %P Current primary node ID %r Port number of the new master node %R Database cluster directory of the new master node %N Hostname of the old primary node (Pgpool-II 4.1 or after) %S Port number of the old primary node (Pgpool-II 4.1 or after) %% '%' character Note: You can run psql (or whatever command) against backend to retrieve some information in the script, but you cannot run psql against Pgpool-II itself, since the script is called from Pgpool-II and it needs to run while Pgpool-II is working on failover.
This parameter can be changed by reloading the Pgpool-II configurations.
- follow_master_command (string)
Specifies a user command to run after failover on the primary node failover. In case of standby node failover, the command will not be executed. This command also runs if a node promote request is issued by pcp_promote_node command. This works only in Master Replication mode with streaming replication.
Since the command is executed within a child process forked off by Pgpool-II after failover is completed, execution of follow master command does not block the service of Pgpool-II. Here is a pseud code to illustrate how the command is executed:
for each backend node { if (the node is not the new primary) set down node status to shared memory status memorize that follow master command is needed to execute } if (we need to executed follow master command) fork a child process (within the child process) for each backend node if (the node status in shared memory is down) execute follow master commandPgpool-II replaces the following special characters with the backend specific information before executing the command.
Table 5-8. follow master command options
Special character Description %d DB node ID of the detached node %h Hostname of the detached node %p Port number of the detached node %D Database cluster directory of the detached node %M Old master node ID %m New primary node ID %H Hostname of the new primary node %P Old primary node ID %r Port number of the new primary node %R Database cluster directory of the new primary node %N Hostname of the old primary node (Pgpool-II 4.1 or after) %S Port number of the old primary node (Pgpool-II 4.1 or after) %% '%' character Note: If follow_master_command is not empty, then after failover on the primary node gets completed in Master Slave mode with streaming replication, Pgpool-II degenerates all nodes except the new primary and starts new child processes to be ready again to accept connections from the clients. After this, Pgpool-II executes the command configured in the follow_master_command for each degenerated backend nodes.
Typically follow_master_command command is used to recover the slave from the new primary by calling the pcp_recovery_node command. In the follow_master_command, it is recommended to check whether target PostgreSQL node is running or not using pg_ctl since already stopped node usually has a reason to be stopped: for example, it's broken by hardware problems or administrator is maintaining the node. If the node is stopped, skip the node. If the node is running, stop the node first and recovery it. A complete follow_master_command example can be found in Section 8.3.
This parameter can be changed by reloading the Pgpool-II configurations.
- failover_on_backend_error (boolean)
When set to on, Pgpool-II considers the reading/writing errors on the PostgreSQL backend connection as the backend node failure and trigger the failover on that node after disconnecting the current session. When this is set to off, Pgpool-II only report an error and disconnect the session in case of such errors.
Note: It is recommended to turn on the backend health checking (see Section 5.8) when failover_on_backend_error is set to off. Note, however, that Pgpool-II still triggers the failover when it detects the administrative shutdown of PostgreSQL backend server. If you want to avoid a fail over even in this case, you need to specify DISALLOW_TO_FAILOVER on backend_flag.
This parameter can be changed by reloading the Pgpool-II configurations.
Note: Prior to Pgpool-II V4.0, this configuration parameter name was fail_over_on_backend_error.
- search_primary_node_timeout (integer)
Specifies the maximum amount of time in seconds to search for the primary node when a failover scenario occurs. Pgpool-II will give up looking for the primary node if it is not found with-in this configured time. Default is 300 and Setting this parameter to 0 means keep trying forever.
This parameter is only applicable in the streaming replication mode.
This parameter can be changed by reloading the Pgpool-II configurations.
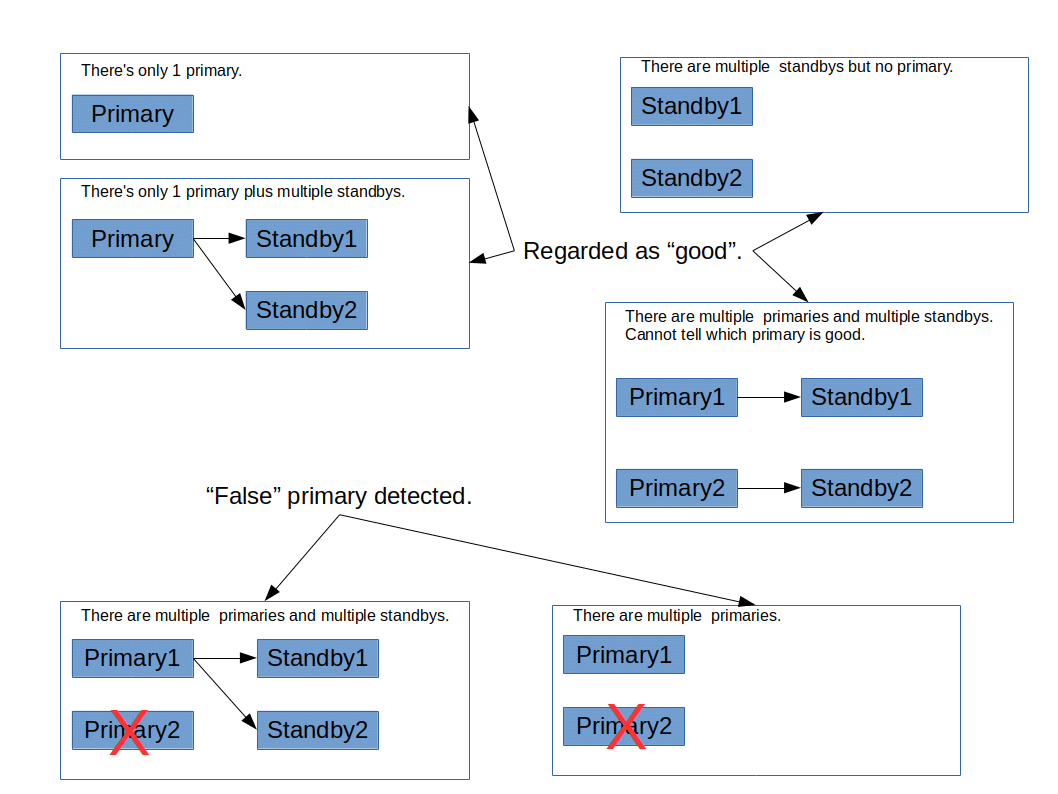
- detach_false_primary (boolean)
If set to on, detach false primary node. The default is off. This parameter is only valid in streaming replication mode and for PostgreSQL 9.6 or after since this feature uses
pg_stat_wal_receiver. If PostgreSQL 9.5.x or older version is used, no error is raised, just the feature is ignored.If there's no primary node, no checking will be performed.
If there's no standby node, and there's only one primary node, no checking will be performed.
If there's no standby node, and there's multiple primary nodes, leave the primary node which has the youngest node id and detach rest of primary nodes.
If there are one or more primaries and one or more standbys, check the connectivity between primary and standby nodes by using
pg_stat_wal_receiverif PostgreSQL 9.6 or after. In this case if a primary node connects to all standby nodes, the primary is regarded as "true" primary. Other primaries are regarded as "false" primary and the false primaries will be detached if detach_false_primary is true. If no "true" primary is found, nothing will happen.When Pgpool-II starts, the checking of false primaries are performed only once in the Pgpool-II main process. If sr_check_period is greater than 0, the false primaries checking will be performed at the same timing of streaming replication delay checking.
Note: sr_check_user must be PostgreSQL super user or in "pg_monitor" group to use this feature. To make sr_check_user in pg_monitor group, execute following SQL command by PostgreSQL super user (replace "sr_check_user" with the setting of sr_check_user):
GRANT pg_monitor TO sr_check_user;
For PostgreSQL 9.6, there's no pg_monitor group and sr_check_user must be PostgreSQL super user.
This parameter is only applicable in the streaming replication mode.
This parameter can be changed by reloading the Pgpool-II configurations.
- auto_failback (boolean)
When set to on, standby node be automatically failback, if the node status is down but streaming replication works normally. This is useful when standby node is degenerated by pgpool because of the temporary network failure.
To use this feature, Section 5.11 must be enabled, and PostgreSQL 9.1 or later is required as backend nodes. This feature use
pg_stat_replicatoinon primary node, the automatic failback is performed to standby node only. Note that failback_command will be executed as well if failback_command is not empty. If you plan to detach standby node for maintenance, set this parameter to off beforehand. Otherwise it's possible that standby node is reattached against your intention.The default is off. This parameter can be changed by reloading the Pgpool-II configurations.
- auto_failback_interval (integer)
Specifies the minimum amount of time in seconds for execution interval of auto failback. Next auto failback won't execute until that specified time have passed after previous auto failback. When Pgpool-II frequently detect backend down because of network error for example, you may avoid repeating failover and failback by setting this parameter to large enough value. The default is 60. Setting this parameter to 0 means that auto failback don't wait.
5.9.2. Failover in the raw Mode
Failover can be performed in raw mode if multiple backend servers are defined. Pgpool-II usually accesses the backend specified by backend_hostname0 during normal operation. If the backend_hostname0 fails for some reason, Pgpool-II tries to access the backend specified by backend_hostname1. If that fails, Pgpool-II tries the backend_hostname2, 3 and so on.