8.2. Pgpool-II + Watchdog Setup Example
This section shows an example of streaming replication configuration using Pgpool-II. In this example, we use 3 Pgpool-II servers to manage PostgreSQL servers to create a robust cluster system and avoid the single point of failure or split brain.
PostgreSQL 13 is used in this configuration example. All scripts have been tested with PostgreSQL 95 and later.
8.2.1. Requirements
We assume that all the Pgpool-II servers and the PostgreSQL servers are in the same subnet.
8.2.2. Cluster System Configuration
We use 3 servers with CentOS 7.4. Let these servers be server1, server2, server3. We install PostgreSQL and Pgpool-II on each server.
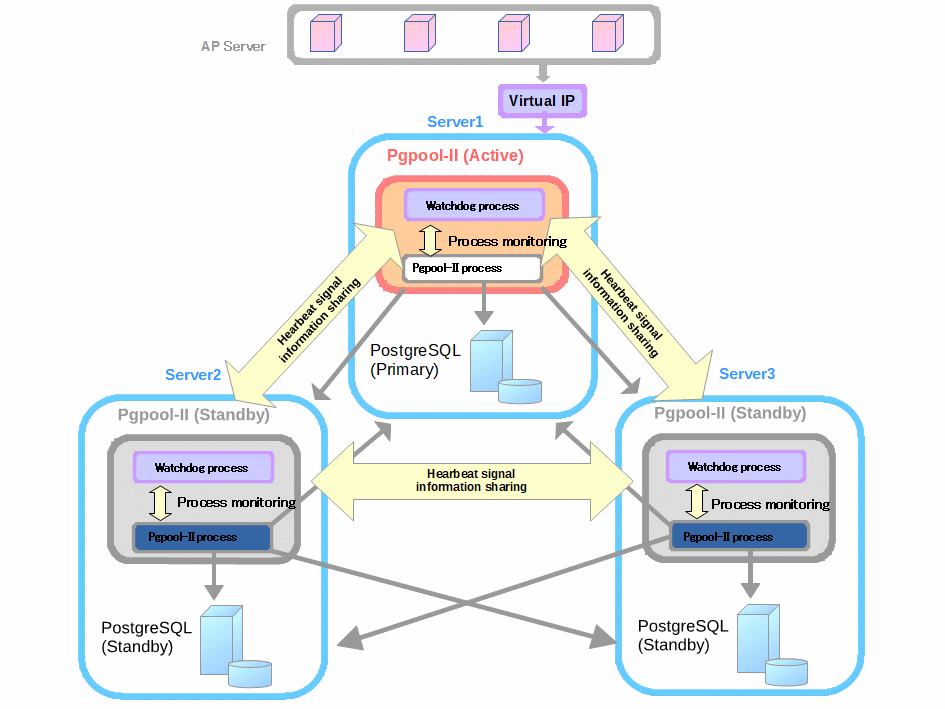
Note: The roles of Active, Standy, Primary, Standby are not fixed and may be changed by further operations.
Table 8-2. Hostname and IP address
| Hostname | IP Address | Virtual IP |
|---|---|---|
| server1 | 192.168.137.101 | 192.168.137.150 |
| server2 | 192.168.137.102 | |
| server3 | 192.168.137.103 |
Table 8-3. PostgreSQL version and Configuration
| Item | Value | Detail |
|---|---|---|
| PostgreSQL Version | 13.0 | - |
| port | 5432 | - |
| $PGDATA | /var/lib/pgsql/13/data | - |
| Archive mode | on | /var/lib/pgsql/archivedir |
| Replication Slots | Enable | - |
| Start automatically | Enable | - |
Table 8-4. Pgpool-II version and Configuration
| Item | Value | Detail |
|---|---|---|
| Pgpool-II Version | 4.2.0 | - |
| port | 9999 | Pgpool-II accepts connections |
| 9898 | PCP process accepts connections | |
| 9000 | watchdog accepts connections | |
| 9694 | UDP port for receiving Watchdog's heartbeat signal | |
| Config file | /etc/pgpool-II/pgpool.conf | Pgpool-II config file |
| Pgpool-II start user | postgres (Pgpool-II 4.1 or later) | Pgpool-II 4.0 or before, the default startup user is root |
| Running mode | streaming replication mode | - |
| Watchdog | on | Life check method: heartbeat |
| Start automatically | Enable | - |
Table 8-5. Various sample scripts included in rpm package
| Feature | Script | Detail |
|---|---|---|
| Failover | /etc/pgpool-II/sample_scripts/failover.sh.sample | Run by failover_command to perform failover |
| /etc/pgpool-II/sample_scripts/follow_primary.sh.sample | Run by follow_primary_command to synchronize the Standby with the new Primary after failover. | |
| Online recovery | /etc/pgpool-II/sample_scripts/recovery_1st_stage.sample | Run by recovery_1st_stage_command to recovery a Standby node |
| /etc/pgpool-II/sample_scripts/pgpool_remote_start.sample | Run after recovery_1st_stage_command to start the Standby node | |
| Watchdog | /etc/pgpool-II/sample_scripts/escalation.sh.sample | Run by wd_escalation_command to switch the Active/Standby Pgpool-II safely |
The above scripts are included in the RPM package and can be customized as needed.
8.2.3. Installation
In this example, we install Pgpool-II and PostgreSQL RPM packages with YUM.
Install PostgreSQL from PostgreSQL YUM repository.
[all servers]# yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm [all servers]# yum install -y postgresql13-server
Since Pgpool-II related packages are also included in PostgreSQL YUM repository, add the "exclude" settings to /etc/yum.repos.d/pgdg-redhat-all.repo so that Pgpool-II is not installed from PostgreSQL YUM repository.
[all servers]# vi /etc/yum.repos.d/pgdg-redhat-all.repo
The following is a setting example of /etc/yum.repos.d/pgdg-redhat-all.repo.
[pgdg-common] ... exclude=pgpool* [pgdg14] ... exclude=pgpool* [pgdg13] ... exclude=pgpool* [pgdg12] ... exclude=pgpool* [pgdg11] ... exclude=pgpool* [pgdg10] ... exclude=pgpool* [pgdg96] ... exclude=pgpool*
Install Pgpool-II from Pgpool-II YUM repository.
[all servers]# yum install -y https://www.pgpool.net/yum/rpms/4.2/redhat/rhel-7-x86_64/pgpool-II-release-4.2-2.noarch.rpm [all servers]# yum install -y pgpool-II-pg13-*
8.2.4. Before Starting
Before you start the configuration process, please check the following prerequisites.
Set up the primary server. Initialize PostgreSQL on the primary server.
[server1]# su - postgres [server1]$ /usr/pgsql-13/bin/initdb -D $PGDATAThen we edit the configuration file $PGDATA/postgresql.conf on server1 (primary) as follows. In this example, only Primary node archives WAL locally. Enable wal_log_hints to use pg_rewind. Since the Primary may become a Standby later, we set hot_standby = on.
listen_addresses = '*' archive_mode = on archive_command = 'cp "%p" "/var/lib/pgsql/archivedir/%f"' max_wal_senders = 10 max_replication_slots = 10 wal_level = replica hot_standby = on wal_log_hints = onSet up the standby server.There are multiple methods to setup a standby server, such as:
use Pgpool-II's online recovery feature (Section 5.10) to automatically setup a standby server.
use pg_basebackup to backup the data directory of the primary from the standby.
Note: If you set up standby manually without using online recovery, please note the following:
You must manually create the replication slots.
Do not specify the -R option when running pg_basebackup. Write primary_conninfo, recovery_target_timeline, and primary_slot_name in $PGDATA/myrecovery.conf, not in postgresql.auto.conf, and add the following to postgresql.conf.
include_if_exists = 'myrecovery.conf'In this example configuration, we will configure it to use online recovery. We create the directory /var/lib/pgsql/archivedir to store WAL segments on all servers.
[all servers]# su - postgres [all servers]$ mkdir /var/lib/pgsql/archivedirBecause of the security reasons, we create a user repl solely used for replication purpose, and a user pgpool for streaming replication delay check and health check of Pgpool-II.
Table 8-6. Users
User Name Password Detail repl repl PostgreSQL replication user pgpool pgpool Pgpool-II health check (health_check_user) and replication delay check (sr_check_user) user postgres postgres User running online recovery [server1]# psql -U postgres -p 5432 postgres=# SET password_encryption = 'scram-sha-256'; postgres=# CREATE ROLE pgpool WITH LOGIN; postgres=# CREATE ROLE repl WITH REPLICATION LOGIN; postgres=# \password pgpool postgres=# \password repl postgres=# \password postgresIf you want to show "replication_state" and "replication_sync_state" column in SHOW POOL NODES command result, role pgpool needs to be PostgreSQL super user or or in pg_monitor group (Pgpool-II 4.1 or later). Grant pg_monitor to pgpool:
GRANT pg_monitor TO pgpool;Note: If you plan to use detach_false_primary(Pgpool-II 4.0 or later), role "pgpool" needs to be PostgreSQL super user or or in "pg_monitor" group to use this feature.
Assuming that all the Pgpool-II servers and the PostgreSQL servers are in the same subnet and edit pg_hba.conf to enable scram-sha-256 authentication method.
host all all samenet scram-sha-256 host replication all samenet scram-sha-256To use the automated failover and online recovery of Pgpool-II, it is required to allow SSH public key authentication (passwordless SSH login) to all backend servers as Pgpool-II startup user (default is postgres. Pgpool-II 4.0 or before, default is root) and PostgreSQL startup user (default is postgres).
First, set postgres user's passwrod.
[all servers]# passwd postgresExecute the following command on all servers to set up passwordless SSH. In this example, we assume that the generated key file name is id_rsa_pgpool.
[all servers]# mkdir ~/.ssh [all servers]# chmod 700 ~/.ssh [all servers]# cd ~/.ssh [all servers]# ssh-keygen -t rsa -f id_rsa_pgpool [all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server1 [all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server2 [all servers]# ssh-copy-id -i id_rsa_pgpool.pub postgres@server3 [all servers]# su - postgres [all servers]$ mkdir ~/.ssh [all servers]$ chmod 700 ~/.ssh [all servers]$ cd ~/.ssh [all servers]$ ssh-keygen -t rsa -f id_rsa_pgpool [all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server1 [all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server2 [all servers]$ ssh-copy-id -i id_rsa_pgpool.pub postgres@server3After setting SSH, make sure that you can run ssh postgres@serverX -i ~/.ssh/id_rsa_pgpool command as Pgpool-II startup user and PostgreSQL startup user to log in without entering a password.
Note: If you failed to login using SSH public key authentication, please check the following:
Ensure the public key authentication option PubkeyAuthentication are allowed in /etc/ssh/sshd_config:
PubkeyAuthentication yesif the password authentication is disabled, you can fail to run ssh-copy-id, temporarily add the following configuration in /etc/ssh/sshd_config.
PasswordAuthentication yesIf SELinux is enabled, SSH public key authentication (passwordless SSH) may fail. You need to run the following command on all servers.
[all servers]# su - postgres [all servers]$ restorecon -Rv ~/.sshTo allow repl user without specifying password for streaming replication and online recovery, and execute pg_rewind using postgres, we create the .pgpass file in postgres user's home directory and change the permission to 600 on each PostgreSQL server.
[all servers]# su - postgres [all servers]$ vi /var/lib/pgsql/.pgpass server1:5432:replication:repl:<repl user password> server2:5432:replication:repl:<repl user password> server3:5432:replication:repl:<repl user password> server1:5432:postgres:postgres:<postgres user password> server2:5432:postgres:postgres:<postgres user password> server3:5432:postgres:postgres:<postgres user password> [all servers]$ chmod 600 /var/lib/pgsql/.pgpassWhen connect to Pgpool-II and PostgreSQL servers, the target port must be accessible by enabling firewall management softwares. Following is an example for CentOS/RHEL7.
[all servers]# firewall-cmd --permanent --zone=public --add-service=postgresql [all servers]# firewall-cmd --permanent --zone=public --add-port=9999/tcp --add-port=9898/tcp --add-port=9000/tcp --add-port=9694/udp [all servers]# firewall-cmd --reloadWe set Pgpool-II to start automatically on all servers.
[all servers]# systemctl enable pgpool.serviceNote: If you set the auto-start of Pgpool-II, you need to change the search_primary_node_timeout to an appropriate value that you can start the PostgreSQL after the server has been started. Pgpool-II will fail if it can't connect to the PostgreSQL on the backend during the search_primary_node_timeout.
8.2.5. Create pgpool_node_id
From Pgpool-II 4.2, now all configuration parameters are identical on all hosts. If watchdog feature is enabled, to distingusish which host is which, a pgpool_node_id file is required. You need to create a pgpool_node_id file and specify the pgpool (watchdog) node number (e.g. 0, 1, 2 ...) to identify pgpool (watchdog) host.
server1
[server1]# cat /etc/pgpool-II/pgpool_node_id 0server2
[server2]# cat /etc/pgpool-II/pgpool_node_id 1server3
[server3]# cat /etc/pgpool-II/pgpool_node_id 2
8.2.6. Pgpool-II Configuration
Since from Pgpool-II 4.2, all configuration parameters are identical on all hosts, you can edit pgpool.conf on any pgpool node and copy the edited pgpool.conf file to the other pgpool nodes.
8.2.6.1. Clustering mode
Pgpool-II has several clustering modes. To set the clustering mode, backend_clustering_mode can be used. In this configuration example, streaming replication mode is used.
When installing Pgpool-II using RPM, all the Pgpool-II configuration sample files are in /etc/pgpool-II. In this example, we copy the sample configuration file for streaming replication mode.
# cp -p /etc/pgpool-II/pgpool.conf.sample-stream /etc/pgpool-II/pgpool.conf
8.2.6.2. listen_addresses
To allow Pgpool-II and PCP to accept all incoming connections, we set listen_addresses = '*'.
listen_addresses = '*' pcp_listen_addresses = '*'
8.2.6.4. Streaming Replication Check
Specify replication delay check user and password in sr_check_user and sr_check_password. In this example, we leave sr_check_password empty, and create the entry in pool_passwd. See Section 8.2.6.9 for how to create the entry in pool_passwd. From Pgpool-II 4.0, if these parameters are left blank, Pgpool-II will first try to get the password for that specific user from pool_passwd file before using the empty password.
sr_check_user = 'pgpool' sr_check_password = ''
8.2.6.5. Health Check
Enable health check so that Pgpool-II performs failover. Also, if the network is unstable, the health check fails even though the backend is running properly, failover or degenerate operation may occur. In order to prevent such incorrect detection of health check, we set health_check_max_retries = 3. Specify health_check_user and health_check_password in the same way like sr_check_user and sr_check_password.
health_check_period = 5
# Health check period
# Disabled (0) by default
health_check_timeout = 30
# Health check timeout
# 0 means no timeout
health_check_user = 'pgpool'
health_check_password = ''
health_check_max_retries = 3
8.2.6.6. Backend Settings
Specify the PostgreSQL backend information. Multiple backends can be specified by adding a number at the end of the parameter name.
# - Backend Connection Settings -
backend_hostname0 = 'server1'
# Host name or IP address to connect to for backend 0
backend_port0 = 5432
# Port number for backend 0
backend_weight0 = 1
# Weight for backend 0 (only in load balancing mode)
backend_data_directory0 = '/var/lib/pgsql/13/data'
# Data directory for backend 0
backend_flag0 = 'ALLOW_TO_FAILOVER'
# Controls various backend behavior
# ALLOW_TO_FAILOVER or DISALLOW_TO_FAILOVER
backend_hostname1 = 'server2'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/13/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_hostname2 = 'server3'
backend_port2 = 5432
backend_weight2 = 1
backend_data_directory2 = '/var/lib/pgsql/13/data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
To show "replication_state" and "replication_sync_state" column in SHOW POOL NODES command result, backend_application_name parameter is required. Here we specify each backend's hostname in these parameters. (Pgpool-II 4.1 or later)
... backend_application_name0 = 'server1' ... backend_application_name1 = 'server2' ... backend_application_name2 = 'server3'
8.2.6.7. Failover configuration
Specify failover.sh script to be executed after failover in failover_command parameter. If we use 3 PostgreSQL servers, we need to specify follow_primary_command to run after failover on the primary node failover. In case of two PostgreSQL servers, follow_primary_command setting is not necessary.
Pgpool-II replaces the following special characters with the backend specific information while executing the scripts. See failover_command for more details about each character.
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S' follow_primary_command = '/etc/pgpool-II/follow_primary.sh %d %h %p %D %m %H %M %P %r %R'
Note: %N and %S are added in Pgpool-II 4.1. Please note that these characters cannot be specified if using Pgpool-II 4.0 or earlier.
Sample scripts failover.sh and follow_primary.sh are installed in /etc/pgpool-II/. Create failover scripts using these sample files.
[all servers]# cp -p /etc/pgpool-II/failover.sh{.sample,}
[all servers]# cp -p /etc/pgpool-II/follow_primary.sh{.sample,}
[all servers]# chown postgres:postgres /etc/pgpool-II/{failover.sh,follow_primary.sh}
Basically, it should work if you change PGHOME according to PostgreSQL installation directory.
[all servers]# vi /etc/pgpool-II/failover.sh ... PGHOME=/usr/pgsql-13 ... [all servers]# vi /etc/pgpool-II/follow_primary.sh ... PGHOME=/usr/pgsql-13 ...
Since user authentication is required to use the PCP command in follow_primary_command script, we need to specify user name and md5 encrypted password in pcp.conf in format "username:encrypted password".
if pgpool user is specified in PCP_USER in follow_primary.sh,
# cat /etc/pgpool-II/follow_primary.sh ... PCP_USER=pgpool ...
then we use pg_md5 to create the encrypted password entry for pgpool user as below:
[all servers]# echo 'pgpool:'`pg_md5 PCP passowrd` >> /etc/pgpool-II/pcp.conf
Since follow_primary.sh script must execute PCP command without entering a password, we need to create .pcppass in the home directory of Pgpool-II startup user (postgres user) on each server.
[all servers]# su - postgres [all servers]$ echo 'localhost:9898:pgpool:<pgpool user password>' > ~/.pcppass [all servers]$ chmod 600 ~/.pcppass
Note: The follow_primary.sh script does not support tablespaces. If you are using tablespaces, you need to modify the script to support tablespaces.
8.2.6.8. Pgpool-II Online Recovery Configurations
Next, in order to perform online recovery with Pgpool-II we specify the PostgreSQL user name and online recovery command recovery_1st_stage. Because Superuser privilege in PostgreSQL is required for performing online recovery, we specify postgres user in recovery_user. Then, we create recovery_1st_stage and pgpool_remote_start in database cluster directory of PostgreSQL primary server (server1), and add execute permission.
recovery_user = 'postgres'
# Online recovery user
recovery_password = ''
# Online recovery password
recovery_1st_stage_command = 'recovery_1st_stage'
Online recovery sample scriptsrecovery_1st_stage and pgpool_remote_start are installed in /etc/pgpool-II/. Copy these files to the data directory of the primary server (server1).
[server1]# cp -p /etc/pgpool-II/recovery_1st_stage.sample /var/lib/pgsql/13/data/recovery_1st_stage
[server1]# cp -p /etc/pgpool-II/pgpool_remote_start.sample /var/lib/pgsql/13/data/pgpool_remote_start
[server1]# chown postgres:postgres /var/lib/pgsql/13/data/{recovery_1st_stage,pgpool_remote_start}
Basically, it should work if you change PGHOME according to PostgreSQL installation directory.
[server1]# vi /var/lib/pgsql/13/data/recovery_1st_stage ... PGHOME=/usr/pgsql-13 ... [server1]# vi /var/lib/pgsql/13/data/pgpool_remote_start ... PGHOME=/usr/pgsql-13 ...
In order to use the online recovery functionality, the functions of
pgpool_recovery, pgpool_remote_start,
pgpool_switch_xlog are required, so we need install
pgpool_recovery on template1 of PostgreSQL server
server1.
[server1]# su - postgres [server1]$ psql template1 -c "CREATE EXTENSION pgpool_recovery"
Note: The recovery_1st_stage script does not support tablespaces. If you are using tablespaces, you need to modify the script to support tablespaces.
8.2.6.9. Client Authentication Configuration
Because in the section Before Starting, we already set PostgreSQL authentication method to scram-sha-256, it is necessary to set a client authentication by Pgpool-II to connect to backend nodes. When installing with RPM, the Pgpool-II configuration file pool_hba.conf is in /etc/pgpool-II. By default, pool_hba authentication is disabled, set enable_pool_hba = on to enable it.
enable_pool_hba = on
The format of pool_hba.conf file follows very closely PostgreSQL's pg_hba.conf format. Set pgpool and postgres user's authentication method to scram-sha-256.
host all pgpool 0.0.0.0/0 scram-sha-256 host all postgres 0.0.0.0/0 scram-sha-256
Note: Please note that in Pgpool-II 4.0 only AES encrypted password or clear text password can be specified in health_check_password, sr_check_password, wd_lifecheck_password, recovery_password in pgpool.conf.
The default password file name for authentication is pool_passwd. To use scram-sha-256 authentication, the decryption key to decrypt the passwords is required. We create the .pgpoolkey file in Pgpool-II start user postgres's (Pgpool-II 4.1 or later) home directory. (Pgpool-II 4.0 or before, by default Pgpool-II is started as root)
[all servers]# su - postgres
[all servers]$ echo 'some string' > ~/.pgpoolkey
[all servers]$ chmod 600 ~/.pgpoolkey
Execute command pg_enc -m -k /path/to/.pgpoolkey -u username -p to register user name and AES encrypted password in file pool_passwd. If pool_passwd doesn't exist yet, it will be created in the same directory as pgpool.conf.
[all servers]# su - postgres [all servers]$ pg_enc -m -k ~/.pgpoolkey -u pgpool -p db password: [pgpool user's password] [all servers]$ pg_enc -m -k ~/.pgpoolkey -u postgres -p db password: [postgres user's passowrd] # cat /etc/pgpool-II/pool_passwd pgpool:AESheq2ZMZjynddMWk5sKP/Rw== postgres:AESHs/pWL5rtXy2IwuzroHfqg==
8.2.6.10. Watchdog Configuration
Enable watchdog functionality on server1, server2, server3.
use_watchdog = on
Specify virtual IP address that accepts connections from clients on server1, server2, server3. Ensure that the IP address set to virtual IP isn't used yet.
delegate_IP = '192.168.137.150'
To bring up/down the virtual IP and send the ARP requests, we set if_up_cmd, if_down_cmd and arping_cmd. The network interface used in this example is "enp0s8". Since root privilege is required to execute if_up/down_cmd or arping_cmd command, use setuid on these command or allow Pgpool-II startup user, postgres user (Pgpool-II 4.1 or later) to run sudo command without a password.
Note: If Pgpool-II is installed using RPM, the postgres user has been configured to run ip/arping via sudo without a password.
postgres ALL=NOPASSWD: /sbin/ip postgres ALL=NOPASSWD: /usr/sbin/arping
Here we configure the following parameters to run if_up/down_cmd or arping_cmd with sudo.
if_up_cmd = '/usr/bin/sudo /sbin/ip addr add $_IP_$/24 dev enp0s8 label enp0s8:0' if_down_cmd = '/usr/bin/sudo /sbin/ip addr del $_IP_$/24 dev enp0s8' arping_cmd = '/usr/bin/sudo /usr/sbin/arping -U $_IP_$ -w 1 -I enp0s8'
Note: If "Defaults requiretty" is set in the /etc/sudoers, please ensure that the pgpool startup user can execute the if_up_cmd, if_down_cmd and arping_cmd command without a tty.
Set if_cmd_path and arping_path according to the command path. If if_up/down_cmd or arping_cmd starts with "/", these parameters will be ignored.
if_cmd_path = '/sbin' arping_path = '/usr/sbin'
Specify all Pgpool-II nodes information for configuring watchdog. Specify pgpool_portX using the port number specified in port in Section 8.2.6.3.
hostname0 = 'server1'
# Host name or IP address of pgpool node
# for watchdog connection
# (change requires restart)
wd_port0 = 9000
# Port number for watchdog service
# (change requires restart)
pgpool_port0 = 9999
# Port number for pgpool
# (change requires restart)
hostname1 = 'server2'
wd_port1 = 9000
pgpool_port1 = 9999
hostname2 = 'server3'
wd_port2 = 9000
pgpool_port2 = 9999
Specify the method of lifecheck wd_lifecheck_method and the lifecheck interval wd_interval. Here, we use hearbeat method to perform watchdog lifecheck.
wd_lifecheck_method = 'heartbeat'
# Method of watchdog lifecheck ('heartbeat' or 'query' or 'external')
# (change requires restart)
wd_interval = 10
# lifecheck interval (sec) > 0
# (change requires restart)
Specify all Pgpool-II nodes information for sending and receiving heartbeat signal.
heartbeat_hostname0 = 'server1'
# Host name or IP address used
# for sending heartbeat signal.
# (change requires restart)
heartbeat_port0 = 9694
# Port number used for receiving/sending heartbeat signal
# Usually this is the same as heartbeat_portX.
# (change requires restart)
heartbeat_device0 = ''
# Name of NIC device (such like 'eth0')
# used for sending/receiving heartbeat
# signal to/from destination 0.
# This works only when this is not empty
# and pgpool has root privilege.
# (change requires restart)
heartbeat_hostname1 = 'server2'
heartbeat_port1 = 9694
heartbeat_device1 = ''
heartbeat_hostname2 = 'server3'
heartbeat_port2 = 9694
heartbeat_device2 = ''
If the wd_lifecheck_method is set to heartbeat, specify the time to detect a fault wd_heartbeat_deadtime and the interval to send heartbeat signals wd_heartbeat_deadtime.
wd_heartbeat_keepalive = 2
# Interval time of sending heartbeat signal (sec)
# (change requires restart)
wd_heartbeat_deadtime = 30
# Deadtime interval for heartbeat signal (sec)
# (change requires restart)
When Watchdog process is abnormally terminated, the virtual IP may be "up" on both of the old and new active pgpool nodes. To prevent this, configure wd_escalation_command to bring down the virtual IP on other pgpool nodes before bringing up the virtual IP on the new active pgpool node.
wd_escalation_command = '/etc/pgpool-II/escalation.sh'
# Executes this command at escalation on new active pgpool.
# (change requires restart)
The sample script escalation.sh is installed in /etc/pgpool-II/.
[all servers]# cp -p /etc/pgpool-II/escalation.sh{.sample,}
[all servers]# chown postgres:postgres /etc/pgpool-II/escalation.sh
Basically, it should work if you change the following variables according to your environment. PGPOOL is tha array of the hostname that runnig Pgpool-II. VIP is the virtual IP address that you set as delegate_IP. DEVICE is the network interface for the virtual IP.
[all servers]# vi /etc/pgpool-II/escalation.sh
...
PGPOOLS=(server1 server2 server3)
VIP=192.168.137.150
DEVICE=enp0s8
...
Note: If you have even number of watchdog nodes, you need to turn on enable_consensus_with_half_votes parameter.
Note: If use_watchdog = on, please make sure the pgpool node number is specified in pgpool_node_id file. See Section 8.2.5 for details.
8.2.6.11. Logging
Since Pgpool-II 4.2, the logging collector process has been implemented. In the example, we enable logging collector.
log_destination = 'stderr' logging_collector = on log_directory = '/var/log/pgpool_log' log_filename = 'pgpool-%Y-%m-%d_%H%M%S.log' log_truncate_on_rotation = on log_rotation_age = 1d log_rotation_size = 10MB
Create the log directory on all servers.
[all servers]# mkdir /var/log/pgpool_log/ [all servers]# chown postgres:postgres /var/log/pgpool_log/
The configuration of pgpool.conf on server1 is completed. Copy the pgpool.conf to other Pgpool-II nodes (server2 and server3).
[server1]# scp -p /etc/pgpool-II/pgpool.conf root@server2:/etc/pgpool-II/pgpool.conf [server1]# scp -p /etc/pgpool-II/pgpool.conf root@server3:/etc/pgpool-II/pgpool.conf
8.2.7. Starting/Stopping Pgpool-II
Next we start Pgpool-II. Before starting Pgpool-II, please start PostgreSQL servers first. Also, when stopping PostgreSQL, it is necessary to stop Pgpool-II first.
Starting Pgpool-II
In section Before Starting, we already set the auto-start of Pgpool-II. To start Pgpool-II, restart the whole system or execute the following command.
# systemctl start pgpool.serviceStopping Pgpool-II
# systemctl stop pgpool.service
8.2.8. How to use
Let's start to use Pgpool-II. First, we start the primary PostgreSQL.
[server1]# su - postgres [server1]$ /usr/pgsql-13/bin/pg_ctl start -D $PGDATA
Then let's start Pgpool-II on server1, server2, server3 by using the following command.
# systemctl start pgpool.service
8.2.8.1. Set up PostgreSQL standby server
First, we should set up PostgreSQL standby server by using Pgpool-II online recovery functionality. Ensure that recovery_1st_stage and pgpool_remote_start scripts used by pcp_recovery_node command are in database cluster directory of PostgreSQL primary server (server1).
# pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 1 Password: pcp_recovery_node -- Command Successful # pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 2 Password: pcp_recovery_node -- Command Successful
After executing pcp_recovery_node command, verify that server2 and server3 are started as PostgreSQL standby server.
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes" Password for user pgpool node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+--------------------- 0 | server1 | 5432 | up | 0.333333 | primary | 0 | false | 0 | | | 2019-08-06 11:13:17 1 | server2 | 5432 | up | 0.333333 | standby | 0 | true | 0 | streaming | async | 2019-08-06 11:13:25 2 | server3 | 5432 | up | 0.333333 | standby | 0 | false | 0 | streaming | async | 2019-08-06 11:14:20 (3 rows)
8.2.8.2. Switching active/standby watchdog
Confirm the watchdog status by using pcp_watchdog_info. The Pgpool-II server which is started first run as LEADER.
# pcp_watchdog_info -h 192.168.137.150 -p 9898 -U pgpool Password: 3 YES server1:9999 Linux server1 server1 server1:9999 Linux server1 server1 9999 9000 4 LEADER #The Pgpool-II server started first becames "LEADER". server2:9999 Linux server2 server2 9999 9000 7 STANDBY #run as standby server3:9999 Linux server3 server3 9999 9000 7 STANDBY #run as standby
Stop active server server1, then server2 or server3 will be promoted to active server. To stop server1, we can stop Pgpool-II service or shutdown the whole system. Here, we stop Pgpool-II service.
[server1]# systemctl stop pgpool.service # pcp_watchdog_info -p 9898 -h 192.168.137.150 -U pgpool Password: 3 YES server2:9999 Linux server2 server2 server2:9999 Linux server2 server2 9999 9000 4 LEADER #server2 is promoted to LEADER server1:9999 Linux server1 server1 9999 9000 10 SHUTDOWN #server1 is stopped server3:9999 Linux server3 server3 9999 9000 7 STANDBY #server3 runs as STANDBY
Start Pgpool-II (server1) which we have stopped again, and verify that server1 runs as a standby.
[server1]# systemctl start pgpool.service [server1]# pcp_watchdog_info -p 9898 -h 192.168.137.150 -U pgpool Password: 3 YES server2:9999 Linux server2 server2 server2:9999 Linux server2 server2 9999 9000 4 LEADER server1:9999 Linux server1 server1 9999 9000 7 STANDBY server3:9999 Linux server3 server3 9999 9000 7 STANDBY
8.2.8.3. Failover
First, use psql to connect to PostgreSQL via virtual IP, and verify the backend information.
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes" Password for user pgpool: node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+--------------------- 0 | server1 | 5432 | up | 0.333333 | primary | 0 | false | 0 | | | 2019-08-06 11:13:17 1 | server2 | 5432 | up | 0.333333 | standby | 0 | true | 0 | streaming | async | 2019-08-06 11:13:25 2 | server3 | 5432 | up | 0.333333 | standby | 0 | false | 0 | streaming | async | 2019-08-06 11:14:20 (3 rows)
Next, stop primary PostgreSQL server server1, and verify automatic failover.
[server1]$ pg_ctl -D /var/lib/pgsql/13/data -m immediate stop
After stopping PostgreSQL on server1, failover occurs and PostgreSQL on server2 becomes new primary DB.
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes" Password for user pgpool: node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+--------------------- 0 | server1 | 5432 | down | 0.333333 | standby | 0 | false | 0 | | | 2019-08-06 11:36:03 1 | server2 | 5432 | up | 0.333333 | primary | 0 | true | 0 | | | 2019-08-06 11:36:03 2 | server3 | 5432 | up | 0.333333 | standby | 0 | false | 0 | streaming | async | 2019-08-06 11:36:15 (3 rows)
server3 is running as standby of new primary server2.
[server3]# psql -h server3 -p 5432 -U pgpool postgres -c "select pg_is_in_recovery()" pg_is_in_recovery ------------------- t [server2]# psql -h server2 -p 5432 -U pgpool postgres -c "select pg_is_in_recovery()" pg_is_in_recovery ------------------- f [server2]# psql -h server2 -p 5432 -U pgpool postgres -c "select * from pg_stat_replication" -x -[ RECORD 1 ]----+------------------------------ pid | 11059 usesysid | 16392 usename | repl application_name | server3 client_addr | 192.168.137.103 client_hostname | client_port | 48694 backend_start | 2019-08-06 11:36:07.479161+09 backend_xmin | state | streaming sent_lsn | 0/75000148 write_lsn | 0/75000148 flush_lsn | 0/75000148 replay_lsn | 0/75000148 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async reply_time | 2019-08-06 11:42:59.823961+09
8.2.8.4. Online Recovery
Here, we use Pgpool-II online recovery functionality to restore server1 (old primary server) as a standby. Before restoring the old primary server, please ensure that recovery_1st_stage and pgpool_remote_start scripts exist in database cluster directory of current primary server server2.
# pcp_recovery_node -h 192.168.137.150 -p 9898 -U pgpool -n 0 Password: pcp_recovery_node -- Command Successful
Then verify that server1 is started as a standby.
# psql -h 192.168.137.150 -p 9999 -U pgpool postgres -c "show pool_nodes" Password for user pgpool: node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay | replication_state | replication_sync_state | last_status_change ---------+----------+------+--------+-----------+---------+------------+-------------------+-------------------+-------------------+------------------------+--------------------- 0 | server1 | 5432 | up | 0.333333 | standby | 0 | false | 0 | streaming | async | 2019-08-06 11:48:05 1 | server2 | 5432 | up | 0.333333 | primary | 0 | false | 0 | | | 2019-08-06 11:36:03 2 | server3 | 5432 | up | 0.333333 | standby | 0 | true | 0 | streaming | async | 2019-08-06 11:36:15 (3 rows)