pgpool-IIとは
pgpool-IIはPostgreSQL専用のミドルウェアで、PostgreSQLのデータベースクライアントと PostgreSQLサーバの間に割り込む形で動作し、PostgrSQLに以下のような機能を追加します。
- コネクションプーリング
PostgreSQLへの接続を保存しておき、同じ属性(ユーザ名、データベース、プロトコルバージョン)を持つ接続を 受け付けたときに再利用することによって PostgreSQLへの接続オーバヘッドを低減し、システム全体のスループットを向上することができます。
- レプリケーション
pgpool-IIは複数のPostgreSQLサーバを管理することができます。レプリケーション機能を使用することにより、 物理的に2台以上のDBサーバにリアルタイムでデータを保存することができ、 万が一どれかのDBサーバに障害が発生しても運用を継続することができます。
- 負荷分散
レプリケーションまたマスタースレーブモードで運用している場合、どのサーバに問い合わせても同じ結果が返ってきます。 多数の検索リクエストをそれぞれのサーバで分担して負荷を軽減させ、システム全体の性能を向上させることができます。 最良の場合にはサーバ台数に比例した性能向上が見込めます。
特に多数のユーザが大量の問い合わせを投げるような環境で威力を発揮します。
- 接続数の制限
PostgreSQLに接続可能なセッション数には上限があり、それを超えて接続することはできません。 かと言って、同時セッション数をむやみに多くすると、メモリーなどのリソースが多く消費されて パフォーマンスに影響があります。
pgpool-IIでもクライアントからの接続数には上限がありますが、それを超えてもただちにエラーになることはなく、 一定の間待たされるようになっています。 したがって、pgpool-IIはPostgreSQLへの接続要求を実質的にキューイングし、 PostgreSQLへの過大な接続数を制限することが可能です。
- パラレルクエリ
複数のサーバにデータを分割して受け持たせ、それぞれのサーバに同時に検索問い合わせを投げて、 問い合わせの処理時間を短縮するパラレルクエリが利用できます。 特に大規模なデータベースに対して検索を実行するときに威力を発揮します。
pgpool-IIはPostgreSQLバックエンドとフロントエンドの通信プロトコルを理解してその間を中継します。 すなわち、PostgreSQLのデータベースアプリケーションからはPostgreSQLサーバに、 PostgreSQLからはデータベースアプリケーションに見えるように設計されています。
そのため、PostgreSQLそのものはもちろん、アプリケーションの開発言語によらず、 PostgreSQLのデータベースアプリケーションにほとんど手を加えることなく、 pgpool-IIの機能が利用できます。
一部のSQLには制限事項があります。
License
Copyright (c) 2003-2013 PgPool Global Development Group
Permission to use, copy, modify, and distribute this software and its documentation for any purpose and without fee is hereby granted, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation, and that the name of the author not be used in advertising or publicity pertaining to distribution of the software without specific, written prior permission. The author makes no representations about the suitability of this software for any purpose. It is provided "as is" without express or implied warranty.
pgpool-II の稼働環境
pgpool-II は、Linux をはじめ、Solaris や FreeBSD などのほとんどの UNIX 環境で動作します。 Windows では動きません。
対応する PostgreSQL のバージョンは、PostgreSQL の 6.4 以降です。 ただしパラレルクエリモードを使用するときは PostgreSQL 7.4 以降をお使いください。 また、PostgreSQL 7.4 より前のバージョンでは、使用できる機能に制限事項があります。 もっとも、そのような古いバージョンの PostgreSQL はそもそも使うべきではありません。
pgpool-II 配下で利用する PostgreSQL サーバのメジャーバージョン、 OS やハードウェアアーキテクチャを同じものにしなければなりません。 また、バージョンが同じであっても、PostgreSQL のビルド方法が違うものを混ぜている場合の動作は保証できません。 たとえば、SSL サポートの有無、日付型の実装方法 (--disable-integer-datetimes)、 ブロックサイズの違いなどは、pgpool-II の一部の機能に影響を与えるでしょう。 PostgreSQL のマイナーバージョンが違う場合は大抵の場合問題になりませんが、 すべての PostgreSQL のマイナーバージョンを検証したわけではないので、 できればマイナーバージョンを合わせておくことをお勧めします。
pgpool-II のインストール
Linux 用の RPM パッケージは、CentOS、RedHat Enterprise Linux、Fedora、Debian 用などが提供されています。 該当リポジトリをチェックしてみてください。
pgpool-II のソースコードは pgpool 開発ページ から ダウンロードできます。
pgpool-II のソースコードからのインストールには、gcc 2.9 以上、および GNU make が必要です。 また、pgpool-II は libpq(PostgreSQL 付属のクライアントライブラリ)を使用するので、 ビルドを行うマシン上に libpq がインストールされていることが必要です。
また、OpenSSL サポートを有効にする場合は、OpenSSL ライブラリと開発用のヘッダーファイルが必要です。
pgpool-II のインストール
- configureの実行
-
ソースコードのtar ballを展開したら、configureを実行します。
./configure
configureに指定できるオプションは以下です。
--prefix=pathpgpool-II 本体や関連ファイルをインストールするトップディレクトリを指定します。 デフォルトは /usr/local です。 --with-pgsql=pathPostgreSQL のクライアントライブラリなどがインストールされているトップディレクトリを指定します。 デフォルトは pg_configコマンドで取得できるパスです。--with-opensslpgpool-II を OpenSSL サポート付で作成します。 デフォルトでは OpenSSL サポートは無効です。 V2.3 〜 --enable-sequence-lockpgpool-II 3.0シリーズ (3.0.4まで) 互換の insert_lock を使用します。 pgpool-II は、シーケンステーブルの行に対してロックを行います。 これは、2011 年 06 月より後にリリースされた PostgreSQL 8.2 以降では使用できません。 V3.1 〜 --enable-table-lockpgpool-II 2.2 と 2.3 シリーズ互換の insert_lock を使用します。 pgpool-II は、挿入対象のテーブルに対してロックを行ないます。 これは、ロックが VACUUM と競合するため非推奨です。 V3.1 〜 --with-memcached=pathキャッシュストレージに memcached を利用し、 オンメモリクエリキャッシュ機能を 利用したい場合に指定します。 libMemcachedのインストールが必要です。 V3.2 〜 - makeの実行
-
make make install
関数の登録
pgpool_regclass のインストール(推奨) V3.0 〜
PostgreSQL 8.0 以降を使用している場合は、pgpool-II が内部で使用する C 関数 pgpool_regclass をインストールします。
pgpool_regclass とは?
この関数がインストールされていなくても pgpool-II は動作しますが、違うスキーマで同じテーブル名を定義していて、 SQL 文の中でスキーマ名を省略している場合に、不具合が生じることがあります(一時テーブルを除く)。 したがって、可能ならば pgpool_regclass をインストールすることをお勧めします。
関数のインストール
このインストールは、pgpool-II がアクセスする予定のすべての PostgreSQL サーバで実施してください。
$ cd pgpool-II-x.x.x/sql/pgpool-regclass $ make $ make install
この後に以下か、
$ psql -f pgpool-regclass.sql template1
または
$ psql template1 =# CREATE EXTENSION pgpool_regclass;
を実行します。
備考
pgpool-regclass.sql または CREATE EXTENSION の実行は、
pgpool-II 経由で利用するデータベース毎に必要になります。
ただし、template1 データベースに対して "psql -f pgpool-regclass.sql template1" または
CREATE EXTENSION を実行後に作成されたデータベースでは、
新たに pgpool-regclass.sql または CREATE EXTENSION を実行する必要はありません。
insert_lock テーブルの作成 V3.0 〜
レプリケーションモードでの insert_lock
レプリケーションモードで insert_lock を利用したい場合は、排他制御用のテーブル pgpool_catalog.insert_lock を作成します。
insert_lock テーブルが存在しなくても今のところ insert_lock は動作しますが、 その場合は、挿入対象のテーブルに対してロックが行われます。 これは pgpool-II 2.2 と 2.3 シリーズの動作と同じです。挿入対象のテーブルに対するロックは、 VACUUM と競合して INSERT 処理が長時間が待たされる可能性があります。
したがって、insert_lock テーブルを作成することをお勧めします。 テーブルの作成は、pgpool-II がアクセスする予定のすべての PostgreSQL サーバで実施してください。
テーブルの作成
$ cd pgpool-II-x.x.x/sql $ psql -f insert_lock.sql template1
備考
insert_lock.sqlの実行は、pgpool-II経由で利用するデータベース毎に必要になります。
ただし、"psql -f insert_lock.sql template1" を実行後に作成されたデータベースでは
自動的に insert_lock.sql の内容が反映されているので、新たに insert_lock.sql を実行する必要はありません。
pgpool_recovery のインストール
後述の オンラインリカバリ の機能を使う場合には、 pgpool_recovery, pgpool_remote_start, pgpool_switch_xlog という関数が必要です。
また管理ツールである pgpoolAdmin の画面上から、バックエンドノードの PostgreSQL を停止・再起動・ 設定再読み込みを行なうことができますが、これには pgpool_pgctl という関数が使われます。
これらの機能を使いたい場合には、上記の pgpool_regclass と同様の手順でこれらの C 関数を登録します。 なお、この 4 つの関数は、すべてのデータベースにインストールされている必要はなく、template1 にだけで 構いません。
$ cd pgpool-II-x.x.x/sql/pgpool-recovery $ make $ make install
この後に以下か、
$ psql -f pgpool-recovery.sql template1
または
$ psql template1 =# CREATE EXTENSION pgpool_recovery;
を実行します。
pgpool.pg_ctl の設定 V3.3 〜
pgpool_pgctl 関数は、バックエンドノードの PostgreSQL の 「pgpool.pg_ctl」という カスタムパラメータに書かれたコマンドを実行します。 この関数を使うには、このパラメータに pg_ctl コマンドのパスを指定します。
ex) $ cat >> /usr/local/pgsql/postgresql.conf pgpool.pg_ctl = '/usr/local/pgsql/bin/pg_ctl' $ pg_ctl reload -D /usr/local/pgsql/data
pgpool-IIの設定
pgpool-IIの設定ファイルはデフォルトでは/usr/local/etc/pgpool.confおよび /usr/local/etc/pcp.confです。pgpool-IIは動作モードによって使用できる機能と、 必要な設定項目が異なります。
| 使用できる機能/モード | rawモード(*3) | レプリケーションモード | マスタスレーブモード | パラレルクエリモード |
|---|---|---|---|---|
| コネクションプーリング | × | ○ | ○ | ○ |
| レプリケーション | × | ○ | × | △(*1) |
| 負荷分散 | × | ○ | ○ | △(*1) |
| フェイルオーバ | ○ | ○ | ○ | × |
| オンラインリカバリ | × | ○ | △(*2) | × |
| パラレルクエリ | × | × | × | ○ |
| サーバ台数 | 1以上 | 2以上 | 2以上 | 2以上 |
| システムDB | 不要 | 不要 | 不要 | 必要 |
- (*1)パラレルクエリモードでは、レプリケーションまたは負荷分散を有効にする必要があります。 ただし、分割して保存しているテーブルに対しては、レプリケーションならびに負荷分散の機能は使用されません。
- (*2)マスタースレーブモードでは、Streaming Replicationと併用するときにのみ オンラインリカバリが可能です。
- (*3)単にpgpool-IIを経由して接続するだけのモードです。 レプリケーションモードもマスタースレーブモードも有効にしていないときの動作です。 PostgreSQLサーバへの接続セッション数を制限したり、2台以上のPostgreSQLサーバを用意して フェイルオーバ動作をさせたいときに利用します。
pcp.confの設定
どの動作モードでも、pcp.confの設定は必要です。pgpool-IIには管理者がpgpool-IIの 停止や情報取得などの管理操作を行うためのインターフェイスが用意されています。 そのインターフェイスを利用するためにはユーザ認証が必要になるので、 そのユーザ名とパスワードをpcp.confに登録します。 pgpool-IIをインストールすると、$prefix/etc/pcp.conf.sampleができるので、それを $prefix/etc/pcp.confという名前でコピーします。
cp $prefix/etc/pcp.conf.sample $prefix/etc/pcp.conf
pcp.confでは空白行や#で始まる行はコメントと見なされます。 ユーザとパスワードは、
ユーザ名:[md5暗号化したパスワード]
のように指定します。 [md5暗号化したパスワード]は、$prefix/bin/pg_md5コマンドで作成できます。
./pg_md5 foo acbd18db4cc2f85cedef654fccc4a4d8
パスワードを引数に渡したくない場合は pg_md5 -p を実行してください。
./pg_md5 -p password: <パスワードを入力>
pcp.confは、pgpool-IIを動作させるユーザIDで読み取り可能になっていなければ なりません。
pgpool.confの設定
サンプルファイル V2.3 〜
pgpool-IIをインストールすると、インストール先ディレクトリ(デフォルトでは/usr/local) /etc/pgpool.conf.sampleができるので、それを インストール先ディレクトリ/etc/pgpool.confという名前でコピーします。
cp インストール先ディレクトリ/etc/pgpool.conf.sample $prefix/etc/pgpool.conf
また、各動作モード用のサンプルpgpool.confが用意されています。 こちらもご利用下さい。
| 動作モード | サンプルファイル名 |
|---|---|
| レプリケーションモード | pgpool.conf.sample-replication |
| マスタースレーブモード(Slony-I) | pgpool.conf.sample-master-slave |
| マスタースレーブモード(Streaming replication) | pgpool.conf.sample-stream |
コメントの扱い
pgpool.confでは空白行や#で始まる行はコメントと見なされます。
共通設定項目
各動作モードで共通する設定項目を説明します。
Connections
- listen_addresses
-
pgpool-IIがTCP/IPコネクションを受け付けるアドレスをホスト名またはIPアドレスで指定します。 「*」を指定するとすべてのIPインタフェースからのコネクションを受け付けます。 「''」を指定するとTCP/IPコネクションを受け付けません。デフォルト値は「localhost」です。 UNIXドメインソケット経由のコネクションは常に受け付けます。
このパラメータを変更した時には pgpool-II を再起動してください。
- port
-
pgpool-IIがコネクションを受け付けるポート番号です。デフォルト値は9999 です。 このパラメータを変更した時には pgpool-II を再起動してください。
- socket_dir
-
pgpool-IIがコネクションを受け付けるUNIXドメインソケットを置くディレクトリです。 デフォルト値は'/tmp'です。 このソケットは、cronによって削除されることがあるので注意してください。
'/var/run'などのディレクトリに変更することをお勧めします。このパラメータを変更した時には pgpool-II を再起動してください。
- pcp_port
-
pcpが使用するポート番号です。
このパラメータを変更した時には pgpool-II を再起動してください。
- pcp_socket_dir
-
pcpがコネクションを受け付けるUNIXドメインソケットを置くディレクトリです。 デフォルト値は'/tmp'です。 このソケットは、cronによって削除されることがあるので注意してください。
'/var/run'などのディレクトリに変更することをお勧めします。このパラメータを変更した時には pgpool-II を再起動してください。
- backend_socket_dir 〜 V3.0
-
DEPRECATED(〜 3.0) このパラメータは、libpqのポリシーに合わせて削除されます。 代わりに backend_hostname パラメータを使ってください。
UNIXドメインソケット経由でpgpool-IIがPostgreSQLと接続する際に使用する PostgreSQLのUNIXドメインソケットが置かれているディレクトリです。デフォルト値は/tmpです。
このパラメータを変更した時には pgpool-II を再起動してください。
Pools
- num_init_children
-
preforkするpgpool-IIのサーバプロセスの数です。デフォルト値は32になっています。 これが、pgpool-IIに対してクライアントが同時に接続できる上限の数になります。 これを超えた場合は、そのクライアントは、pgpool-IIのどれからのプロセスへのフロントエンドの接続が終了するまで 待たされます(PostgreSQLと違ってエラーになりません)。 待たされる数の上限は、2 * num_init_children です。
基本的に後述のmax_pool * num_init_children分だけPostgreSQLへのコネクションが張られますが、 他に以下の考慮が必要です。
- 問い合わせのキャンセルを行うと通常のコネクションとは別に新たなコネクションが張られます。 したがって、すべてのコネクションが使用中の場合は問い合わせのキャンセルができなくなってしまうので、 ご注意下さい。 問い合わせのキャンセルを必ず保証したい場合は、想定されるコネクション数の倍の値を 設定することをおすすめします。
- 一般ユーザでPostgreSQLに接続できるのは、 max_connections - superuser_reserved_connections 分だけです。
以上をまとめると、
クエリのキャンセルを考慮しない場合 max_pool * num_init_children <=
(max_connections - superuser_reserved_connections)クエリのキャンセルを考慮する場合 max_pool * num_init_children * 2 <=
(max_connections - superuser_reserved_connections)のどちらかを満たすように設定してください。
このパラメータを変更した時には pgpool-II を再起動してください。
- child_life_time
-
pgpool-IIの子プロセスの寿命です。アイドル状態になってから child_life_time秒経過すると、一旦終了して新しいプロセスを起動します。 メモリーリークその他の障害に備えた予防措置です。 child_life_timeのデフォルト値は300秒、すなわち5分です。 0を指定するとこの機能は働きません(すなわち起動しっ放し)。 なお、まだ一度もコネクションを受け付けていないプロセスにはchild_life_timeは適用されません。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- child_max_connections
-
各pgpool-II子プロセスへの接続回数がこの設定値を超えると、その子プロセスを終了します。 child_life_time や connection_life_timeが 効かないくらい忙しいサーバで、 PostgreSQLバックエンドが肥大化するのを防ぐのに有効です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- client_idle_limit
-
前回クライアントから来たクエリから、client_idle_limit 秒越えても次の クエリが届かない場合は、クライアントへの接続を強制的に切断し、 クライアントからの次のコネクションを待つようにします。 この設定は、だらしないクライアントプログラムや、クライアントとpgpoolの間の TCP/IPコネクションが不調なことによって、 pgpoolの子プロセスが占有されてしまう問題を回避するのに役立ちます。 デフォルト値は 0(無効)です。このパラメータは、オンラインリカバリのセカンドステージでは無視されます。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- enable_pool_hba
-
trueならば、pool_hba.confに従ってクライアント認証を行います。 詳細はクライアント認証(HBA)のためのpool_hba.conf設定方法を参照してください。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- pool_passwd
-
md5 認証で用いる認証ファイルのファイル名を指定します。 デフォルト値は "pool_passwd" です。 空文字列("")を指定すると 認証ファイルの読込は無効になります。 詳細は認証・アクセス制御方式を参照してください。
このパラメータを変更した時には pgpool-II を再起動してください。
- authentication_timeout
-
認証処理のタイムアウト時間を秒単位で指定します。0 を指定するとタイムアウトを無効にします。 authentication_timeout のデフォルト値は60です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
Logs
- log_destination V3.1 〜
-
pgpool-IIは、stderrかsyslogのどちらかにログを書くことができます。デフォルトはstderrです。
注意:syslogを使う場合は、syslogデーモンの設定を変更する必要があります。
pgpool-IIは、syslog ファシリティ LOCAL0 から LOCAL7 までにログを書くことができます (syslog_facilityをご覧ください)。 しかし、ほとんどのデフォルトのsyslog設定は、そのようなメッセージを廃棄してしまいます。 そこで、syslogデーモンの以下のような設定が必要になります。
local0.* /var/log/pgpool.log
- print_timestamp
-
trueならばpgpool-IIのログにタイムスタンプを追加します。デフォルトはtrueです。
このパラメータを変更した時には pgpool-II を再起動してください。
- log_connections
-
trueならば、全てのクライアント接続をログへ出力します。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- log_hostname
-
trueならば、psコマンドでの状態表示時にIPアドレスではなく、ホスト名を表示します。 また、log_connectionsが有効な場合にはログにホスト名を出力します。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- log_statement
-
trueならばSQL文をログ出力します。この役目はPostgreSQLのlog_statementオプションと似ていて、 デバッグオプションがないときでも問い合わせをログ出力して調べることができるので便利です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- log_per_node_statement V2.3 〜
-
log_statementと似ていますが、DBノード単位でログが出力されるので、 レプリケーションや負荷分散の確認が容易です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- syslog_facility V3.1 〜
-
syslogが有効な場合、このパラメータによってsyslogの「ファシリティ」を設定します。 LOCAL0, LOCAL1, LOCAL2, LOCAL3, LOCAL4, LOCAL5, LOCAL6, LOCAL7から選択します。 デフォルトは LOCAL0 です。 併せてsyslogデーモンのドキュメントもご覧ください。
- syslog_ident V3.1 〜
-
syslogが有効な場合、このパラメータによってsyslogのメッセージにあらわれるプログラム名を設定します。 デフォルトは"pgpool"です。
- debug_level V3.0 〜
-
デバッグメッセージの詳細レベル。0でデバッグメッセージの出力なし。 1以上でデバッグメッセージを出力します。 数字が大きければより詳細なメッセージが出力されるようになります (3.0では今のところメッセージの詳細度は変りません)。 デフォルト値は0です。
File locations
- pid_file_name V2.2 〜
-
pgpool-IIのpid file(プロセスIDを格納したファイル)のフルパス名です。 デフォルト値は'/var/run/pgpool/pgpool.pid'です。
このパラメータを変更した時には pgpool-II を再起動してください。
- logdir
-
このディレクトリ下に、pgpool-IIのDBノードの状態を記録するpgpool_statusファイルが書かれます。
Connction pooling
- connection_cache
-
trueならPostgreSQLへのコネクションをキャッシュします。デフォルトはtrueです。
このパラメータを変更した時には pgpool-II を再起動してください。
Health check
- health_check_timeout
-
pgpool-IIはサーバ障害やネットワーク障害を検知するために、定期的にバックエンドに接続を試みます。 これを「ヘルスチェック」と言います。障害が検知されると、フェイルオーバや縮退運転を試みます。
この パラメータは、ネットワークケーブルが抜けた際などにヘルスチェックが長時間待たされるのを防ぐための タイムアウト値を秒単位で指定します。 デフォルトは20秒です。0を指定するとタイムアウト処理をしません (すなわち TCP/IP のタイムアウトまで待つことになります)。
なお、ヘルスチェックを有効にすると、ヘルスチェックのための余分の接続が1つ必要になりますので、 PostgreSQLのpostgresql.confの設定項目のmax_connectionsを少くとも1増やすようにしてください。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- health_check_period
-
ヘルスチェックを行う間隔を秒単位で指定します。0を指定するとヘルスチェックを行いません。 デフォルトは0です(つまりヘルスチェックを行いません)。 このパラメータを変更した時には設定ファイルを再読み込みしてください。
- health_check_user
-
ヘルスチェックを行うためのPostgreSQLユーザ名です。 このユーザ名はPostgreSQLに登録済みでなければなりません。 さもないと、ヘルスチェックがエラーとなります。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- health_check_password V3.1 〜
-
ヘルスチェックを行うためのPostgreSQLパスワードです。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- health_check_max_retries V3.2 〜
-
ヘルスチェックに失敗した後(したがってフェイルオーバする前に)リトライする回数を指定します。 この設定は動作にむらのあるネットワーク環境において、マスタが正常であるにも関わらず たまにヘルスチェックが失敗することが予想される場合に有用です。 デフォルト値は0で、この場合はリトライをしません。 この設定を有効にする場合は、併せてfail_over_on_backend_errorを offにすることをお勧めします。
health_check_max_retriesを変更した場合は、pgpool.confの再読込が必要です。
- health_check_retry_delay V3.2 〜
-
ヘルスチェックのリトライの間の秒数を指定します(health_check_max_retries > 0でなければ有効になりません)。 0を指定すると、待ちなしに直ちにリトライします。
health_check_retry_delayを変更した場合は、pgpool.confの再読込が必要です。
- search_primary_node_timeout V3.3 -
-
このパラメータはフェイルオーバーが起きた時にプライマリノードを検索する際のタイムアウト時間を秒単位で指定します。 デフォルト値は10です。 pgpool-IIは、フェイルオーバの際にここで指定した時間プライマリノードを検索し続けます。 0を指定すると、永久に検索し続けます。 このパラメータはストリーミングレプリケーションモードで運用している場合以外は無視されます。
search_primary_node_timeoutを変更した場合は、pgpool.confの再読込が必要です。
Failover and failback
- failover_command
-
ノードが切り離された時に実行するコマンドを指定します。特殊文字を指定すると、 pgpool が必要な情報に置き換えてコマンドを実行します。
文字 意味 %d 切り離されたノード番号 %h 切り離されたノードのホスト名 %H 新しいマスターのホスト名 %p 切り離されたノードのポート番号 %D 切り離されたノードのデータベースクラスタパス %M 古いマスターのノード番号 %m 新しいマスターのノード番号 %P 古いプライマリノード番号 %r 新しいマスターのポート番号 %R 新しいマスターのデータベースクラスタパス %% '%'文字 このパラメータを変更した時には設定ファイルを再読み込みしてください。
フェイルオーバー時には、pgpoolはまず子プロセスを切断します(結果として、すべてのセッションが切断されます)。 次に、pgpoolはフェイルオーバコマンドを実行し、その完了を待ちます。 そのあとで新しいpgpoolの子プロセスが起動され、クライアントからの接続を受け付けられる状態になります。
- failback_command
-
ノードが復帰した時に実行するコマンドを指定します。特殊文字を指定すると、 pgpool が必要な情報に置き換えてコマンドを実行します。
文字 意味 %d 復帰したノード番号 %h 復帰したノードのホスト名 %p 復帰したノードのポート番号 %D 復帰したノードのデータベースクラスタパス %M 古いマスターのノード番号 %m 新しいマスターのノード番号 %H 新しいマスターのホスト名 %P 古いプライマリノード番号 %r 新しいマスターのポート番号 %R 新しいマスターのデータベースクラスタパス %% '%'文字 このパラメータを変更した時には設定ファイルを再読み込みしてください。
- follow_master_command V3.1 〜
-
マスターノードのフェイルオーバー後に実行するコマンドを指定します。 これは、マスタースレーブモードでストリーミングレプリケーション構成の場合のみ有効です。 特殊文字を指定すると、pgpool が必要な情報に置き換えてコマンドを実行します。
文字 意味 %d 切り離されたノード番号 %h 切り離されたノードのホスト名 %p 切り離されたノードのポート番号 %D 切り離されたノードのデータベースクラスタパス %M 古いマスターのノード番号 %m 新しいマスターのノード番号 %H 新しいマスターのホスト名 %P 古いプライマリノード番号 %r 新しいマスターのポート番号 %R 新しいマスターのデータベースクラスタパス %% '%'文字 このパラメータを変更した時には設定ファイルを再読み込みしてください。
空文字列以外を指定すると、マスターノードのフェイルオーバー後に新しいマスター以外のすべてのノードは切り離され、 クライアントから再び接続を受け付けるために子プロセスの再起動が行われます。 その後、切り離されたそれぞれのノードに対してfollow_master_commandに指定したコマンドが実行されます。 通常は、ここに pcp_recovery_node コマンドを組み込んだシェルスクリプトなどを 指定し、新しいマスターからスレーブをリカバリするために使用します。
- fail_over_on_backend_error V2.3 〜
-
trueならば、バックエンドのソケットへからの読み出し、書き込みに失敗するとフェイルオーバします。 falseにすると、フェイルオーバせず、単にエラーがレポートされてセッションが切断されます。 このパラメータをfalseにする場合には、health checkを有効にすることをお勧めします。 なお、このパラメータがfalseの場合でも、バックエンドがシャットダウンされたことを pgpool-IIが検知した場合にはフェイルオーバが起きることに注意してください。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
Load balancing mode
- ignore_leading_white_space
-
trueならば、load balanceの際にSQL文行頭の空白を無視します(全角スペースは無視されません)。 これは、DBI/DBD:Pgのように、勝手に行頭にホワイトスペースを追加するようなAPIを使い、 ロードバランスしたいときに有効です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
Backends
- backend_hostname
-
使用するPostgreSQLサーバのホスト名を指定します。 pgpool-IIは、このホスト名を使ってPostgreSQLと通信します。
TCP/IPを使用する場合、ホスト名またはIPアドレスを指定できます。 "/"で始まる文字列を指定すると、TCP/IPではなく、UNIXドメインソケットを使用され、 ディレクトリ名とみなしてそこにソケットファイルが作成されることになります。 空文字(
'')を指定すると、/tmp下に作成したUNIXドメインソケットで接続します。実際には、"backend_hostname"の後に0, 1, 2...と数字を付加して使用する複数 のPostgreSQLを区別します(たとえば
backend_hostname0)。 この数字のことを「DBノードID」と呼び、0から開始します。 DBノードID == 0のPostgreSQLは、特別に「マスターDB」と呼ばれます。 複数のDBノードを運用している場合、条件によってはマスターDBがダウンしても運用を続けることができます。 この場合は、稼働中かつDBノードIDがもっとも若いものが新しいマスターDBになります。ただし、ストリーミングレプリケーションモードで運用している場合は、 DBノードIDが0のノードには特別な意味はなく、プライマリノードかどうかが問題になります。 詳細はStreaming Replicationへの対応をご覧ください。
1台しかPostgreSQLを使用しない場合は、"backend_hostname0"としてください。
backend_hostname は新しく追加した行を設定ファイル再読み込みで追加することができます。 すでにある情報を途中で変更することはできません。 変更する場合には pgpool-II を再起動してください。
- backend_port
-
使用するPostgreSQLサーバのポート番号を指定します。 実際には、"backend_port"の後に0, 1, 2...とDBノードIDを付加して使用する複数のPostgreSQLを区別します。 1台しかPostgreSQLを使用しない場合は、"backend_port0"としてください。
backend_port は新しく追加した行を設定ファイル再読み込みで追加することができます。 すでにある情報を途中で変更することはできません。変更する場合には pgpool-II を再起動してください。
- backend_weight
-
使用するPostgreSQLサーバに対する負荷分散の比率を0以上の整数または浮動小数点で指定します。 "backend_weight"の後には、DBノードIDを付加して使用する複数のPostgreSQLを区別します。 1台しかPostgreSQLを使用しない場合は、"backend_weight0"としてください。 負荷分散を使用しない場合は、「1」を設定してください。
backend_weight は新しく追加した行を設定ファイル再読み込みで追加することができます。 pgpool-II 2.2.6/2.3以降では、設定ファイルの再読込でbackend_weight値を変更できます。 新しく接続したクライアントセッションから、この新しいweight値が反映されます。 マスタースレーブモードにおいて、あるスレーブに対して管理業務を実施する都合上、 問い合わせがそのスレーブに送られるのを防ぎたい場合に有用です。
- backend_data_directory
-
使用する PostgreSQL サーバのデータベースクラスタのパスを指定します。 実際には、"backend_data_directory"の後にDBノードIDを付加して使用する複数のPostgreSQLを区別します。 このパラメータはオンラインリカバリの際に使用します。 オンラインリカバリを使用しない場合には設定する必要はありません。
backend_data_directory は新しく追加した行を設定ファイル再読み込みで追加することができます。 すでにある情報を途中で変更することはできません。変更する場合には pgpool-II を再起動してください。
- backend_flag V3.1 〜
-
バックエンド単位での様々な挙動を制御するフラグです。 実際には、"backend_flag"の後に数字を付けて、どのバックエンドのフラグか指定します。
例:
backend_flag0複数のフラグを"|"で連結して指定することができます。 現在以下のものがあります。
ALLOW_TO_FAILOVER フェイルオーバやデタッチが可能になります。これがデフォルトの動作です。 DISALLOW_TO_FAILOVERと同時には指定できません。 DISALLOW_TO_FAILOVER フェイルオーバやデタッチが行われeせん。 HeartbeatやPacemakerなどのHA(High Availability)ソフトでバックエンドを二重化しているなどの事情で、 pgpool-II側でフェイルオーバの制御をして欲しくないときなどに指定します。 ALLOW_TO_FAILOVERと同時には指定できません。 このパラメータを変更した時には pgpool-II を再起動してください。
SSL
- ssl V2.3 〜
-
trueならばpgpool-IIとフロントエンド、pgpool-IIとバックエンドの間のSSL接続が可能になります。 なお、pgpool-IIとフロントエンドの接続にSSLが利用できるためには、
ssl_keyとssl_certが設定されてなければなりません。デフォルトではSSLサポートはオフになっています。 SSLサポートを有効にするためには、configure時にOpenSSLサポートを有効にする必要があります。 詳細はインストールの項目をご覧下さい。
sslを有効に設定したら、pgpoolの再起動をしてください。
- ssl_key V2.3 〜
-
フロントエンドとの接続に使用するプライベートキーファイルのフルパスを指定します。
ssl_keyのデフォルト値はありません。 ssl_keyの設定がない場合は、フロントエンドとの接続でSSLが使用されなくなります。
- ssl_cert V2.3 〜
-
フロントエンドとの接続に使用する公開x509証明書のフルパスを指定します。
ssl_certのデフォルト値はありません。 ssl_certの設定がない場合は、フロントエンドとの接続でSSLが使用されなくなります。
- ssl_ca_cert
-
1 つ以上の CA ルート証明書を格納している PEM 形式ファイルのパスを指定します。 このファイルはバックエンドサーバ証明書の検証に用いられます。 このオプションは OpenSSL の
verify(1)コマンドにおける-CAfileオプションと同様の機能を提供します。デフォルトでは値が設定されておらず検証は行われません。 このオプションが設定されていない場合においても、
ssl_ca_cert_dirオプション が設定されている場合には検証が行われます。 - ssl_ca_cert_dir
-
PEM 形式の CA 証明書ファイルを格納しているディレクトリのパスを指定します。 これらのファイルはバックエンドサーバ認証の検証に用いられます。 このオプションは OpenSSL の
verify(1)コマンドにおける-CApathオプションと同様の機能を提供します。デフォルトでは値が設定されておらず検証は行われません。 このオプションが設定されていない場合においても、
ssl_ca_certオプション が設定されている場合には検証が行われます。
Other
- relcache_expire V3.1 〜
-
リレーションキャッシュの寿命を秒単位で指定します。 0を指定すると、キャッシュの寿命の管理は行わず、プロセスが生きているか、 キャッシュが溢れるまでは有効になります(デフォルトの動作)。
リレーションキャッシュは、PostgreSQLのシステムカタログに対する問い合わせを保存しておくものです。 問い合わせる内容は、テーブルの構造、テーブルが一時テーブルかどうかなどがあります。 キャッシュはpgpoolの子プロセスのローカルメモりに保管されています。
もしALTER TABLEが発行されると、テーブルの構造が変わる場合があり、 リレーションキャッシュの内容と一致しなくなる恐れがあります。 relcache_expireにより、その危険性をコントロールできるようになります。
- relcache_size V3.2 〜
-
リレーションキャッシュのサイズを指定します。 デフォルトは256です。
"pool_search_relcache: cache replacement happend"
のようなメッセージがログに頻繁に出る場合は、この数字を大きくしてください。
- check_temp_table V3.2 〜
-
もしonなら、SELECTに含まれるテーブルが一時テーブルかどうかのチェックを行います。 このチェックは、primary/masterのシステムカタログへのアクセスを発生させ、それなりに負荷を上げます。 もし一時テーブルを使っていないということが確かで、primary/masterの負荷を少しでも下げたいのであれば、 offにすることができます。デフォルトはonです。
SSL証明書の生成
証明書の扱いについてはこのマニュアルの範囲外です。 PostgreSQLドキュメント SSLによる安全なTCP/IP接続の章に自分で認証する証明書を作成するコマンドの例があります。
rawモードにおけるフェイルオーバ動作について
rawモードにおいて、2台以上のPostgreSQLサーバを指定すると、フェイルオーバが可能です。 フェイルオーバでは、正常時にはbackend_hostname0で指定したPostgreSQLのみを使用し、 ほかのサーバにはアクセスしません。 backend_hostname0のサーバがダウンすると、次にbackend_hostname1で指定したサーバにアクセスをこころみ、 成功すればそれを使用します。以下、backend_hostname2...でも同様になります。
コネクションプールモード
rawモードに加え、コネクションプーリングが利用できるようになります。 コネクションプールモードを有効にするには、 connection_cache をonにします。 以下の設定項目がコネクションプールの動作に影響を与えます。
- max_pool
-
pgpool-IIの各サーバプロセスがキープするPostgreSQLへの最大コネクション数です。 pgpool-IIは、ユーザ名、データベースが同じならばコネクションを再利用しますが、 そうでなければ新たにPostgreSQLへのコネクションを確立しようとします。 したがって、ここでは想定される[ユーザ名:データベース名]のペアの種類の数だけを max_poolに指定しておく必要があります。 もしmax_poolを使いきってしまった場合は一番古いコネクションを切断し、 そのスロットが再利用されます。
max_poolのデフォルト値は4です。
なお、pgpool-II全体としては、num_init_children * max_pool 分だけ PostgreSQLへのコネクションが張られる点に注意してください。
このパラメータを変更した時には pgpool-II を再起動してください。
- connection_life_time
-
コネクションプール中のコネクションの有効期間を秒単位で指定します。 0を指定すると有効期間は無限になります。 connection_life_timeのデフォルト値は0です。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- reset_query_list
-
セッションが終了するときにコネクションを初期化するためのSQLコマンドを「;」で区切って列挙します。 デフォルトは以下のようになっていますが、任意のSQL文を追加しても構いません。
reset_query_list = 'ABORT; DISCARD ALL'
PostgreSQLのバージョンによって使用できるSQLコマンドが違います。 各バージョンごとのお勧め設定は以下です(ただし、"ABORT"は必ずコマンドに含めてください)。
PostgreSQLバージョン reset_query_listの推奨設定値 7.1以前 ABORT 7.2から8.2 ABORT; RESET ALL; SET SESSION AUTHORIZATION DEFAULT 8.3以降 ABORT; DISCARD ALL - 「ABORT」は、PostgreSQL 7.4以上ではトランザクションブロックの中にいない場合には発行されません。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
コネクションプールモードにおけるフェイルオーバ動作について
rawモードと同様の動作をします。
レプリケーションモード
レプリケーションを有効にするモードです(設定ファイルの雛形はpgpool.conf-replication)。 rawモード、コネクションプールモードに加え、以下を設定します。
- replication_mode
-
レプリケーションモードで動作させる場合はtrueを指定してください。デフォルト値はfalseです。
このパラメータを変更した時には pgpool-II を再起動してください。
- load_balance_mode
-
trueを指定するとレプリケーションモードまたはマスタースレーブモードの際に、 SELECT文をロードバランスして検索性能を向上させることができます。デフォルト値はfalseです。
このパラメータを変更した時には pgpool-II を再起動してください。
- replication_stop_on_mismatch
-
各DBノードから送られてくるパケットの種類が不一致になった場合に、DBノードを切り放して縮退運転に入ります。
良くあるケースとしては、replicate_select が指定されていて SELECTが各DBノードで実行されているときに、 検索結果行数が一致しないなど、があります(これに限定されるものではありません。 たとえばあるDBノードでUPDATEが成功したのに、他のDBノードでは失敗した場合が一例です)。 ただし、pgpoolはパケットの中身まではチェックしていないので、SELECT結果のデータ内容が異なっていても、 縮退は起きないことに注意してください。
縮退対象のDBノードは「多数決」で少数派になったものが対象になります。 もし多数決で同票になった場合は、マスタDBノード(DBノード番号がもっともわかいもの)を含むグループが優先され、 それ以外のグループに所属するDBノードが切り放しの対象になります。
このオプションがfalseの場合は、該当のセッションを強制的に終了するだけに留めます。 デフォルト値はfalseです。
- failover_if_affected_tuples_mismatch V3.0 〜
-
各DBノードで実行されたINSERT/UPDATE/DELETEの結果行数が不一致になった場合に、 DBノードを切り放して縮退運転に入ります。
縮退対象のDBノードは「多数決」で少数派になったものが対象になります。 もし多数決で同票になった場合は、マスタDBノード(DBノード番号がもっともわかいもの)を含むグループが優先され、 それ以外のグループに所属するDBノードが切り放しの対象になります。
このオプションがfalseの場合は、該当のセッションを強制的に終了するだけに留めます。 デフォルト値はfalseです。
- white_function_list V3.0 〜
-
データベースに対して更新を行なわない関数名をコンマ区切りで指定します。 このリストに含まれない関数呼び出しを含むSELECTは、負荷分散の対象とはならず、 レプリケーションモードにおいてはすべてのDBノードで実行されます。 (マスタースレーブモードにおいては、マスター(primary)DBノードにのみ送信されます)。
関数名には正規表現を使うことができます。指定した各表現に ^ と $ をつけた形で使われます。 たとえば、読み出しのみの関数が"get_"あるいは"select_"で始まるならば、以下のような指定が可能です。
white_function_list = 'get_.*,select_.*'
- black_function_list V3.0 〜
-
データベースに対して更新を行なう関数名をコンマ区切りで指定します。 このリストに含まれる関数呼び出しを含むSELECTは、負荷分散の対象とはならず、 レプリケーションモードにおいてはすべてのDBノードで実行されます。 このリストに含まれない関数呼び出しを含むSELECTは、負荷分散の対象となります。
関数名には正規表現を使うことができます。指定した各表現に ^ と $ をつけた形で使われます。 たとえば、読み出しのみの関数が"set_"、"update_"、"delete_"あるいは"insert_"で始まるならば、 以下のような指定が可能です。
black_function_list = 'nextval,setval,set_.*,update_.*,delete_.*,insert_.*'
white_function_listとblack_function_listの両方を空以外にすることはできません。 どちらか一方のみに関数名を指定します。
pgpool-II 3.0より前のバージョンでは、固定でnextvalとsetvalが書き込みを行なう関数として認識されていました。 それと同じ動作を行なわせるには、以下のようにwhite_function_listとblack_function_listを指定します。
white_function_list = '' black_function_list = 'nextval,setval,lastval,currval'
上の例では、nextvalとsetvalに加え、lastvalとcurrvalが追加されていることに注意してください。 lastvalとcurrvalは書き込みを行う関数ではありませんが、これらの関数が負荷分散されることによって、 エラーが発生するのを未然に防ぐことができます。 black_function_listに含まれる関数は負荷分散されないからです。
- replicate_select
-
true を設定すると、レプリケーションモードでは SELECT 文をレプリケーションします。 これは pgpool-II 1.0 までの挙動と同じになります。 false を設定すると SELECT 文をマスタのみに送信します。デフォルト値は false です。
replicate_select、load_balance_mode、 SELECT問合わせが明示的なトランザクションブロックの内側にあるかどうかどうかで、 レプリケーションモードの動作が変化します。詳細を表に示します。
SELECTが明示的なトランザクションブロックの内側にある Y Y Y N N N Y N replicate_selectがtrue Y Y N N Y Y N N load_balance_modeがtrue Y N N N Y N Y Y 結果(R:レプリケーション, M: マスタのみに送信, L: ロードバランスされる) R R M M R R M L - insert_lock
-
SERIAL型を使っているテーブルをレプリケーションすると、SERIAL型の列の値がDBノードの間で 一致しなくなることがあります。 この問題は、該当テーブルを明示的にロックすることで回避できます (もちろんトランザクションの並列実行性は犠牲になりますが)。 しかし、そのためには、
INSERT INTO ...
を
BEGIN; LOCK TABLE ... INSERT INTO ... COMMIT;
に書き換えなければなりません。 insert_lockをtrueにすると自動的にトランザクションの開始、テーブルロック、トランザクションの終了を 行ってくれるので、こうした手間を省くことができます (すでにトランザクションが開始されている場合はLOCK TABLE...だけが実行されます)。
- pgpool-II 2.2以降
テーブルがSERIAL列を持つかどうか自動判別するため、 SERIAL列がなければ決してテーブルをロックしません。
- pgpool-II 3.0.4までの3.0シリーズ
対応するシーケンステーブルに対して行ロックをかけることで排他制御を行ないます。 それ以前のバージョンと比べると、VACUUM(autovacuumを含む)とのロック競合がなくなるメリットがあります。
しかし、これは他の問題を引き起こします。 トランザクション周回が起きた後、シーケンステーブルに対する行ロックはPostgreSQLの内部エラー (詳細には、トランザクション状態を保持するpg_clogへのアクセスエラー)を起こします。 これを防ぐため、PostgreSQLのコア開発者はシーケンステーブルに対する行ロックを許可しないことを決定しました。 これはもちろんpgpool-IIを動作不能にします(修正されたPostgreSQLはバージョン 9.0.5, 8.4.9, 8.3.16そして8.2.22としてリリースされるでしょう)。
- pgpool-II 3.0.5以降
新しいPostgreSQLがシーケンステーブルに対するロックを許可しなくなったため、 pgpool_catalog.insert_lockテーブルに対して行ロックをかけることで排他制御を行ないます。 したがって、pgpool-II経由でアクセスするすべてのデータベースにinsert_lockテーブルを あらかじめ作成しておく必要があります。 詳細はinsert_lockテーブルの作成の項目をご覧ください。
もし、insert_lockテーブルが存在しない場合は、挿入対象のテーブルに対してロックを行います。 これは、pgpool-II 2.2と2.3シリーズのinsert_lockと同じ動作です。 また、過去のバージョンと互換性のあるinsert_lockを使用したい場合は、configureスクリプトで設定できます。 詳細はconfigureの実行の項目をご覧下さい。
なお、あまり必要ないかも知れませんが、コメントを利用して、この挙動を細かく制御することもできます。
- insert_lockをtrueにして、INSERT文の先頭に/*NO INSERT LOCK*/コメントを追加する。 このコメントがあると、テーブルロックは行われません(pgpool-II 3.0以降でも同様)。
- insert_lockをfalseにして、INSERT文の先頭に/*INSERT LOCK*/コメントを追加する。 このコメントがあると、このINSERT文に対してのみテーブルロックが行われます(pgpool-II 3.0以降でも同様)。
insert_lockのデフォルト値はtrueです。
なお、insert_lockを有効にしてregression testを実行すると、少くともPostgreSQL 8.0では transactions, privileges, rules, alter_tableがfailします。 ruleでは、viewに対してLOCKをしようとしてしまうこと、ほかのものは
! ERROR: current transaction is aborted, commands ignored until end of transaction block
というようなメッセージが出てしまうためです。たとえば、transactions では、 存在しないテーブルに対してINSERTを行うテストが含まれており、 pgpoolが最初に存在しないテーブルに対してLOCKを行う結果、エラーになってトランザクションがアボート状態になり、 続くINSERTで上記エラーが出てしまいます。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- recovery_user
-
オンラインリカバリを行うための PostgreSQL ユーザ名です。 このパラメータを変更した時には設定ファイルを再読み込みしてください。
- recovery_password
-
オンラインリカバリを行うための PostgreSQL ユーザパスワードです。 このパラメータを変更した時には設定ファイルを再読み込みしてください。
- recovery_1st_stage_command
-
オンラインリカバリ中に起動するコマンド名を指定します。 このスクリプトはPostgreSQLのマスタサーバ(プライマリサーバ)が起動します。 コマンドファイルはセキュリティ上の観点からデータベースクラスタ以下にある コマンドやスクリプトのみを呼び出します。 例えば、recovery_1st_stage_command = 'sync-command' と設定してある場合、 $PGDATA/sync-command を起動しようとします。
recovery_1st_stage_command は次の3つの引数を受けとります。
- マスタ(プライマリ)データベースクラスタへのパス
- リカバリ対象のPostgreSQLのホスト名
- リカバリ対象のデータベースクラスタへのパス
recovery_1st_stage_command を実行している間は pgpool ではクライアン トからの接続を制限しません。参照や更新を行うことができます。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- recovery_2nd_stage_command
-
2 回目のオンラインリカバリ中に起動するコマンド名を指定します。 このスクリプトはPostgreSQLのマスタサーバ(プライマリサーバ)が起動します。 コマンドファイルはセキュリティ上の観点からデータベースクラスタ以下にある コマンドやスクリプトのみを呼び出します。 例えば、recovery_2nd_stage_command = 'sync-command' と設定してある場合、 $PGDATA/sync-command を起動しようとします。
recovery_2nd_stage_command は次の3つの引数を受けとります。
- マスタ(プライマリ)データベースクラスタへのパス
- リカバリ対象のPostgreSQLのホスト名
- リカバリ対象のデータベースクラスタへのパス
recovery_2nd_stage_command を実行している間は pgpool ではクライアントから 接続、参照、更新処理を一切受け付けません。 また、バッチ処理などによって接続しているクライアントが長時間存在している場合にはコマンドを起動しません。 新たな接続を制限し、現在の接続数が 0 になった時点 でコマンドを起動します。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- recovery_timeout
-
pgpoolは、オンラインリカバリの際にすべてのクライアントが接続を終了するまで待ちます。 recovery_timeoutでその最大待ち時間を指定します。単位は秒です。 待ち時間がrecovery_timeoutを越えると、オンラインリカバリは中止され、通常の状態に戻ります。
アイドル状態のクライアントが自分から切断するのを待ちたくない場合は、 client_idle_limit_in_recoveryを利用することもできます。
recovery_timeoutは、この他、オンラインリカバリの最後にリカバリ対象のDBノードで postmasterを起動する際の待ち時間にも利用されます。
recovery_timeoutのデフォルト値は90秒です。 recovery_timeoutを0としてもタイムアウトが無効になるわけではなく、 単に即座にタイムアウトするだけですので注意してください。 このパラメータを変更した時には設定ファイルを再読み込みしてください。
- client_idle_limit_in_recovery V2.2 〜
-
client_idle_limitと似ていますが、このパラメータはリカバリのセカンドステージでのみ効力があります。 前回クライアントから来たクエリから、client_idle_limit_in_recovery 秒越えても次のクエリが届かない場合は、 クライアントへの接続を強制的に切断し、リカバリのセカンドステージの進行が妨害されるのを防ぎます。 -1を指定すると、直ちにクライアントへの接続を切断してセカンドステージに入ります。 デフォルト値は 0(無効)です。
クライアントが忙しく、アイドル状態にならない場合はclient_idle_limit_in_recoveryを設定しても セカンドステージに移行できません。 この場合、client_idle_limit_in_recoveryに-1を設定すると、クライアントがビジーであっても ただちにクライアントへの接続を切断し、セカンドステージに移行することができます。
このパラメータを変更した時には設定ファイルを再読み込みしてください。
- lobj_lock_table V2.3 〜
-
ラージオブジェクトのレプリケーションを行いたいときにロック管理に使うためのテーブル名を指定します。 このテーブルが指定されていて、ラージオブジェクトの作成要求がクライアントから送信され、 かつその要求の中にラージオブジェクトのIDの明示的な指定が含まれていない場合 (つまり、lo_creatでラージオブジェクトを作成する場合)、 pgpool-IIは、排他制御のためにこのテーブルをロックした後、 ラージオブジェクトを格納するシステムカタログpg_largeobjectのラージオブジェクトに格納されている IDの最大値を取りだし、その値+1のIDを使ってlo_create()を呼び出してラージオブジェクトの作成を行います (lo_create()を持たないバージョン8.1より前のPostgreSQLではこの処理は行われません)。 この方法により、すべてのDBノードで同じIDを持つラージオブジェクトが作成されることが保証されます。
このような処理の対象となるラージオブジェクトの操作は、PostgreSQLのC言語用のAPI(libpq)で言うと、lo_creat()です。 2010年2月時点の我々の調査では、以下の言語のラージオブジェクト作成APIは、すべてlo_creat()を呼び出すか、 またはlo_creat()と同じ通信プロトコルを使っているので、pgpool-IIの上記の操作の対象になり、 ラージオブジェクトのレプリケーションが安全に行われるようになります。
- Java(JDBCドライバ)
- PHP(pg_lo_create関数、またはPDOなどの該当API)
- psqlから\lo_importを呼び出す場合
上記以外であっても、ラージオブジェクトの作成APIで ラージオブジェクトのIDを引数として渡すようになっていないものは 間違いなくlo_creat()を使っており、pgpool-IIの上記の操作の対象になると考えて良いでしょう。
pgpool-IIの上記処理の対象とならないようなラージオブジェクトの作成処理は以下のものです。
- libpqのlo_create()を使用している
- C言語以外のAPIで、lo_create()を使用しているもの
- バックエンド関数のlo_importをSELECTで呼び出す場合
- バックエンド関数のlo_creatをSELECTで呼び出す場合
lobj_lock_tableで指定するテーブルはどのような定義のものでも構いませんが、 あらかじめ作成済でかつすべてのユーザが書き込み可能でなければなりません。 そのようなテーブルを作る例を示します。
CREATE TABLE public.my_lock_table (); GRANT ALL ON public.my_lock_table TO PUBLIC;
この操作はpgpool-II経由で接続するすべてのデータベースに対して、あらかじめ実施しておかなければなりません。 しかし、この操作をtemplate1データベースに対して一度行っておけば、 以後作成されるデータベースにはこのテーブルが含まれるようになるので、管理の手間が省けます。
lobj_lock_tableに指定するテーブル名が空文字の場合は、ラージオブジェクトに関する上記の処理は行いません (したがって、ラージオブジェクトのレプリケーションは保証されません)。 lobj_lock_tableのデフォルト値は空文字です。
ロードバランスの条件について
load_balance_mode = true を設定した場合、以下の条件のすべてを満たした時に SELECTなどの問い合わせがロードバランスされます。
- PostgreSQLのバージョンが7.4以降である
- レプリケーションモードまたはマスタースレーブモードである
- 問い合わせが明示的なトランクザションブロックの内側にない(つまり、BEGINを発行していない)
- SELECT文(WITH付も含む。black_list または white_list で指定された書き込みを含むSELECTを除く) またはCOPY TO STDOUT, EXPLAIN, EXPLAIN ANALYZE SELECT... のいずれかである
- SELECT INTO 文ではない
- SELECT FOR UPDATE/SELECT FOR SHARE文ではない
- クエリ文字列が SELECTまたはWITH で始まる(ignore_leading_white_space = trueの場合は空白は無視します)
- マスタースレーブモードの場合、更に以下の条件が満たされなければなりません。V3.0 -
- 一時テーブルを使っていない
- unloggedテーブルを使っていない
- システムカタログを使っていない
- トランザクションブロックの内側であっても上記条件と下記条件を満たせばロードバランスされます。
- トランザクション分離レベルがSERIALIZABLEでない
- トランザクション内で更新を伴うクエリが実行されていない(更新を伴うクエリが実行されるまではロードバランスされます)
(replicate_selectの項目も参考にしてください) また、詳細な判定条件をフローチャートにしたものもご覧下さい。
なお、
/*REPLICATION*/ SELECT ...
とすることによって、本来負荷分散されたり、マスタのみに送信されるべき問合わせが すべてのバックエンドに送信される(レプリケーションされる)ようになります。 副作用がある関数を含む問合わせに対してはこのテクニックが利用できます。
注意: JDBC ドライバなどのように、ドライバ内で autocommit の有効・無効のオプションがある場合、 autocommit を無効にすると、ドライバが内部で BEGIN コマンドを実行する関係上、 正しくロードバランスされない可能性があります。 クエリをロードバランスさせたい場合は autocommit を有効にしてください。 たとえばJDBCであれば setAutoCommit(true) を実行してください。
レプリケーションモードにおける縮退運転について
PostgreSQLサーバのうち、1台がダウンすると、そのサーバを切り離して縮退運転に入ります。 1台でもサーバが生き残っていれば、システムとしての運用を継続できます。
レプリケーションモード固有のエラーについて
レプリケーションモードにおいて、pgpoolはレプリケーション時に INSERT、UPDATE、DELETE の更新件数が すべてのノードが同じでない場合、 failover_if_affected_tuples_mismatch が falseならば、 意図的に構文エラーを起すSQLを送信することによって、トランザクションをアボートさせます。 trueならば、フェイルオーバが起きます。その際、以下のようなエラーメッセージが表示されます。
=# UPDATE t SET a = a + 1; ERROR: pgpool detected difference of the number of update tuples Possible last query was: "update t1 set i = 1;" HINT: check data consistency between master and other db node
ログには更に以下のように、更新行数が記録されます(この場合はDBノード0が0行、DBノード1が1行)。
2010-07-22 13:23:25 LOG: pid 5490: SimpleForwardToFrontend: Number of affected tuples are: 0 1 2010-07-22 13:23:25 LOG: pid 5490: ReadyForQuery: Degenerate backends: 1 2010-07-22 13:23:25 LOG: pid 5490: ReadyForQuery: Number of affected tuples are: 0 1
マスタースレーブモード
master/slaveモードは、Slony-IやStreaming Replicationのような、 master/slave式のレプリケーションソフトにレプリケーションをまかせるモードです。 このモードで使うためには、レプリケーションモードと同じように、 DBノードのホスト情報(backend_hostname, backend_port, backend_weight, backend_flag それにオンラインリカバリが必要ならば backend_data_directory)をセットし、 master_slave_modeとload_balance_modeをtrueにします。
pgpool-IIは、レプリケーションされる必要のある問い合わせはマスターに送り、 その他の問い合わせを可能ならば負荷分散します。問い合わせによってマスターDBだけに問い合わせが送られる場合と、 DBノードの間でロードバランスされて問い合わせが送られる場合があります。
マスタスレーブモードでは、一時テーブルの作成、更新、検索はマスタノードでのみ実行されます。 SELECTをマスタだけで実行するように強制することができます。 このためには、/*NO LOAD BALANCE*/ コメントをSELECTに前に挿入しなければなりません。
マスタースレーブモードでは、pgpool.confのreplication_modeをfalseに、 master_slave_mode をtrueにします(同時にtrueにはできません)。 また、'master_slave_sub_mode'を指定します。 これは、'slony'(デフォルト)か、'stream'です。
'slony'はSlony-Iを利用する時に指定します。 'stream'は、PostgreSQL組み込みのStreaming Replicationを利用するときに指定します。
Slony-Iを使う場合の設定ファイルの雛形はpgpool.conf.sample-master-slaveです。 Streaming Replicationを使う場合の雛形はpgpool.conf.sample-streamです。
このパラメータを変更した時には pgpool-II を再起動してください。
マスタースレーブモードでも、DB書き込みを行なう関数の呼び出しを含むSELECTを負荷分散の対象から外す指定を white_function_listと black_function_listで行なうことができます。 詳細はwhite_function_listの項をご覧下さい。
Streaming Replicationへの対応 V3.1 〜
前述のように、マスタスレーブモードで、'master_slave_sub mode'に 'stream'を指定すると、PostgreSQL 9.0から利用可能になったStreaming Replicationに対応します (pgpool-IIでは、今のところ、Streaming ReplicationとHot Standbyを併用することを前提にしています)。 このモードでは、以下の設定項目も利用できます。
- delay_threshold V3.0 〜
-
スタンバイサーバへのレプリケーションの遅延許容度をバイト単位で指定します。 pgpool-IIは、スタンバイサーバの遅延がこの値を超えた場合には、 負荷分散が有効であってもそのDBノードにSELECTを送信せず、プライマリサーバに送るようにします。 delay_thresholdが0の場合は、遅延のチェックを行ないません。 また、delay_thresholdが指定されていても、sr_check_periodが無効(=0)ならば、 やはりこの機能は働きません。 デフォルト値は0です。
このパラメータは設定ファイルの再読込によって変更できます。
- sr_check_period V3.1 〜
-
ストリーミングレプリケーションの遅延チェックの間隔を秒単位で指定します。 デフォルト値は0で、これはチェックを行わないことを意味します。
このパラメータは設定ファイルの再読込によって変更できます。
- sr_check_user V3.1 〜
-
ストリーミングレプリケーションの遅延チェックを行うユーザ名を指定します。 このユーザは、すべてのバックエンドに存在しなければなりません。 さもなければエラーになります。 sr_check_userとsr_check_passwordは、sr_check_periodが0であっても 指定が必要です。pgpool-IIは、どのサーバがprimaryサーバであるのかを調べるために、 PostgreSQLバックエンドに関数呼び出しのリクエストを送ります。 そのセッションでsr_check_userとsr_check_passwordが使われるからです。
このパラメータは設定ファイルの再読込によって変更できます。
- sr_check_password V3.1 〜
-
ストリーミングレプリケーションの遅延チェックを行うユーザに対するパスワードをを指定します。 パスワードが必要なければ空文字('')を指定します。
このパラメータは設定ファイルの再読込によって変更できます。
- log_standby_delay V3.0 〜
-
レプリケーションの遅延状況をログする条件を指定します。 'none'を指定すると、ログを出力しません。 'always'ならヘルスチェックを実行するたびに必ず出力します。 'if_over_threshold'を指定すると、delay_thresholdを超えたときだけ ログが出力されます。 デフォルト値は'none'です。
このパラメータは設定ファイルの再読込によって変更できます。
なお、レプリケーションの遅延状況は show pool_status コマンドでも確認できます。 項目名は"standby_delay#"です(#はDBノードIDです)。
Streaming Replicationでのフェイルオーバ
Streaming replicationを利用したマスタスレーブモードでは、PrimaryやStandbyノードが停止した場合に、 レプリケーションモードと同じように自動フェイルオーバを行なわせることができます。 特に何も設定しなくても、停止したノードを自動的に切り放すことができますが、Streaming replicationでは、 「トリガファイル」を作成することにより、Standbyノードを、リカバリモードから更新問い合わせを受け付ける 通常のPostgreSQLの動作モードに自動変更することができます。 これを利用して、フェイルオーバコマンドを併用して、Primaryノードがダウンしたときに、 Standbyノードが自動的にとって代るような設定を行なうことができます。
注意: 複数のStandbyノードを利用している場合、この設定を行なうときは、 delay_thresholdを設定して、 他のStandbyに振り分けられたSELECTが古いデータを取得しないようにしておくことをお勧めします。 また、1台目のStandbyノードがPrimaryにとって代ったのちにダウンしてしまったケースで、 2台目のStandbyが更に取って代わるとデータに不整合がおきるので、そのような設定は行なわないようにしてください。
フェイルオーバの設定手順を示します。
- フェイルオーバ用のスクリプトを適当な場所(ここでは/usr/local/pgsql/bin)に配置して、実行権限を与えておきます。
$ cd /usr/loca/pgsql/bin $ cat failover_stream.sh #! /bin/sh # Failover command for streming replication. # This script assumes that DB node 0 is primary, and 1 is standby. # # If standby goes down, does nothing. If primary goes down, create a # trigger file so that standby take over primary node. # # Arguments: $1: failed node id. $2: new master hostname. $3: path to # trigger file. failed_node=$1 new_master=$2 trigger_file=$3 # Do nothing if standby goes down. if [ $failed_node = 1 ]; then exit 0; fi # Create trigger file. /usr/bin/ssh -T $new_master /bin/touch $trigger_file exit 0; chmod 755 failover_stream.sh - pgpool.confの、failover_commmandを設定します。
failover_command = '/usr/local/src/pgsql/9.0-beta/bin/failover_stream.sh %d %H /tmp/trigger_file0'
- standbyノードのrecovery.confを設定します。
recovery.confのサンプルは PostgreSQLのインストールディレクトリ下の
"share/recovery.conf.sample"にあります。
これをstanndbyノードのデータベースクラスタ下に"recovery.conf"としてコピーしておきます。
そして、以下の項目を設定します。
standby_mode = 'on' primary_conninfo = 'host=primary_hostのホスト名 user=postgres' trigger_file = '/tmp/trigger_file0'
- primaryノードのpostgresql.confを設定します。
以下は例ですので、必ず実際に合わせて調整してください。
wal_level = hot_standby max_wal_senders = 1
- primaryノードのpg_hba.confを設定します。
以下は例ですので、必ず実際に合わせて調整してください。
host replication postgres 192.168.0.10/32 trust
primaryとstandbyのPostgreSQLを起動すれば、Streaming replicationが開始されます。 そして、primaryノードがダウンしたときに、自動的にstandbyノードが通常のPostgreSQLとして立ち上がり、 更新問い合わせを受け付けるようになります。
Streaming Replicationでのクエリ振り分け
Streaming replicationとHot Standbyを利用している環境では、primaryノードに送ってよい問い合わせ、 standbyに送ってもよい問い合わせ、両方に送らなければならない問い合わせを厳密に管理する必要があります。 pgpool-IIのStreaming Replicationモードは、こうした振り分けを自動的に行ないます。 ここでは、そのロジックについて説明します。
まず、問い合わせの種類によって以下のように分けられます。
- Primaryノードにしか送られない問い合わせ
- INSERT, UPDATE, DELETE, COPY FROM, TRUNCATE, CREATE, DROP, ALTER, COMMENT
- SELECT ... FOR SHARE | UPDATE
- トランザクションの分離レベルがシリアライザブルの場合のSELECT
- ROW EXCLUSIVE MODEよりも強いLOCK
- トランザクションコマンドの一部
- BEGIN READ WRITE, START TRANSACTION READ WRITE
- SET TRANSACTION READ WRITE, SET SESSION CHARACTERISTICS AS TRANSACTION READ WRITE
- SET transaction_read_only = off
- 二相コミット関連のコマンド。PREPARE TRANSACTION, COMMIT PREPARED, ROLLBACK PREPARED
- LISTEN, UNLISTEN, NOTIFY
- VACUUM
- シーケンス関連の関数(nextvalやsetvalなど)の呼び出し。
- ラージオブジェクトの生成
- Primary/Standbyどちらにも送ることのできる問い合わせ。
負荷分散設定が有効ならば、standbyノードにも送信されます。 ただし、レプリケーションの遅延上限(delay_threshold)が設定されていて、 レプリケーションの遅延がdelay_thresholdを上回っている場合は 問い合わせはPrimaryに送られます。
- 上記以外のSELECT
- COPY TO
- DECLARE, FETCH, CLOSE
- SHOW
- Primary/Standbyどちらにも送られる問い合わせ
- SET
- DISCARD
- DEALLOCATE ALL
明示的なトランザクションでは、以下のようになります。
- BEGINなどのトランザクション開始コマンドは、Primaryサーバに送られます。
- 続くSELECTなど、Primary/Standbyどちらにも送ることのできる問い合わせは、 Primaryのトランザクション内でそのまま実行されるか、Standbyサーバで実行されます。
- INSERTなど、Standbyに送ることのできない問い合わせが現われた場合は、Primaryサーバで実行されます。 以後、SELECTなど、本来Standbyに送信しても構わないコマンドもPrimaryサーバで実行されます。 これは、トランザクションの中で実行されたINSERTなどの問い合わせの結果を SELECTが直ちに参照できるようにするためです。 この状態は、トランザクションが閉じるか、アボートするまで続きます。
問い合わせが、拡張問い合わせモードで実行される場合は、問い合わせのparse段階で、 問い合わせが負荷分散可能かどうかで送信先が決まります。 その際の判断ルールは、通常のSQLと同じです。 たとえば問い合わせがINSERTならば、Primaryサーバで実行される、という具合です。 parseに続くbind, describe, executeも同じDBノードで実行されます。
[注: SELECTが負荷分散されて Standby ノードで parseが実行されてから更新クエリが来た場合は、 そのSELECTはPrimaryノードで実行されなければなりません。 そのため、同じSELECTが再度Primaryノードでパースされることになります。]
最後に、pgpool-IIのパーサが構文エラーと判断した問い合わせはPrimaryノードだけに送られます。
Streaming Replicationでのオンラインリカバリ
Streaming replicationを利用したマスタスレーブモードでは、 レプリケーションモードと同じようにオンラインリカバリが利用できます。 primaryサーバをマスタとし、standbyサーバをリカバリします。 primaryサーバが動作しているのがこの方法の前提条件ですので、 primaryサーバが停止している状態ではオンラインリカバリはできません。 primaryサーガ停止している状態からの復旧は、すべてのDBノードとpgpool-IIを停止させて手動で実施しなければなりません。
- リカバリ処理を実行するユーザ recovery_user を設定します。
通常、postgresユーザとなります。
recovery_user = 'postgres'
- recovery_password を設定します。
これは、recovery_user がDBにログインするときに使うパスワードです。
recovery_password = 't-ishii'
- recovery_1st_stage_command を設定します。
ここで指定するファイルは、primaryサーバからベースバックアップを取得し、 standbyサーバにリストアするものでなければなりません。 recovery_1st_stage_command は、primaryのPostgreSQLから、recovery_userの権限で起動され、 その時に引数を受けとります。 詳細は、recovery_1st_stage_commandの設定項目をご覧ください。
このスクリプトファイルは、primaryのデータベースクラスタ下に配置し、実行権限を与えておきます。 サンプルとして、primary/standbyそれぞれ一台構成の場合のスクリプト (basebackup.sh)を示します。 このスクリプトでは、recovery_user がパスワードなしでリカバリ対象の standbyノードにログインできることを前提にしているので、 あらかじめsshの設定を行なっておく必要があります。
recovery_1st_stage_command = 'basebackup.sh'
- recovery_2nd_stage_command は、空のままで構いません。
recovery_2nd_stage_command = ''
- オンラインリカバリを実施するための PostgreSQL の C 言語関数やSQL関数を各DBノードにインストールします。
# cd pgpool-II-x.x.x/sql/pgpool-recovery # make # make install # psql -f pgpool-recovery.sql template1 - オンラインリカバリが終了したあと、pgpool-IIは、停止していたDBノードのPostgreSQLを起動します。
そのためのスクリプトを、各DBノードのDBクラスタにインストールします。
スクリプトのサンプルがソースコードの"sample"ディレクトリに含まれているので、 それを利用してください。 このサンプルの中では、PostgreSQLの起動をpg_ctlコマンドで行っており、pg_ctlコマンドへのパスが記述されています。 デフォルトでは/usr/local/pgsql/bin/pg_ctlとなっているので、お使いの環境に合わせて修正してください。
なお、このスクリプトはsshを使用しますので、少くとも、primaryのDBノードから、standbyのDBノードに対して、 recovery_userでパスワードなしでsshが利用できることが必要です。 必要ならばあらかじめ設定しておいてください。
以上でオンラインリカバリの設定が終了しました。 standbyノードを停止した状態で、pcp_recovery_node を利用するか、 pgpoolAdminの「リカバリ」ボタンでオンラインリカバリが出来るようになったはずです。 うまくいかない場合は、pgpool-IIのログ、primaryサーバ、standbyサーバのログを確認してください。
参考までに、ストリーミングレプリケーションでのオンラインリカバリの内部処理の流れを説明します。
- pgpool-IIは、primaryサーバにユーザ: recovery_user, パスワード: recovery_password で template1データベースに接続します。
- primaryサーバで、pgpool_recovery関数を実行します。
- pgpool_recovery関数は、recovery_1st_stage_command で
指定されたスクリプトを実行します。
なお、PostgreSQLは、データベースクラスタディレクトリ中で関数を実行します。 よって、pgpool_recovery関数もprimaryサーバのデータベースクラスタディレクトリ中で 関数を実行されることに注意してください。
- primaryサーバで、pgpool_remote_start関数を実行します。
この関数は、primaryサーバのデータベースクラスタディレクトリ中にある pgpool_remote_startという名前のスクリプトを起動し、 ここからssh経由でリカバリ対象のstandbyサーバのPostgreSQLをpg_ctlコマンドを使って起動します。 起動はバックグラウンドで行われ、起動できたかどうかは次のステップで確認されます。
- pgpool-IIから、standbyサーバのPostgreSQLのpostgresデータベース
(postgresデータベースがない場合はtemplate1データベース)に、
ユーザ: recovery_user,
パスワード: recovery_password でtemplate1データベースに接続を試みます。
リトライは、recovery_timeout秒間行われます。 PostgreSQLの起動に成功したら、次のステップに移ります。
- failback_commandが空でない場合は、 pgpool-IIの親プロセスは指定されたスクリプトを起動します。
- failback_commandが終了したら、pgpool-IIの子プロセスをすべて再起動します。
パラレルモード
パラレルクエリ機能が利用できるモードです。 テーブルを分割させ、各ノードにデータを持たせることができます。またレプリケーションや負荷分散機能も同時に使うことができます。
パラレルモードでは、pgpool.confのreplication_modeまたは loadbalance_modeにtrueを設定し、 master_slave をfalseにし、 parallel_mode をtrueにします。 このパラメータを変更した時には pgpool-II を再起動してください。
システムDBの設定
パラレルモードを利用するためには、システムDBを設定する必要があります。 システムDBはデータを各PostgreSQLサーバで分割するためのルールをPostgreSQLのテーブルの形で保持します。 システムDBはpgpoolが動作するホストと同じホストに置く必要はありません。 システムDBの設定はpgpool.confで行います。
- system_db_hostname
-
システムDBが動いているホスト名です。空文字を指定すると、UNIXドメインソケットで接続します。
このパラメータを変更した時には pgpool-II を再起動してください。
- system_db_port
-
システムDBのポート番号です。
このパラメータを変更した時には pgpool-IIを再起動してください。
- system_dbname
-
システムDBは専用のデータベースに設置します。そのデータベース名を指定します。 このデータベースはあらかじめ存在しなければなりません。ここでは、 "pgpool"というデータベース名にするものとします。
このパラメータを変更した時には pgpool-II を再起動してください。
- system_db_schema
-
システムDBは専用のスキーマに設置します。そのスキーマ名を指定します。 このスキーマはあらかじめ存在しなければなりません。ここでは、 "pgpool_catalog"というスキーマにするものとします。
このパラメータを変更した時には pgpool-II を再起動してください。
- system_db_user
-
システムDBに接続するときのユーザ名です。
このパラメータを変更した時には pgpool-II を再起動してください。
- system_db_password
-
システムDBに接続するときのパスワードです。パスワードを設定していない場合は空文字にしておきます。
このパラメータを変更した時には pgpool-II を再起動してください。
システムDBの初期設定
システムDBにスキーマとテーブルを作成します。初期設定用のスクリプトが $prefix/share/system_db.sqlにあるのでそれを利用します。 ただし、このスクリプトではスキーマ名が"pgpool_catalog"となっているので、 違うスキーマを使う場合は適当に書き換えてください。 また、データベース名として"pgpool"以外を使う場合は以下を適当に読み替えてください。
psql -f $prefix/share/system_db.sql pgpool
dblinkのインストール
パラレルモードではdblinkを使います。dblinkはPostgreSQLソースファイル($POSTGRES_SRC)
$(POSTGRES_SRC)/contrib/dblink
にあります。$POSTGRES_SRC/contrib/dblink/README.dblinkを参考にシステム DBにdblinkをインストールしてください。
また、pgpoolデータベースに関数の登録が必要です。
psql pgpool < $POSTGRES_SRC/contrib/dblink/dblink.sql
コネクション数の設定
パラレルモードでは、クエリによりシステムDBからdblink経由でpgpoolに接続するので、 想定される同時接続数以上のコネクションが必要になる場合があります。 そのため、pgpool.confのnum_init_childrenには 同時接続数より十分大きい値を設定して下さい。
目安として以下の式でnum_init_childrenを設定してください。
num_init_children = 想定される同時接続数 * ( 1 + クエリの中で使われているテーブルの最大数)
データ分割ルールの登録
データ分割を行うテーブルに対しては、テーブル情報をあらかじめ pgpool_catalog.dist_def というテーブルに登録しておきます。
CREATE TABLE pgpool_catalog.dist_def(
dbname TEXT, -- DB名
schema_name TEXT, --schema名
table_name TEXT, -- テーブル名
col_name TEXT NOT NULL CHECK (col_name = ANY (col_list)), -- 分散キー列名
col_list TEXT[] NOT NULL, -- tableの属性名
type_list TEXT[] NOT NULL, -- 属性のタイプ名
dist_def_func TEXT NOT NULL, -- 分散先のDBノードを決定する関数名
PRIMARY KEY (dbname,schema_name,table_name)
);
レプリケーションテーブルのルール登録
一つのSQL文にJOIN等でデータ分割ルールに登録したテーブルと共に レプリケーションを行うテーブルを指定する場合には、レプリケーションを行うテーブルの情報を あらかじめ、pgpool_catalog.replicate_defというテーブルに登録しておきます。
CREATE TABLE pgpool_catalog.replicate_def(
dbname TEXT, -- DB名
schema_name TEXT, -- schema名
table_name TEXT, -- テーブル名
col_list TEXT[] NOT NULL, -- tableの属性名
type_list TEXT[] NOT NULL, -- 属性のタイプ名
PRIMARY KEY (dbname,schema_name,table_name)
);
pgbench テーブルでの分割ルール例
pgbenchのテーブルを分割するルールの例を示します。
この例では、accountsテーブルに対しては分割を行い、branchesテーブル とtellersテーブルに対してはレプリケーションを行うことにします。 また、accountsテーブルとbanchesテーブルはbidで結合されることを想定し branchesテーブルはレプリケーションテーブルのルール登録を行います。
もし、accountsテーブル、branchesテーブルとtellersテーブルの3つの テーブルの結合が行われる場合には、あらかじめtellersテーブルに対しても レプリケーションテーブルのルール登録を行う必要があります。
INSERT INTO pgpool_catalog.dist_def VALUES (
'pgpool',
'public',
'accounts',
'aid',
ARRAY['aid','bid','abalance','filler'],
ARRAY['integer','integer','integer','character(84)'],
'pgpool_catalog.dist_def_accounts'
);
INSERT INTO pgpool_catalog.replicate_def VALUES (
'pgpool',
'public',
'branches',
ARRAY['bid','bbalance','filler'],
ARRAY['integer','integer','character(84)']
);
ここで、pgpool_catalog.dist_def_accountsは、引数として分割キーの値を受け取り、 どのPostgreSQLサーバ(「DBノード」と呼びます)を0からの番号で返す関数です。 ここでは、3台のDBノードにデータを分割する関数の例を示します。
CREATE OR REPLACE FUNCTION pgpool_catalog.dist_def_accounts (val ANYELEMENT) RETURNS INTEGER AS '
SELECT CASE WHEN $1 >= 1 and $1 <= 30000 THEN 0
WHEN $1 > 30000 and $1 <= 60000 THEN 1
ELSE 2
END' LANGUAGE SQL;
クライアント認証(HBA)のための pool_hba.conf 設定方法
PostgreSQLのpg_hba.confと同じようにpgpoolでもpool_hba.confファイルを使った クライアント認証がサポートされています。
pgpoolをインストールするとデフォルトインストール先の設定ファイルディレクトリ "/usr/local/etc"にpool_hba.conf.sampleが一緒にインストールされます。 このpool_hba.conf.sampleファイルをpool_hba.confとしてコピーし、 必要であれば編集してください。 デフォルトではpool_hbaによる認証は無効にになっています。 pgpool.confのenable_pool_hbaをonにしてください。
pool_hba.confのフォーマットはpg_hba.confのものとほとんど同じです。
local DATABASE USER METHOD [OPTION] host DATABASE USER CIDR-ADDRESS METHOD [OPTION]
各フィールドで設定できる値の詳細は"pool_hba.conf.sample"を参照してください。
以下はpool_hbaの制限事項です。
- "hostssl"接続タイプはサポートされません
- DATABASEフィールド値として"samegroup"はサポートされません
- USERフィールド値として"+"を使ったグループ指定はサポートされません
- IPv6アドレス/マスク表記法はサポートされません
- "trust", "reject", "pam", "md5"以外のメソッドはサポートされません
pool_hba.confに"hostssl"は指定することはできませんが、pgpool-IIは2.3以降でSSLをサポートしています。 詳細はSSLを参照してください。
pgpoolはバックエンドサーバにあるユーザ情報を事前に知る事ができないため、 データベース名はpool_hba.confにある値のみと比較されます。 なのでグループに関する認証はpool_hbaで行うことができません。
上記の"samegroup"と同じ理由で、ユーザ名はpool_hba.confにある値のみと比較されます。 グループに関する認証はpool_hbaで行うことはできません。
現在pgpoolはIPv6をサポートしていません。
これも上記の"samegroup"と同じ理由によるものです。 pgpoolはバックエンドのユーザ/パスワード情報を持っていないので、 バックエンドに保存されているパスワードを使った認証を行うことができません。
md5に関しては、pool_passwdというパスワードファイルを併用することによって利用できます。 詳細は認証・アクセス制御方式を参照してください。
ここで説明された機能、制限はクライアントとpgpool間で行われるクライアント認証についてだということに 注意してください。 クラインアントはpgpoolのクライアント認証に成功したとしても、 PostgreSQLによるクライアント認証に成功しないと接続状態となりません。 pool_hbaにとってはクライアントに指定されたユーザ名やデータベース名(例. psql -U testuser testdb)が 実際にバックエンド上に存在するかどうかは問題ではありません。 それがpool_hba.confの値とマッチするかどうかでチェックが行われます。
pgpoolが稼働するホスト上のユーザ情報を使ったPAM認証を利用することができます。 pgpoolをPAMサポート付きでビルドするにはconfigureオプションに"--with-pam"を指定してください。
./configure --with-pam
実際にPAM認証を有効にするには、pool_hba.confで"pam"メソッドを設定するのに加え、 pgpoolのサービス設定ファイルをシステムのPAM設定ディレクトリ(通常は /etc/pam.d に作成する必要があります。 サービス設定ファイルの例はインストールディレクトリの"share/pgpool.pam"を参考にしてく ださい。
クエリキャッシュの設定方法 〜 V3.1 (DEPRECATED)
注意: このクエリキャッシュ機能は近い将来実装から削除される予定です。 代わりに、オンメモリクエリキャッシュ機能を使用してください。pgpool-IIでは、すべてのモードでクエリキャッシュを利用することができます。 クエリキャッシュは、SELECTの結果を再利用することにより、性能を向上させます。 利用する場合には、pgpool.confの設定を以下のように設定します。
enable_query_cache = true
また、システムDBに以下のテーブルを作成してください。
CREATE TABLE pgpool_catalog.query_cache ( hash TEXT, query TEXT, value bytea, dbname TEXT, create_time TIMESTAMP WITH TIME ZONE, PRIMARY KEY(hash, dbname) );
ただし、この例ではスキーマ名が"pgpool_catalog"となっているので、 違うスキーマを使う場合は適当に書き換えてください。
注意: 現在のクエリキャッシュの実装では、キャッシュがデータベース上に作成されます。 そのため、実行にあまり時間のかからないようなSELECTでは、クエリキャッシュを有効にすることによって、 かえって遅くなることがあります。また、クエリキャッシュの内容は、テーブルが更新されてもそのままです。 手動で上記テーブルから削除するか、-c オプション(クエリキャッシュのクリア)を追加して pgpool-IIを再起動する必要があります。
オンメモリクエリキャッシュの設定方法 V3.2 〜
pgpool-IIでは、すべてのモードでオンメモリクエリキャッシュを利用することができます。 上記のクエリキャッシュと違い、メモリ上にキャッシュが置かれるので高速であるばかりでなく、 データが更新されると自動的にキャッシュが無効になり、pgpool-IIの再起動の必要がありません。
オンメモリクエリキャッシュは、問い合わせのSELECT文(拡張問い合わせの場合は更にバインドパラメータ)と 検索結果をペアで記録し、2回目以降に同じSELECT文が発行された場合に、キャッシュから結果を返します。 通常のSELECT文処理と違って、PostgreSQLにアクセスしないだけでなく、 pgpool内部のSQLパース処理などを経由しないため、非常に高速です。
反面、キャッシュにヒットしない場合は通常のSELECT文の処理に加えてキャッシュ処理のオーバヘッドが生じるので、 かえって遅くなります。 また、あるテーブルが更新された場合、そのテーブルを参照している すべてのキャッシュが自動削除されるため(自動削除しない設定も可能)、 更新処理が多いシステムではオンメモリクエリキャッシュを有効にしていることでかえって遅くなります。 キャッシュのヒット率が70%以下の場合は、オンメモリクエリキャッシュの設定を有効にしないほうが良いでしょう。
オンメモリクエリキャッシュの制限事項
- オンメモリクエリキャッシュでは、テーブルに変更があると、関連するキャッシュを自動的に削除して古いデータが返却されないようにする機能があります。 このため、pgpoolは常にUPDATEやINSERTやALTER TABLEなどのコマンドが発行されたかどうかをモニタしています。 しかし、トリガ、外部キーやDROP TABLE CASCADEなどの働きによって暗黙的にテーブルが更新されたことはpgpool-IIからはわからないため、この機能が働きません。 この問題を回避するためには、memqcache_expireを使って一定時間経過したキャッシュを削除するようにするか、black_memqcache_table_listを使って、該当テーブルがキャッシュされないようにしてください。
- 複数のpgpool-IIを動かす環境で共有メモリを使ったオンメモリクエリキャッシュを使用すると、あるpgpool-II経由でテーブルが更新された時に、他のpgpool-IIのキャッシュが削除されず、古いデータを読みだしてしまうことがあります。 このような環境では、キャッシュストレージにmemcachedを使ってください。
オンメモリクエリキャッシュの有効化
オンメモリクエリキャッシュを有効にするには、pgpool.confの"memory_cache_enabled"を有効にします。
memory_cache_enabled = true
キャッシュストレージの選択
メモリキャッシュのストレージには、共有メモリとmemcachedのどちらかを 選択することができます(併用はできません)。
共有メモリを使用するクエリキャッシュは高速で、memcachedの立ち上げも必要なく、手軽に利用できます。 ただし、共有メモリサイズの上限によって保存できるキャッシュの量に制限があります。 memcachedをキャッシュストレージに使用する場合は、ネットワークアクセスのオーバヘッドがあるものの、 比較的自由にキャッシュメモリの大きさを設定できます。
共有メモリを利用する場合は"memqcache_method"に 'shmem'、Memcachedを利用する場合は'memcached'と設定します。 デフォルトは、'shmem'です。
キャッシュが作成される場合と作成されない場合
すべてのSELECT(もしくはWITH)がオンメモリクエリキャッシュの対象になるわけではありません。 キャッシュとDBの一貫性を極力保つために、キャッシュされないケースがあります。以下それを列挙します。
- black_memqcache_table_listで指定されているテーブルを使っているSELECT
- 「/*NO QUERY CACHE*/」コメントで始まるSELECT
- SELECT FOR SHAREまたはUPDATE
- IMMUTABLEでない関数を使っているSELECT
- 一時テーブルを使っているSELECT
- システムカタログを検索しているSELECT
- VIEWをまたはunloggedテーブル使っているSELECT。 ただし、それらのテーブルがwhite_memqcache_table_listで指定されている場合はキャッシュの対象になります。
- 明示的なトランザクション内でSELECTが発行され、そのトランザクションがアボートした時
- SELECT結果が大きい場合(memqcache_maxcacheの項参照)
キャッシュがあっても参照されない場合
オンメモリクエリキャッシュが存在しても、そのキャッシュが利用されないケースがあります。 以下それを列挙します。
- 明示的なトランザクション内で更新クエリが発行されている場合は、そのトランザクション内では 一切クエリキャッシュは参照されません。
- そのキャッシュを違うユーザが作成していた場合(セキュリティ上の理由)
- キャッシュの寿命を超えていた場合(memqcache_expireの項を参照)
共通設定項目
キャッシュストレージを共有メモリにする場合でも、memcachedにする場合でも、共通で設定する項目を説明します。
- memqcache_expire V3.2 〜
-
クエリキャッシュの寿命を秒単位で設定します。デフォルト0です。 0を指定すると寿命が無限大になり、関連テーブルが更新されるまではキャッシュが有効になります。 なお、この設定は、memqcache_auto_cache_invalidationとは 独立です。
- memqcache_auto_cache_invalidation V3.2 〜
-
trueならば関連するテーブルが更新されるとキャッシュを無効化します。 falseならばテーブルが更新されてもキャッシュを無効化しません。 デフォルト値はonです。 なお、この設定はmemqcache_expireの設定とは独立です。
- white_memqcache_table_list V3.2 〜
-
VIEW やunloggedテーブルを使っているSELECTは通常キャッシュの対象になりませんが、 white_memqcache_table_list に記述しておくことで、キャッシュされるようになります。 テーブル名はカンマ区切りで指定します。正規表現も利用できます (指定した各表現に ^ と $ をつけた形で使われます)。
なお、同じテーブル・VIEW が black_memqcache_table_list と両方に 指定されている場合は、white_memqcache_table_list が優先され、キャッシュを利用します。
スキーマ名を付けないテーブル名とスキーマ名を付けた形の両方をクエリの中で使う場合は、両方共リストに登録してください。たとえば、"table1"と"public.table1"の両方がクエリに現れる場合は、単に"table1"ではなく、"table1,public.table1"を追加する必要があります。
- black_memqcache_table_list V3.2 〜
-
SELECT結果をキャッシュしたくないテーブル名をカンマ区切りで指定します。正規表現も利用できます (指定した各表現に ^ と $ をつけた形で使われます)。
スキーマ名を付けないテーブル名とスキーマ名を付けた形の両方をクエリの中で使う場合は、両方共リストに登録してください。たとえば、"table1"と"public.table1"の両方がクエリに現れる場合は、単に"table1"ではなく、"table1,public.table1"を追加する必要があります。
- memqcache_maxcache V3.2 〜
-
SELECT文の実行結果がmemqcache_maxcacheバイトを超えると、キャッシュされません。 この場合、以下のようなメッセージが表示されます。
2012-05-02 15:08:17 LOG: pid 13756: pool_add_temp_query_cache: data size exceeds memqcache_maxcache. current:4095 requested:111 memq_maxcache:4096
この問題を回避するためには、memqcache_maxcacheを大きくすれば良いのですが、 キャッシュストレージとして共有メモリを使用する場合は、 memqcache_cache_block_sizeを超えないようにしてください。 キャッシュストレージとしてmemcachedを使用する場合は、 memcachedのスラブサイズ(デフォルトで1MB)を超えないようにしてください。
- memqcache_oiddir V3.2 〜
-
SELECT文が使用するテーブルにOIDを格納する一時ファイル領域のトップディレクトリをフルパスで指定します。 memqcache_oiddir以下には、データベースOID名のディレクトリが作成され、 更にその下にはテーブルOID名のファイルが作成されます。 テーブルOID名ファイルの中には、クエリキャッシュへのポインタが格納されており、 テーブルの更新があった際にキャッシュを削除するキーとなります。
この領域はデフォルトでは、pgpool を再起動しても再利用されます。 再利用せずに削除して起動したい場合は、pgpool コマンド に -C オプションをつけて起動します。
キャッシュのモニタリング
オンメモリクエリキャッシュをモニタする方法を説明します。 キャッシュから検索結果が取得されたかどうかは、log_per_node_statement を 有効にすることで確認できます。
2012-05-01 15:42:09 LOG: pid 20181: query result fetched from cache. statement: select * from t1;
クエリキャッシュのヒット率は、show pool_status コマンド で確認できます。
memqcache_stats_start_time | Tue May 1 15:41:59 2012 | Start time of query cache stats memqcache_no_cache_hits | 80471 | Number of SELECTs not hitting query cache memqcache_cache_hits | 36717 | Number of SELECTs hitting query cache
この例では、
(memqcache_cache_hits) / (memqcache_no_cache_hits+memqcache_cache_hits) = 36717 / (36717 + 80471) = 31.3%
がキャッシュヒット率ということになります。
show pool_cacheコマンドでも同様の内容が確認できます。
共有メモリ設定項目
キャッシュストレージとして共有メモリを使用する場合の設定項目を説明します。
- memqcache_total_size V3.2 〜
-
キャッシュストレージに使用する共有メモリ領域のサイズを指定します。単位はバイトです。
- memqcache_max_num_cache V3.2 〜
-
キャッシュの数を指定します。 この設定項目は、キャッシュの管理領域の大きさを決めるために使用します (memqcache_total_sizeとは別に取られます)。 管理領域の大きさは、memqcache_max_num_cache * 48(バイト)になります。 この数は少なすぎるとキャッシュを登録することができずにエラーになります。 逆に多すぎると無駄になります。
- memqcache_cache_block_size V3.2 〜
-
キャッシュストレージとして共有メモリを使用する場合は、メモリを memqcache_cache_block_size のブロックに分けて利用します。検索結果 のキャッシュはこのブロックに入るだけ詰め込まれます。 ただし、キャッシュは複数のブロックにまたがって格納されないので、 memqcache_cache_block_sizeを検索結果が超えると、キャッシュに格納できなくなります。 memqcache_cache_block_sizeは、512以上の値でなければなりません。
memcached設定項目
キャッシュストレージとしてmemcachedを使用する場合の設定項目を説明します。
- memqcache_memcached_host V3.2 〜
-
memcachedが動いているホスト名またはIPアドレスを指定します。 pgpool-IIと同じマシンでmemcachedを動かす場合は、'localhost'とします。
- memqcache_memcached_port V3.2 〜
-
memcachedのポート番号を指定します。デフォルト値は 11211 です。
memcachedのインストール
pgpool-IIのクエリキャッシュストレージとしてmemcachedを使用する場合は、動作しているmemcachedと、 libmemcachedというクライアントライブラリのインストールが必要です。 rpmなどからインストールするのがおすすめですが、ここではソースコードからインストールする方法を説明します。
memcachedのソースコードはmemcached開発ページからダウンロードできます。
- configureの実行
-
ソースコードのtar ballを展開したら、configureを実行します。
./configure
- makeの実行
-
make make install
libmemcachedのインストール
memcachedのクライアントライブラリは、libmemcachedを使用しています。
memcachedのインストール後に、libmemcachedをインストールする必要があります。
libmemcachedのソースコードは、libMemcached開発ページから ダウンロードできます。
- configureの実行
-
ソースコードのtar ballを展開したら、configureを実行します。
./configure
configureに指定できるオプションは以下です。
--with-memcached=path
Memcachedがインストールされているトップディレクトリを指定します。
- makeの実行
-
make make install
pgpool-IIの起動と停止
pgpool-II の起動
以上で設定が終わったので、各DBノードを起動し、必要ならばシステムDBも起動してからpgpool-IIを起動します。
pgpool [-c][-f config_file][-a hba_file][-F pcp_config_file][-n][-D][-d]
| -c | --clear-cache | クエリキャッシュを消去します |
| -f config_file | --config-file config-file | pgpool-IIの設定ファイルを指定します |
| -a hba_file | --hba-file hba_file | HBA認証設定ファイルを指定します |
| -F pcp_config_file | --pcp-password-file | pcpの設定ファイルを指定します |
| -n | --no-daemon | デーモンモードで起動しません(制御端末を切り離しません) |
| -D | --discard-status | pgpool_statusを削除し、以前の状態を復元しません V3.0 〜 |
| -C | --clear-oidmaps | オンメモリクエリキャッシュの memqcache_oiddir の ディレクトリの中身を消去します (memqcache_method が 'memcached' のときのみ。 'shmem' のときは指定しなくても、必ず消去されます)。 V3.2 〜 |
| -d | --debug | デバッグモードで起動します |
pgpool-II の停止
pgpool-IIの停止は後述のpcpコマンドでもできますが、pgpool-IIコマンドを使うこと もできます。
pgpool [-f config_file][-F pcp_config_file] [-m {s[mart]|f[ast]|i[mmediate]}] stop
| -m s[mart] | --mode s[mart] | 接続中のクライアントが接続を終わるのを待ってから停止します(デフォルト) |
| -m f[ast] | --mode f[ast] | 接続中のクライアントが接続を終わるのを待たずに直ちに停止します |
| -m i[mmediate] | --mode i[mmediate] | -m fと同じ動作です |
pgpoolが停止すると、[logdir]/pgpool_statusというファイルにバックエンドの状態を書き込みます。 次回pgpoolが起動したときにこのファイルが存在すると、バックエンドの状態をそこから復元します。 これによって、
- バックエンドが停止してフェイルオーバ
- pgpool経由で正常なDBを更新
- pgpoolを停止
- 停止していたDBを再起動
- pgpoolを再起動
というシーケンスで、不整合のあるDBからレプリケーション状態に移行することを防ぐことができます。
もしもDBの状態に不整合がなくなっている、あるいはpgpool.confを書き換えて設定を変えてしまった、 というときはpgpool_statusを削除すればバックエンドの状態の復元を行いません。
pgpool-IIの設定ファイルの再読み込み
pgpool-IIの設定ファイルは、pgpool-IIを再起動することなく読み直すことができます。
pgpool [-f config_file][-a hba_file][-F pcp_config_file] reload
| -f config_file | pgpool-IIの設定ファイルを指定します |
| -a hba_file | HBA認証設定ファイルを指定します |
| -F pcp_config_file | pcpの設定ファイルを指定します |
設定項目によっては、再読み込みを行なっても反映されないものがあるので、ご注意下さい。 また、設定の変更はすでに接続中のセッションには反映されません。 次回、クライアントがpgpool-IIに接続したときから反映されます。
SHOWコマンド
概要
pgpool-IIでは、SHOWコマンドを使って情報を参照することができます。 SHOWはSQLコマンドですが、pgpool-IIは一部のSHOWコマンドを独自に解釈して、pgpool-IIが管理する情報を返却します。 以下のようなものがあります。
| pool_status | 構成情報 |
|---|---|
| pool_nodes | DBノード情報 V3.0 〜 |
| pool_processes | pgpool-IIプロセスの内部情報 V3.0 〜 |
| pool_pools | コネクションプール情報 V3.0 〜 |
| pool_version | pgpool-IIのバージョン V3.0 〜 |
"pool_status" SQL は以前からありますが、他のSQLはpgpool-II 3.0から追加されました。
注意: "pool"という用語は、pgpoolプロセスによって所有されるPostgreSQLセッションを指します。 pgpoolによって所有されるセッション全体ではありません。
pool_status
"SHOW pool_status" は設定パラメータの名前と値、説明を表示します。出力の一部を示します。
benchs2=# show pool_status;
item | value | description
--------------------------------------+--------------------------------+------------------------------------------------------------------
listen_addresses | localhost | host name(s) or IP address(es) to listen to
port | 9999 | pgpool accepting port number
socket_dir | /tmp | pgpool socket directory
pcp_port | 9898 | PCP port # to bind
pcp_socket_dir | /tmp | PCP socket directory
pool_nodes V3.0 〜
"SHOW pool_nodes"は、DBノードのリストを表示します。 ホスト名、ポート番号、状態、重み(ロードバランスモードで運用しているときにのみ意味があります)、 ノードの役割が表示されます。 状態(status)の意味については、pcp_node_infoリファレンスで説明されています。
benchs2=# show pool_nodes; id | hostname | port | status | lb_weight | role ------+-------------+------+--------+-----------+--------- 0 | 127.0.0.1 | 5432 | 2 | 0.5 | primary 1 | 192.168.1.7 | 5432 | 3 | 0.5 | standby (2 lignes)
pool_processes V3.0 〜
"SHOW pool_processes"は、接続待ち、あるいは接続中pgpool-IIの子プロセスの状態を表示します。
6つのカラムがあります。
- pool_pid はpgpool-IIプロセスのプロセスIDです。
- start_timeはこのプロセスが起動された時刻です(1970年1月1日からの経過秒で表示されます)。
- databaseはこのプロセスが接続しているデータベース名です。
- usernameはこのプロセスの接続で使用しているユーザ名です。
- create_time isはこの接続が作成された時刻です。
- pool_counter はこの接続が使用された回数です。
返却行数は常にnum_init_childrenになります。 また、データベース名などが表示されるのは、そのプロセスにフロントエンドからの接続がある場合に限ります。
benchs2=# show pool_processes; pool_pid | start_time | database | username | create_time | pool_counter ----------+---------------------+----------+-----------+---------------------+-------------- 8465 | 2010-08-14 08:35:40 | | | | 8466 | 2010-08-14 08:35:40 | benchs | guillaume | 2010-08-14 08:35:43 | 1 8467 | 2010-08-14 08:35:40 | | | | 8468 | 2010-08-14 08:35:40 | | | | 8469 | 2010-08-14 08:35:40 | | | | (5 lines)
pool_pools V3.0 〜
"SHOW pool_pools"は、pgpool-IIのコネクションプールの状態を表示します。
11のカラムがあります。
- start_timeはこのプロセスが起動された時刻です(1970年1月1日からの経過秒で表示されます)。
- pool_pid はpgpool-IIプロセスのプロセスIDです。
- pool_id はコネクションプールIDです。(0からmax_pool-1の値です)
- backend_id はPostgreSQLバックエンドの識別子です(0からバックエンド数-1の値です)
- databaseはこのプロセスが接続しているデータベース名です。
- usernameはこのプロセスの接続で使用しているユーザ名です。
- create_time isはこの接続が作成された時刻です。
- majorversion と minorversion はこの接続で使用されているプロトコルバージョン番号です。
- pool_counter はこの接続が使用された回数です。
- pool_backendpid は PostgreSQL のバックエンドプロセスのプロセスIDです。
- pool_connected は真偽値で、0ならフロントエンドからの接続無し、1なら接続ありを表します。
返却行数は常にnum_init_children * max_poolになります。
benchs2=# show pool_pools; pool_pid | start_time | pool_id | backend_id | database | username | create_time | majorversion | minorversion | pool_counter | pool_backendpid | pool_connected ----------+---------------------+---------+------------+----------+-----------+---------------------+--------------+--------------+--------------+-----------------+---------------- 8465 | 2010-08-14 08:35:40 | 0 | 0 | | | | | | | | 8465 | 2010-08-14 08:35:40 | 1 | 0 | | | | | | | | 8465 | 2010-08-14 08:35:40 | 2 | 0 | | | | | | | | 8465 | 2010-08-14 08:35:40 | 3 | 0 | | | | | | | | 8466 | 2010-08-14 08:35:40 | 0 | 0 | benchs | guillaume | 2010-08-14 08:35:43 | 3 | 0 | 1 | 8473 | 1 8466 | 2010-08-14 08:35:40 | 1 | 0 | | | | | | | | 8466 | 2010-08-14 08:35:40 | 2 | 0 | | | | | | | | 8466 | 2010-08-14 08:35:40 | 3 | 0 | | | | | | | | 8467 | 2010-08-14 08:35:40 | 0 | 0 | | | | | | | | 8467 | 2010-08-14 08:35:40 | 1 | 0 | | | | | | | | 8467 | 2010-08-14 08:35:40 | 2 | 0 | | | | | | | | 8467 | 2010-08-14 08:35:40 | 3 | 0 | | | | | | | | 8468 | 2010-08-14 08:35:40 | 0 | 0 | | | | | | | | 8468 | 2010-08-14 08:35:40 | 1 | 0 | | | | | | | | 8468 | 2010-08-14 08:35:40 | 2 | 0 | | | | | | | | 8468 | 2010-08-14 08:35:40 | 3 | 0 | | | | | | | | 8469 | 2010-08-14 08:35:40 | 0 | 0 | | | | | | | | 8469 | 2010-08-14 08:35:40 | 1 | 0 | | | | | | | | 8469 | 2010-08-14 08:35:40 | 2 | 0 | | | | | | | | 8469 | 2010-08-14 08:35:40 | 3 | 0 | | | | | | | | (20 lines)
pool_version V3.0 〜
"SHOW pool_version" はpgpool-IIのバージョン情報を表示します。 例を示します。
benchs2=# show pool_version;
pool_version
------------------------
3.0-dev (umiyameboshi)
(1 line)
pool_cache V3.1 〜
"SHOW pool_cache" はオンメモリクエリキャッシュが有効である場合に、クエリキャッシュのヒット率や、キャッシュストレージの状況を表示します。 例を示します。
test=# \x \x Expanded display is on. test=# show pool_cache; show pool_cache; -[ RECORD 1 ]---------------+--------- num_cache_hits | 891703 num_selects | 99995 cache_hit_ratio | 0.90 num_hash_entries | 131072 used_hash_entries | 99992 num_cache_entries | 99992 used_cache_enrties_size | 12482600 free_cache_entries_size | 54626264 fragment_cache_entries_size | 0
- num_cache_hits は、キャッシュにヒットした検索件数を表示します。
- num_selects は、キャッシュにヒットしなかった検索件数を表示します。 cache_hit_ratio は、キャッシュヒット率で、num_cache_hits/(num_cache_hits+num_selects) から計算されています。
- num_hash_entries 以下は、キャッシュストレージが共有メモリの時だけ有効です。
- num_hash_entries は、キャッシュの検索インデックスであるハッシュテーブルのエントリ数を表し、 pgpool.confの memqcache_max_num_cache と一致します。 この値が登録できるキャッシュ件数の最大値になります。
- used_hash_entries は、num_hash_entries のうち、使用済みのエントリ数です。
- num_cache_entries は、キャッシュ本体の登録件数で、used_hash_entries と一致します。
- used_cache_enrties_size は、使用済みのキャッシュ領域の合計サイズです。 単位はバイトです。
- free_cache_entries_size は、キャッシュ領域のうち、未使用または最利用可能な領域の合計サイズです。 単位はバイトです。
- fragment_cache_entries_size は、空き領域ではあるが、断片化していて利用できないキャッシュ領域の合計サイズです。 単位はバイトです。 断片化した領域は、利用できるキャッシュ領域を使い果たした時に自動的に再利用できるようになります。
オンラインリカバリ
オンラインリカバリ概要
この章では、レプリケーションモードで利用する場合のオンラインリカバリ機能 について説明します。 マスタ/スレーブモード(Streaming Replication)でのオンラインリカバリの利用方法については、 Streaming Replicationへの対応をご覧下さい。 レプリケーションモードで pgpool が動作している場合、ダウンしたノードのデータを再同期させた上で、 ノードを復帰させることができます。この機能を「オンラインリカバリ」と呼びます。
オンラインリカバリを実施するためには、ノードが切り離されていると pgpool が検知している必要があります。ノードを動的に追加したい場合には pgpool.conf の backend_hostnameなどのパラメータを追加しておき、 設定ファイルを再読み込みさせると、ノードが切り離された状態で pgpool にノード情報が登録されます。
また、リカバリするノードの PostgreSQL がすでに動作中であれば、あらかじめ PostgreSQL をシャットダウンさせておいてください。
pgpool ではオンラインリカバリを 2 段階に分けて実施します。 pgpool のクライアントからは完全なデータの同期を取るために若干の接続待ちが発生します。 リカバリ手順で以下のとおりです。
- CHECKPOINT 実行
- ファーストステージの実施
- 接続がすべて切断されるまで待機
- CHECKPOINT 実行
- セカンドステージの実施
- postmaster の起動(pgpool_remote_start の実行)
- ノードの復帰
データ同期の第一段階を「ファーストステージ」と呼びます。ファーストステージ中に1 回目のデータ同期を行います。 ファーストステージ中はデータの更新や参照を並行して行うことができます。
ファーストステージで処理する内容はユーザが定義することができます。 スクリプトでは 3 つの引数を受け取ることができます。
- マスタのデータベースクラスタパス
- リカバリノードのホスト名
- リカバリノードのデータベースクラスタパス
次に 2 回目のデータ同期を行います。これを「セカンドステージ」と呼びます。 pgpool ではセカンドステージに入る前に接続中のクライアントがすべて接続が終了されるまで待ちます。 その間に接続リクエストが来た場合には、その接続をすべてブロックします。
セカンドステージで処理する内容はユーザが定義することができます。 スクリプトでは 3 つの引数を受け取ることができます。
- マスタのデータベースクラスタパス
- リカバリノードのホスト名
- リカバリノードのデータベースクラスタパス
すべての接続が終了されると、ファーストステージ以降に更新されたデータを同期するための セカンドステージが開始されます。そこで最終的なデータの同期を行います。 この間はクライアントからは pgpool への接続が待たされる状態になります。
なお、オンラインリカバリの制限事項として、複数のホストに pgpool を配置して レプリケーションさせている場合には、オンラインリカバリは正しく動作しません。 どれかの pgpool にリカバリリクエストを出した時に、他の pgpool から更新が伝搬すると、 データを同期させることができなく なります。
pgpool の設定
オンラインリカバリを設定するためには、pgpool.conf の以下の値を設定してください。
- backend_data_directory
- recovery_user
- recovery_password
- recovery_1st_stage_command
- recovery_2nd_stage_command>
C 言語関数のインストール
次に、リカバリを実施するための PostgreSQL の C 言語関数を各ノードの template1 データベースにインストールします。ソースコードは
pgpool-II-x.x.x/sql/pgpool-recovery/
にあります。ディレクトリを移動し、make install してください。
% cd pgpool-II-x.x.x/sql/pgpool-recovery/ % make install
C 言語関数のモジュールをインストールしたら、続いて C 言語関数を呼びだすための SQL をインストールします。
% cd pgpool-II-x.x.x/sql/pgpool-recovery/ % psql -f pgpool-recovery.sql template1
リカバリスクリプトの配置
データを同期させるためのスクリプトと、リモートから postmaster を再起動させるためのスクリプトを 各ノードの $PGDATA 以下に配置します。 あらかじめpgpool-II-x.x.x/sample 以下にサンプルスクリプトも用意してありますので参考にしてください。 ここではサンプルスクリプトを使って、PITR によるリカバリ方法と、rsync によるリカバリ方法を説明します。
PITR によるリカバリ
ここでは PostgreSQL 8.2 以降で PITR 機能を使ってリカバリをする設定例を説明します。 PITR によるリカバリをする場合にはあらかじめ PostgreSQL の設定で ログをアーカイブさせるようにしておいてください。
1st stage
まずファーストステージでベースバックアップを取得し、リカバリ先へコピーするスクリプト (ここではファイル名を copy-base-backup とします)を用意します。 例えば以下のようなスクリプトで取得することができます。
#! /bin/sh
DATA=$1
RECOVERY_TARGET=$2
RECOVERY_DATA=$3
psql -c "select pg_start_backup('pgpool-recovery')" postgres
echo "restore_command = 'scp $HOSTNAME:/data/archive_log/%f %p'" > /data/recovery.conf
tar -C /data -zcf pgsql.tar.gz pgsql
psql -c 'select pg_stop_backup()' postgres
scp pgsql.tar.gz $RECOVERY_TARGET:$RECOVERY_DATA
ベースバックアップ取得時に recovery.conf を生成しておきます。
restore_command = 'scp master:/data/archive_log/%f %p'
2nd stage
セカンドステージでは最新の状態まで PITR によるリカバリを実施できるようにするために、 pgpool_recovery_pitr スクリプトを$PGDATA にコピーします。 このスクリプトではトランザクションログを強制的に切り替えるようにします。
通常、トランザクションログを切り替えるには、pg_switch_xlog 関数を利用しますが、 この関数は、アーカイブログファイルが生成される前に終了してしまう可能性があります。
V3.1 〜 そこで、より安全にオンラインリカバリを行うために pgpool_switch_xlog 関数が用意されています。 pgpool_switch_xlog 関数の基本動作は pg_switch_xlog 関数と同じですが、 トランザクションログの切り替えによるアーカイブログファイルの生成を 待ってから終了します。 この関数は、前述の「C言語関数のインストール」を実施するとインストールされ、 引数にはアーカイブログの出力先ディレクトリを指定します。
#! /bin/sh
# Online recovery 2nd stage script
#
datadir=$1 # master dabatase cluster
DEST=$2 # hostname of the DB node to be recovered
DESTDIR=$3 # database cluster of the DB node to be recovered
port=5432 # PostgreSQL port number
archdir=/data/archive_log # archive log directory
# Force to flush current value of sequences to xlog
psql -p $port -t -c 'SELECT datname FROM pg_database WHERE NOT datistemplate AND datallowconn' template1|
while read i
do
if [ "$i" != "" ];then
psql -p $port -c "SELECT setval(oid, nextval(oid)) FROM pg_class WHERE relkind = 'S'" $i
fi
done
psql -p $port -c "SELECT pgpool_switch_xlog('$archdir')" template1
スクリプト中のwhileループは、全データベース中のシーケンス値をトランザクションログに吐き出します。 これによって、シーケンスも正しくリカバリされるようになります。
スクリプトの配置が完了したら pgpool.conf に設定します。
recovery_1st_stage_command = 'copy-base-backup' recovery_2nd_stage_command = 'pgpool_recovery_pitr'
これで PITR によるオンラインリカバリの準備が完了です。
pgpool_remote_start
データ再同期後に postmaster を起動させるスクリプトです。 pgpool からは以下の形式でスクリプトを実行します。
% pgpool_remote_start remote_host remote_datadir remote_host: リカバリノードのホスト名 remote_datadir: リカバリノードのデータベースクラスタパス
サンプルスクリプトでは ssh 経由で postmaster を起動しています。 こちらもあらかじめパスフレーズ無しで ssh 経由でログインできるように設定しておく必要があります。
PITR によるリカバリであれば、pgpool_remote_start 内でベースバックアップを展開し、 recovery.conf の内容にしたがってリカバリした後にpostmaster が接続可能状態になります。
#! /bin/sh DEST=$1 DESTDIR=$2 PGCTL=/usr/local/pgsql/bin/pg_ctl # Expand a base backup ssh -T $DEST 'cd /data/; tar zxf pgsql.tar.gz' 2>/dev/null 1>/dev/null < /dev/null # Startup PostgreSQL server ssh -T $DEST $PGCTL -w -D $DESTDIR start 2>/dev/null 1>/dev/null < /dev/null &
rsync によるリカバリ
7.4 以前の場合は PITR 機能がありません。また、8.0 と 8.1 の場合は トランザクションログを強制的に切り替える関数が用意されていません。 そこで PITR を使わずにrsync を使ったリカバリ方法を説明します。
sample ディレクトリに pgpool_recovery というファイルがあります。 マスタから復帰させるノードへのデータの物理コピーを行うスクリプトです。 pgpool からは以下の形式でスクリプトを実行します。
% pgpool_recovery datadir remote_host remote_datadir datadir: マスタのデータベースクラスタパス remote_host: リカバリノードのホスト名 remote_datadir: リカバリノードのデータベースクラスタパス
サンプルスクリプトでは rsync を使って物理コピーをしています。もし rsync を使う場合は、パスフレーズ無しで ssh 経由でログインできるように あらかじめ設定しておく必要があります。
rsyncに関する注記:
- -c (or --checksum) オプションを付けないと、ファイルが確実に転送されない場合があります。
- -z (or --compress)オプションは低速なネットワークでは効果がありますが、 100M以上の高速なネットワークではかえってCPU負荷を増やし、結果的に遅くなることがあります。 高速ネットワークでは、このオプションを使用しないことをお勧めします。
- rsync の新しいバージョン(3.0.5)では、50%も性能が良くなったという報告が pgpool-generalメーリングリストでありました。
pgpool_recovery を使う場合は pgpool.conf に以下の行を追加してください。
recovery_1st_stage_command = 'pgpool_recovery' recovery_2nd_stage_command = 'pgpool_recovery'
リカバリの実行
以上でオンラインリカバリの準備が整いました。 オンラインリカバリを実行するには pcp_recovery_node コマンドを使うか、 pgpool 管理ツールから実行してください。
注意点として、pcp_recovery_node を実行する際に、タイムアウトを長くして ください。pgpoolAdmin から実行する場合は pgmgt.conf.php 内の _PGPOOL2_PCP_TIMEOUT を大きくしてください。
オンラインリカバリを利用したPostgreSQLのマイナーバージョンアップ
レプリケーションモードの場合
レプリケーションモードでpgpool-IIが動作している場合は、 オンラインで各ノードのPostgreSQLをバージョンアップできます。 ただし、ノードの切り離し時と追加時に、pgpool-IIに接続しているすべての すべてのセッションが切断されるので注意してください。 また、オンラインリカバリが利用できるバージョンアップはマイナーバージョンアップのみで、 ダンプ/リストアが不要なリリースに限ります。
はじめに、上記の「オンラインリカバリの概要」を参考に各ノードでオンラインリカバリが利用できるように準備します。
PostgreSQLのバージョンアップは、マスタ以外のノードから行い、最後にマスタノードをバージョンアップします。 そこで、まずバージョンアップを行うマスタ以外の1つのノードのPostgreSQLを停止します。 pgpool-IIがPostgreSQLの停止を検知すると、以下のようなログを出力して縮退運転に移行します。 その際、pgpool-IIに接続しているすべてのセッションは一旦切断されます。
2010-07-27 16:32:29 LOG: pid 10215: set 1 th backend down status 2010-07-27 16:32:29 LOG: pid 10215: starting degeneration. shutdown host localhost(5433) 2010-07-27 16:32:29 LOG: pid 10215: failover_handler: set new master node: 0 2010-07-27 16:32:29 LOG: pid 10215: failover done. shutdown host localhost(5433)
停止したノードのPostgreSQLをバージョンアップします。 バージョンアップは、新しいバージョンのPostgreSQLを古いバージョンのインストール先に上書きしても構いませんが、 問題が起きた時に元のバージョンに戻せるようにインストール先を変えておくことをお勧めします。
新しいバージョンのPostgreSQLを古いバージョンと別の場所にインストールした場合、 リカバリスクリプトを編集することなくそのまま使用するには、シンボリックリンクなどを使用してインストール先のパスを以前と合わせる必要があります。 上書きインストールした場合は以下のC言語関数をインストールするまでの操作は不要です。 すぐにオンラインリカバリが実行できます。
古いバージョンのPostgreSQLのインストール先ディレクトリ名を変更します。 以下は、PostgreSQLが/usr/local/pgsqlにインストールされていたと仮定した一例です。
$ mv /usr/local/pgsql /usr/local/pgsql-old
新しいバージョンのPostgreSQLのインストール先にシンボリックリンクを作成します。 これにより、今までどおりのパスで新しいバージョンのPostgreSQLが使用できるようになります。 以下は、新しいバージョンのPostgreSQLが/usr/local/pgsql-newにインストールされていると仮定した一例です。
$ ln -s /usr/local/pgsql-new /usr/local/pgsql
データベースクラスタディレクトリがPostgreSQLのインストール先ディレクトリの下位にある場合は、 同じパスでデータベースクラスタにアクセスできるようにシンボリックリンクを作成するかコピーします。 以下は、シンボリックリンクを作成する例です。
$ ln -s /usr/local/pgsql-old/data /usr/local/pgsql/data
新しいバージョンのPostgreSQLに、オンラインリカバリ用の関数を 「C言語関数のインストール」を参考にインストールします。 オンラインリカバリは、データベースクラスタをコピーしますので、最後のpsqlを使用した関数の作成は不要です。 make installを実行してください。
最後にオンラインリカバリを実行して、1つのノードのバージョンアップが完了します。 オンラインリカバリは、pcp_recovery_nodeコマンドを実行するかpgpoolAdminで行います。
以上の手順をマスタ以外のノードで繰り返し、最後にマスタノードで行えば、 全体のPostgreSQLのマイナーバージョンアップは完了です。
Streaming Replicationを利用している場合
マスタースレーブモードでStreaming Replicationを利用している場合は、 オンラインでスタンバイのPostgreSQLをマイナーバージョンアップできます。
スタンバイのPostgreSQLをマイナーバージョンアップする手順は、上記のレプリケーションモードの手順と同じです。 ただし、recovery_1st_stage_commandとrecovery_2nd_stage_commandの設定などは、 「Streaming Replicationでのオンラインリカバリ」を参考にしてください。
プライマリのPostgreSQLのマイナーバージョンアップは、オンラインではできません。 pgpool-IIの停止が必要になります。 プライマリのPostgreSQLもバージョンアップの方法自体は、スタンバイと同様です。 プライマリのPostgreSQLのバージョンアップは以下の手順で行います。
- pgpool-IIを停止
- プライマリのPostgreSQLを停止
- プライマリのPostgreSQLをバージョンアップ
- プライマリのPostgreSQLを起動
- pgpool-IIを起動
バックアップ
バックエンドとシステムDBのPostgreSQLのバックアップは、単体のPostgreSQLと同様に、 物理バックアップ、論理バックアップ(pg_dump, pg_dumpall)、PITRが使用できます。 ただし、論理バックアップとPITRの操作は、pgpool-IIを経由せずにPostgreSQLに対して直接行ってください。 これは、load_balance_modeやreplicate_selectなどの 設定によるバックアップの失敗を避けるためです。
レプリケーションモード、マスタースレーブモード
レプリケーションモードとマスタースレーブモードでpgpool-IIが動作している場合は、 クラスタを構成しているいずれかのノードでバックアップを行います。
マスタースレーブモードで非同期のレプリケーションを行っている場合で、かつ、 最新のバックアップを取得したい場合は、マスタノードでバックアップしてください。
バックアップ時の注意点として、PostgreSQLに対してpg_dumpコマンドなどを実行すると、 ACCESS SHAREモードのロックがかかります。 そのため、ACCESS SHAREモードと競合するACCESS EXCLUSIVEロックが必要になるコマンド (ALTER TABLE、DROP TABLE、TRUNCATE、REINDEX、CLUSTERおよびVACUUM FULLなど)は、ロック待ちが発生します。 これは、非同期のレプリケーションで、スレーブノードに対してバックアップを行っている場合も、 マスタが影響を受けることがありますので注意してください。
パラレルモード
パラレルモードでpgpool-IIが動作している場合、クラスタ全体のデータが一貫性のある状態でバックアップを取得するには、 アプリケーション、またはpgpool-IIの一時的な停止が必要になります。
論理バックアップを利用する場合は、アプリケーション、またはpgpool-IIを停止し、 すべてのノードでpg_dump, pg_dumpallコマンドを実行します。 そして、すべてのノードでダンプが終了したら、アプリケーション、またはpgpool-IIを起動してください。
PITRを利用する場合は、まず各ノードのシステムの時刻がほぼ一致していることを確認してください。 そして、事前に各ノードでアーカイブログの設定を行い、ベースバックアップを取得します。 ベースバックアップが終了したら、アプリケーション、またはpgpool-IIを一時的に停止します。 停止後、その時刻と次に起動した時刻を記録します。 この一時的な停止によって、クラスタ全体のデータが一貫性のある状態を保った期間ができます。 ベースバックアップとアーカイブログを使用して各ノードをリストアする場合は、 一時停止期間の真ん中あたりの時刻をrecovery.confのrecovery_target_timeに指定したうえで、リカバリを行ってください。
システムDBのバックアップ
パラレルクエリモード、またはクエリキャッシュを使用している場合は、システムDBもバックアップする必要があります。 pgpool.confの system_db_dbname に設定したデータベースをバックアップしてください。
pgpool-IIの配置について
pgpool-IIは、独立したサーバに配置することもできますし、アプリケーションサーバと同居させることもできますし、 その他の配置も考えられます。 ここではそれぞれの配置方法を紹介し、それぞれの特徴、メリット、デメリットを検討します。
- 専用のサーバに配置
-
pgpool-IIを物理的に独立した専用のサーバに配置する方法です。 分かりやすい方法ですし、他のサーバソフトウェアの影響を受けないのでpgpool-IIをもっとも安全に運営できますが、 サーバ装置を1台余計に増やす必要があるのが欠点です。 また、そのサーバが単一障害点になります(pgpool-IIが単一障害点になることを回避するには、 後述のwatchdogかpgpool-HAを併用します)。
- Webサーバやアプリケーションサーバと同居
-
Apache、JBoss、TomcatなどのWebサーバやアプリケーションサーバが稼働しているサーバに pgpool-IIを同居させる方法です。 この方法では、Webサーバやアプリケーションサーバとpgpool-IIの通信がローカルマシン内になるので、 ソケット通信がマシン間で通信するよりも高速になるメリットがあります。 また、複数のWebサーバ/アプリケーションサーバがあれば、自然と単一障害点を回避できるようになります。 (この場合、複数のpgpool-IIの設定はwatchdog用の設定を除き同じにしてください)。 なお、複数のpgpool-IIが動作しているケースでは以下のような問題が考えられますが、watchdogを有効にすることによって回避できます。したがって、このような構成ではwatchdogを有効にすることを強くおすすめします。
- pgpool-IIとDBサーバの間のネットワークが不安定だと、pgpool-IIから見てDBノード#1がダウン、 他のpgpool-IIから見て正常、というような状態になってしまうことがあります。 ネットワークを二重化するなどして、ネットワーク障害が起きないようにしてください。
- レプリケーションモードで、オンラインリカバリ実行中は、一つのpgpool-IIだけ残して 他のpgpool-IIを落してください。 さもないと、リカバリ後の結果に整合性がなくなる可能性があります。 マスター/スレーブモード+Streaming Replicationモードでは、同時に複数のpgpool-IIで オンラインリカバリを実行しない限り、問題ありません。
- DBサーバと同居
-
PostgreSQLの稼働しているDBサーバと同居させる方法です。 この方法では、pgpool-IIが単一障害点になることがなく、余計なサーバを追加する必要もない点が優れていますが、 アプリケーションがどのDBサーバに接続するのかを自ら判断する必要があるのが欠点です。 この問題を解決するには、watchdogを有効にするか、pgpool-HAと組み合わせて仮想IPを利用します。
pgpool-HAについて
pgpool-HAは、heartbeatなどを利用してpgpool-IIを二重化し、pgpool-II自体の可用性を上げるソフトウェアです。 pgpool-IIと同様、pgpoolプロジェクトのサブプロジェクトであり、pgpoolの開発サイトでOSSとして公開されています。
Watchdog V3.2 ~
watchdog とは
watchdog プロセスは pgpool-II から起動される、高可用性を目的としたプロセスです。 複数の pgpool-II を連携させることで単一障害点を回避します。 watchdog は以下の機能を提供します。
pgpool-II の死活監視
watchdog は pgpool-II の監視を行います。監視の方法は「ハートビート」モードと「クエリ」モードの2つがあります。
- ハートビートモードでは、watchdog はハートビート信号を用いて 他の pgpool-II プロセスの死活監視を行います。 watchdog は、他の pgpool-II の watchdog より定期的に送られるハートビート信号を受け取り、これが一定期間以上途切れた場合には当該 pgpool-II プロセスに障害が発生したと判断します。 冗長性を高めるために、複数のネットワークを用いたハートビート交換が可能です。 デフォルトではこのモードで動作し、これが推奨設定です。
- クエリモードでは、watchdog は pgpool-II のプロセスではなく「サービス」の応答を監視します。 このモードでは、監視対象の pgpool-II にクエリを発行しその応答をチェックします。 この方法では他の pgpool-II から接続を受ける必要があるため、num_init_children が十分大きくない場合には監視が失敗する場合があることに注意してください。 これは非推奨の監視方法であり、下位互換のために残されています。
また watchdog は、pgpool-II から上位のサーバ(アプリケーションサーバなど)への接続も監視し、上位サーバへ pgpool-II のサービスを提供できるかチェックしています。 この監視に失敗した場合には、watchdog は pgpool-II に障害が発生しているとみなしダウンステータスに移行します。
pgpool-II 間の協調動作
watchdog は互いに情報交換を行うことで複数の pgpool-II を協調動作させます。
- フェイルオーバなどでバックエンドノードの状態が変化した場合には、この情報を他の pgpool-II へ伝達し、同期を行います。
- オンラインリカバリ時には、複数の pgpool-II で DB に不整合が生じないよう他の pgpool-II へのクライアントの接続を制限します。
- フェイルオーバ、ファイルバックの際に実行されるコマンド(failover_command, failback_command, follow_master_command)は、インターロック機構により、1つの pgpool-II でのみ実行されます。
障害発生検知時のアクティブ、スタンバイ切り替え
pgpool-II の障害を検知した場合、watchdog は他の watchdog に障害検知を通知します。 故障した pgpool-II がアクティブの場合、他の watchdog は新しいアクティブを投票で決め、 アクティブ・スタンバイの切り替えを行います。
サーバ切り替えと連動した仮想 IP アドレスの自動付け替え
スタンバイが新しいアクティブに昇格する際、新アクティブ機の watchdog は アクティブ用の仮想IPインターフェースを起動します。
一方、旧アクティブ機の watchdog はアクティブ用仮想 IP インターフェースを停止します。 これにより、サーバが切り替わった後もアクティブは同じ IP アドレスでサービスを継続することができます。
サーバ復旧時、スタンバイ機としての自動登録
障害機の復旧や新規サーバを追加する場合、watchdog はサーバの情報を他の watchdog に通知し、 他の watchdog からはアクティブや他のサーバの情報を受け取ります。 これにより追加したサーバはスタンバイ機として自動的に追加されます。
サーバ構成
watchdogプロセスを含むpgpool-IIサーバは以下の図のようなシステム構成をとります。
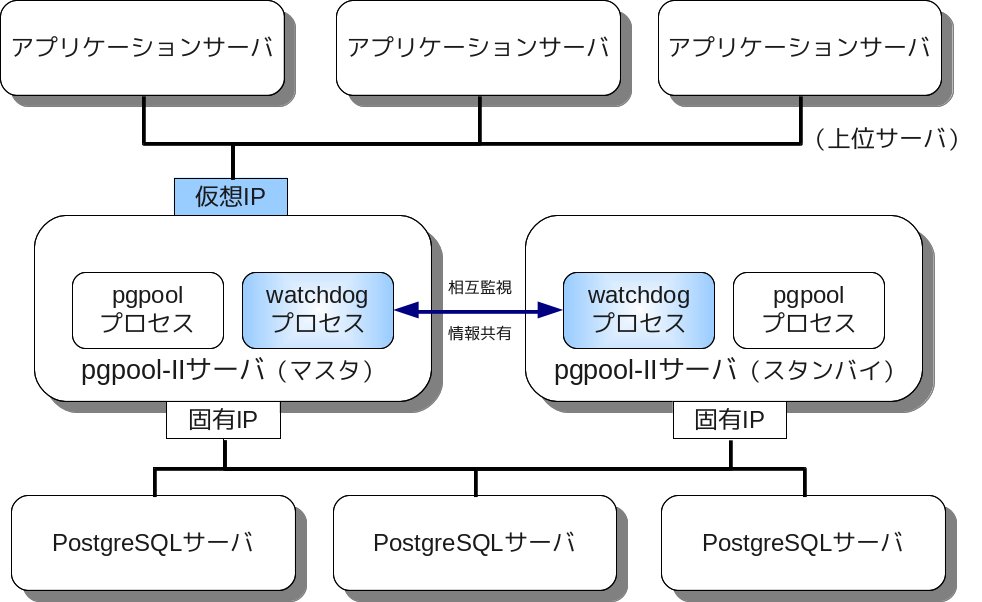
watchdog の起動と停止
watchdog プロセスは pgpool-II の子プロセスとして自動的に起動・停止されますので、固有の起動・停止コマンドはありません。
watchdog は仮想 IP インターフェースの起動・停止を行うため、 root 権限を要求します。 pgpool-II を起動する際に root 権限で実行するのが1つの方法です。 しかし、セキュリティ上の理由からは、sudo や setuid を利用したコマンドを if_up_cmd、 if_up_cmd、if_up_cmd に設定するのがより良い方法です。
watchdog の 死活監視は他の全ての pgpool-II が起動した後に開始されます。 全ての pgpool-II が起動していない状態では監視は行われず、仮想 IP の切り替えも行われません。
pgpool.conf の設定
watchdog プロセスの設定項目は pgpool.conf に記述します。 pgpool.conf.sample ファイルの WATCHDOG セクションにサンプルを記述していますので、参照してください。
watchdog プロセスは以下の項目すべてを指定する必要があります。
有効化
watchdog 間通信
watchdog 間の情報交換に関する設定です。
- wd_hostname V3.2 ~
-
pgpool-II サーバのホスト名または IP アドレスです。 クエリやパケットの送受信の他、watchdog の識別子としても用います。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_port V3.2 ~
-
wachdog 間の情報交換のためのパケットを受信するポート番号を指定します。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_authkey V3.3 ~
-
wachdog 間通信で用いられる認証キーです。 全ての pgpool-II で同じキーを指定する必要があります。 認証キーが異なる watchdog からの通信は拒絶されます。 死活監視をハートビートモードで行う場合には、この認証はハートビート信号にも適用されます。 指定が無い場合には認証は行われず、これがデフォルトです。
このパラメータを変更した時には pgpool-II を再起動してください。
上位サーバへの接続
pgpool-II あるいは PostgreSQL のサービス提供先(DB クライアント)のサーバを、上位サーバと呼びます。 pgpool-II が生きていて PostgreSQL と繋がっている場合でも、 上位サーバとのリンクが切れていればサービスを継続できません。 そのため、watchdog は上位サーバとのリンクが繋がっているかどうかも監視します。
- trusted_servers V3.2 ~
-
上位接続を確認するための信頼できるサーバリストです。 ping の応答が得られる必要があります。 "hostA,hostB,hostC ..." のようにカンマで区切って複数のサーバを指定できます。 全てのサーバへの ping が失敗した場合、watchdog は pgpool-II に障害が発生したと判断します。 そのため、複数のサーバを指定することを推奨します。
指定がない場合は上位サーバへの接続監視は行いません。
このパラメータを変更した時には pgpool-II を再起動してください。
- ping_path V3.2 ~
-
上位サーバへの接続監視に利用する ping コマンドのパスです。 "/bin" のようにパスだけを指定します。
このパラメータを変更した時には pgpool-II を再起動してください。
仮想 IP
仮想 IP の制御に関する設定です。
- delegate_IP V3.2 ~
-
(アプリケーションサーバなど)外部からの接続される pgpool-II の仮想 IP アドレスです。 スタンバイからアクティブに切り替わる際、pgpool-II はこの仮想 IP を引き継ぎます。 このオプションが空の場合には、仮想 IP は起動されません。
このパラメータを変更した時には pgpool-II を再起動してください。
- ifconfig_path V3.2 ~
-
IP アドレス切り替えに利用するコマンドのパスです。 "/sbin" のようにパスだけを指定します。
このパラメータを変更した時には pgpool-II を再起動してください。
- if_up_cmd V3.2 ~
-
仮想 IP を起動するために実行するコマンドです。 "ifconfig eth0:0 inet $_IP_$ netmask 255.255.255.0" のようにコマンドとパラメータを指定します。 $_IP_$ は delegate_IP で指定された IP アドレスに置換されます。
このパラメータを変更した時には pgpool-II を再起動してください。
- if_down_cmd V3.2 ~
-
仮想IPを停止するために実行するコマンドです。 "ifconfig eth0:0 down" のようにコマンドとパラメータを指定します。
このパラメータを変更した時には pgpool-II を再起動してください。
- arping_path V3.2 ~
-
IP アドレス切り替え後に ARP リクエストを送信するコマンドのパスです。 "/usr/sbin" のようにパスだけを指定します。
このパラメータを変更した時には pgpool-II を再起動してください。
- arping_cmd V3.2 ~
-
IPアドレス切り替え後にARPリクエストを送信するコマンドです。 "arping -U $_IP_$ -w 1" のようにコマンドとパラメータを指定します。 $_IP_$ は delegate_IP で指定された IP アドレスに置換されます。
このパラメータを変更した時には pgpool-II を再起動してください。
昇格時の振る舞い
pgpool-II がアクティブ(仮想 IP を保持しているステータス)に昇格した時の振る舞いの設定です。
- clear_memqcache_on_escalation V3.3 ~
-
このオプションが on の場合、pgpool-II がアクティブに昇格した時に、共有メモリ上のクエリキャッシュを全て削除します。 これにより、旧アクティブと非整合な古いクエリキャッシュが使われることを防止します。 memqcache_method が 'shmem' の場合のみ有効です。 デフォルトは on です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_escalation_command V3.3 ~
-
pgpool-II がアクティブに昇格した時に、ここで指定したコマンドが実行されます。 コマンドは、仮想 IP が立ち上がる直前のタイミングで実行されます。
このパラメータを変更した時には pgpool-II を再起動してください。
pgpool-II の死活監視
watchdog は一定時間間隔で pgpool-II の状態のチェック、すなわち死活監視を行います。
共通設定
- wd_lifecheck_method V3.3 ~
-
死活監視の方法を指定します。指定できる値は 'heartbeat' (デフォルト)か 'query' です。
'heartbeat' を指定した場合には、監視は「ハートビートモード」で行われます。 watchdog は一定間隔でハートビート信号(UDP パケット)を他の pgpool-II へ送信します。 また watchdog は他の pgpool-II から送られてくる信号を受信し、これが一定時間以上途絶えた場合にはその pgpool-II に障害が発生したと判断します。
'query' を指定した場合には、監視は「クエリモード」で行われます。 watchdog は監視用のクエリを pgpool-II に発行し、それが成功するかどうかで pgpool-II が生きているかどうかを判断します。
注意: クエリモードを使用する場合は、num_init_childrenに十分大きな値を設定して下さい。watchdog 自身も pgpool-II にクライアントとして接続するためです。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_interval V3.2 ~
-
死活監視を行う間隔(秒)です。 (1 以上の数値) デフォルトの値は 10 です。
このパラメータを変更した時には pgpool-II を再起動してください。
ハートビートモードの設定
- wd_heartbeat_port V3.3 ~
-
ハートビート信号を受信するポート番号を指定します。 ハートビートモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_heartbeat_keepalive V3.3 ~
-
ハートビート信号を送信する間隔(秒)を指定します。 デフォルトは 2 です。 ハートビートモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_heartbeat_deadtime V3.3 ~
-
このオプションで指定された間隔(秒)の間ハートビート信号が途絶えた場合、その pgpool-II に障害が発生したとみなされます。 ハートビートモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- heartbeat_destination0 V3.3 ~
-
ハートビート信号の送り先を、ホスト名か IP で指定します。 複数の送り先が指定可能です。 数値の部分は送り先の番号です。0 からの連番にします。 ハートビートモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- heartbeat_destination_port0 V3.3 ~
-
heartbeat_destinationXに指定したハートビート信号の送り先のポート番号を指定します。 通常は wd_heartbeat_port と同じ値を指定します。 そのポート番号が使用できないホストや、同じホストで複数の pgpool-II を動作させる場合には、異なる値を指定する必要があります。 数値の部分は送り先の番号です。0 からの連番にします。 ハートビートモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- heartbeat_device0 V3.3 ~
-
heartbeat_destinationXに指定した送り先とのハートビートの送受信に用いるネットワークデバイス名を指定します。 数値の部分は送り先の番号です。デバイス毎に 0 からの連番にします。 複数の異なる送り先に同じデバイスを設定することが可能です。 ハートビートモードの場合のみ有効です。空文字列が指定された場合には無視されます。 また、SO_BINDTODEVICE ソケットオプションを使用しているため、pgpool-II が Linux で root 権限で起動している場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
クエリモードの設定
- wd_life_point V3.2 ~
-
監視クエリの応答が得られなかった場合のリトライ回数です。 (1 以上の数値) デフォルトの値は 3 です。 クエリモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_lifecheck_query V3.2 ~
-
pgpool-II の死活監視のために発行されるクエリです。 デフォルトは "SELECT 1" です。 クエリモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_lifecheck_dbname V3.3 ~
-
監視クエリを送る際の接続先のデータベース名です。 デフォルトは 'template1' です。 クエリモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_lifecheck_user V3.3 ~
-
監視クエリを送る際にデータベースに接続するユーザ名です。 デフォルトは 'nobody' です。 クエリモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
- wd_lifecheck_password V3.3 ~
-
監視クエリを送る際にデータベースに接続するパスワードです。 デフォルトでは設定されていません。 クエリモードの場合のみ有効です。
このパラメータを変更した時には pgpool-II を再起動してください。
監視対象サーバ
- other_pgpool_hostname0 V3.2 ~
-
監視対象の pgpool-II サーバのホスト名を指定します。 クエリやパケットの送受信の他、watchdog の識別子としても用います。 数値の部分は監視対象サーバの通し番号です。 監視対象のサーバ毎に 0 からの連番にします。
このパラメータを変更した時には pgpool-II を再起動してください。
- other_pgpool_port0 V3.2 ~
-
監視対象の pgpool-II サーバの pgpool ポート番号を指定します。 クエリモード使用時に、wd_lifecheck_query に指定したクエリがこのポートへ送られます。 数値の部分は監視対象サーバの通し番号です。 監視対象のサーバ毎に 0 からの連番にします。
このパラメータを変更した時には pgpool-II を再起動してください。
- other_wd_port0 V3.2 ~
-
監視対象の pgpool-II サーバの watchdog パケット受信ポート番号を指定します 数値の部分は監視対象サーバの番号です。 監視対象のサーバ毎に 0 からの連番にします。
このパラメータを変更した時には pgpool-II を再起動してください。
watchdog の制限事項
- クエリモード使用時に、PostgreSQL サーバのダウンや pcp_detach_node の実行により pgpool-II から全ての DB ノードが切り離された場合、 watchdog は pgpool-II のサービスがダウンした状態とみなし、watchdog に割り当てられていた仮想 IP は停止されます。 そのため、クライアントは仮想 IP を使って pgpool-II への接続することは出来なくなります。 これは、アクティブの pgpool-II が複数できてしまう「スプリットブレイン」状況を避けるための仕様です。
- ダウン状態の pgpool-II へ 実 IP を使った接続はしないでください。ダウン状態の pgpool-II は watchdog からの 情報を受け取ることが出来ないため、バックエンドの状態が他のpgpool-II と異なっている場合があります。
- ダウン状態の pgpool-II はアクティブまたはスタンバイになることはできません。ダウン状態から復帰するためには pgpool-II を再起動する必要があります。
- アクティブな pgpool-II の停止後、スタンバイ pgpool-II が新しいアクティブに昇格するまでには数秒の時間がかかることに注意してください。 これは、アクティブ pgpool-II の停止を他の pgpool-II に通知する前に、仮想 IP が停止されたことの確認を行っているためです。
PCP コマンド
PCP コマンド一覧
pgpool-II を操作する UNIX コマンドとして、以下のものがあります。
| 情報を取得する PCP コマンド | |
|---|---|
| pcp_node_count | ノード数を取得する |
| pcp_node_info | ノード情報を取得する |
| pcp_watchdog_info | watchdog 情報を取得する V3.3 ~ |
| pcp_proc_count | プロセス一覧を取得する |
| pcp_proc_info | プロセス情報を取得する |
| pcp_pool_status | pgpool.conf のパラメータ設定値を取得する V3.1 〜 |
| pcp_systemdb_info | システム DB 情報を取得する |
| pcp_detach_node | |
| ノード等を操作する PCP コマンド | |
| pcp_detach_node | ノードを切り離す |
| pcp_attach_node | ノードを復帰させる |
| pcp_promote_node | ノードをマスターに昇格させる V3.1 〜 |
| pcp_stop_pgpool | pgpool-IIを停止させる |
| pcp_recovery_node | マスタノードを使ってノードのデータを再同期、ノード起動させる |
共通引数
全てのコマンドには共通する引数があります。これは接続するpgpool-IIの情報や認証情報などです。
ex) $ pcp_node_count [-d] 10 localhost 9898 postgres hogehoge
| 第 1 引数 | タイムアウト値 秒数でタイムアウト値を指定します。 この時間内に pgpool-II から応答がない場合はコネクションを切断して終了します。 なお、このオプションは 2.1 からは無視するようになっています。 |
|---|---|
| 第 2 引数 | pgpool-II が稼動しているホスト名 |
| 第 3 引数 | PCP ポート番号 |
| 第 4 引数 | PCP ユーザ名 |
| 第 5 引数 | PCP パスワード |
オプション引数として、-d があります。
-d が指定されるとデバッグ情報を出力します。
PCPユーザ名とパスワードは ./configure 時に --prefix で指定した
'インストールディレクトリ/etc' にある pcp.conf 内に記述されているものを指定します。
pcp.conf ファイルの場所がデフォルト以外の場所にある場合、
pgpool の -F オプションでその位置を指定することができます。
パスワードはコマンドに渡す時点でmd5化されている必要はありません。
情報を取得するコマンド群
全てのコマンドは、実行した結果が標準出力に表示されます。
pcp_node_count
- 書式
pcp_node_count _timeout_ _host_ _port_ _userid_ _passwd_- 説明
- pgpool-II の pgpool.conf で定義されたノードの総数を表示します。 切り離されているノードの区別はしません。
pcp_node_info
- 書式
pcp_node_info _timeout_ _host_ _port_ _userid_ _passwd_ _nodeid_- 説明
- pgpool-II の pgpool.conf で定義されたノードの情報を表示します。出力結果は以下の例のとおりです。
$ pcp_node_info 10 localhost 9898 postgres hogehoge 0 host1 5432 1 1073741823.500000
結果は以下の順のとおりです。
- 1. ノードのホスト名
- 2. ノードのポート番号
- 3. ステータス
- 4. ロードバランスウェイト
ステータスは [0..3] までの数字で表わされます。各数字の意味は:
- 0 - 初期化時のみに表われる。PCP コマンドで表示されることはない。
- 1 - ノード稼働中。接続無し
- 2 - ノード稼働中。接続有り
- 3 - ノードダウン
ロードバランスウェイトは Normalize されたフォーマットで出力されます。
定義されていないノード ID を指定すると BackendError と表示され、 終了コード 12 で終了します。
pcp_watchdog_info
- 書式
pcp_watchdog_info _timeout_ _host_ _port_ _userid_ _passwd_ [_watchdogid_]- 説明
-
pgpool-II の pgpool.conf の watchdog セクションで定義された pgpool-II の watchdog ステータスを表示します。
_watchdogid_ は other_pgpool_hostname パラメータの添字です。 省略された場合には、_host_:_port_ で動作している pgpool-II の watchdog ステータスが表示されます。
出力結果は以下の例のとおりです。
$ pcp_watchdog_info 10 localhost 9898 postgres hogehoge 0 host1 9999 9000 2
結果は以下の順のとおりです。
- 1. pgpool-II のホスト名
- 2. pgpool-II ポート番号
- 3. watchdog ポート番号
- 4. watchdog ステータス
ステータスは [1..4] までの数字で表わされます。各数字の意味は:
- 1 - 初期化時のみに表われる。指定された pgpool-II が未起動の場合に表示される。
- 2 - スタンバイ: 仮想 IP を保持していない
- 3 - アクティブ: 仮想 IP を保持している
- 4 - ダウン
定義されていない watchdog ID を指定すると BackendError と表示され、 終了コード 12 で終了します。
pcp_proc_count
- 書式
pcp_proc_count _timeout_ _host_ _port_ _userid_ _passwd_- 説明
- pgpool-II の子プロセスのプロセス ID を一覧表示します。複数ある場合は空白文字で区切られます。
pcp_proc_info
- 書式
pcp_proc_info _timeout_ _host_ _port_ _userid_ _passwd_ _processid_- 説明
-
pgpool-II の子プロセス情報を表示します。出力結果は以下の例のとおりです。
$ pcp_proc_info 10 localhost 9898 postgres hogehoge 3815 postgres_db postgres 1150769932 1150767351 3 0 1 14067 1 postgres_db postgres 1150769932 1150767351 3 0 1 14068 1
結果は以下の順のとおりです。
- 1. 接続しているデータベース名
- 2. 接続しているユーザ名
- 3. プロセススタート時刻
- 4. コネクション作成時刻
- 5. プロトコルメジャーバージョン
- 6. プロトコルマイナーバージョン
- 7. コネクション使用回数
- 8. PostgreSQL バックエンドプロセスID
- 9. フロントエンドから接続がある場合は 1、そうでなければ 0
コネクションがバックエンドに対して張られていない場合、データは表示されません。 コネクション情報が複数ある場合、複数行に 1 行 1 コネクション情報で表示されます。 時刻は EPOCH タイムからの秒数で表わされます。
定義されていないプロセスIDを指定するとBackendErrorと表示され、 終了コード 12で終了します。
pcp_pool_status V3.1 〜
- 書式
pcp_pool_status _timeout_ _host_ _port_ _userid_ _passwd_- 説明
-
pgpool.conf のパラメータ設定値を取得します。出力結果は以下のとおりです。
$ pcp_pool_status 10 localhost 9898 postgres hogehoge name : listen_addresses value: localhost desc : host name(s) or IP address(es) to listen to name : port value: 9999 desc : pgpool accepting port number name : socket_dir value: /tmp desc : pgpool socket directory name : pcp_port value: 9898 desc : PCP port # to bind
pcp_systemdb_info
- 書式
pcp_systemdb_info _timeout_ _host_ _port_ _userid_ _passwd_- 説明
-
pgpool-II のシステム DB 情報を表示します。出力結果は以下のとおりです。
$ pcp_systemdb_info 10 localhost 9898 postgres hogehoge localhost 5432 yamaguti '' pgpool_catalog pgpool 3 yamaguti public accounts aid 4 aid bid abalance filler integer integer integer character(84) dist_def_accounts yamaguti public branches bid 3 bid bbalance filler integer integer character(84) dist_def_branches yamaguti public tellers bid 4 tid bid tbalance filler integer integer integer character(84) dist_def_tellers
まず 1 行目にシステム DB の情報が表示されます。結果は以下の順のとおりです。
- 1. ホスト名
- 2. ポート番号
- 3. ユーザ名
- 4. パスワード。空の場合は '' で表示されます。
- 5. スキーマ名
- 6. データベース名
- 7. 分散定義関数の数
2 行目以降は分散定義が表示されます。複数の定義がある場合は、1 つの定義につき 1 行表示されます。 結果は以下の順のとおりです。
- 1. 分散対象のデータベース名
- 2. 分散対象のスキーマ名
- 3. 分散対象のテーブル名
- 4. 分散キーカラム名
- 5. 分散対象テーブル中のカラム数
- 6. カラム名リスト(5. のカラム数分表示されます)
- 7. カラム型リスト(5. のカラム数分表示されます)
- 8. 分散定義関数名
システム DB が定義されていない(pgpool-II モードでない、かつクエリキャッシュがオフの)場合に実行すると、 BackendErrorと表示され、終了コード 12 で終了します。
ノード等を操作するコマンド群
pcp_detach_node
- 書式
pcp_detach_node [-g] _timeout_ _host_ _port_ _userid_ _passwd_ _nodeid_- 説明
-
pgpool-II のノードを切り離します。
-gを指定すると、すべてのクライアントが接続を終了するまでノードを復帰しません。 (ただし、client_idle_limit_in_recovery が -1 あるいは、recovery_timeout が設定されている場合を除く)
pcp_attach_node
- 書式
pcp_attach_node _timeout_ _host_ _port_ _userid_ _passwd_ _nodeid_- 説明
- pgpool-II のノードを復帰させます。
pcp_promote_node V3.1 〜
- 書式
pcp_promote_node [-g] _timeout_ _host_ _port_ _userid_ _passwd_ _nodeid_- 説明
-
pgpool-II のノードをマスターに昇格させます。これは、マスタースレーブモードで ストリーミングレプリケーション構成の場合のみ使用できます。
-gを指定すると、すべてのクライアントが接続を終了するまでノードを復帰しません。 (ただし、client_idle_limit_in_recovery が -1 あるいは、recovery_timeout が設定されている場合を除く)
pcp_stop_pgpool
- 書式
pcp_stop_pgpool _timeout_ _host_ _port_ _userid_ _passwd_ _mode_- 説明
pgpool-IIを指定されたモードでシャットダウンします。指定できるモードは以下のとおりです。
- s - smart モード
- f - fast モード
- i - immediate モード
pgpool-II が起動していない場合は ConnectionError と表示され、 終了コード 8 で終了します。
※ 現在は fast モードと immediate シャットダウンの処理に区別はありません。 命令を送った時点でクライアントがいる・いないに関わらずシャットダウン処理を即座に行います。
pcp_recovery_node
- 書式
pcp_recovery_node _timeout_ _host_ _port_ _userid_ _passwd_ _nodeid_- 説明
- pgpool-II のノードをデータを再同期させた上で復帰させます。
終了ステータス
PCPコマンドは正常に処理を終了した場合、ステータス'0'で終了します。エラーが起 きた場合は以下のステータスにより終了します。
| UNKNOWNERR | 1 | 不明なエラー |
|---|---|---|
| EOFER | 2 | EOFエラー |
| NOMEMERR | 3 | メモリ不足 |
| READERR | 4 | サーバからのデータ読み込みエラー |
| WRITEERR | 5 | サーバへのデータ書き込みエラー |
| TIMEOUTERR | 6 | タイムアウト |
| INVALERR | 7 | PCPコマンドへの不正なオプション |
| CONNERR | 8 | サーバ接続エラー |
| NOCONNERR | 9 | 接続が存在しない |
| SOCKERR | 10 | ソケットエラー |
| HOSTERR | 11 | ホスト名解決エラー |
| BACKENDERR | 12 | サーバでのPCP処理エラー。存在しないプロセスIDの情報を取得しようとした場合など |
| AUTHERR | 13 | 認証エラー |
トラブルシューティング
この章では、pgpool-IIを運用中に直面しやすい障害と、その対策方法をケース別に説明します。
- health check failed
-
ヘルスチェックでpgpool-IIがDBノードの障害を検出しました。
2010-07-23 16:42:57 ERROR: pid 20031: health check failed. 1 th host foo at port 5432 is down 2010-07-23 16:42:57 LOG: pid 20031: set 1 th backend down status 2010-07-23 16:42:57 LOG: pid 20031: starting degeneration. shutdown host foot(5432) 2010-07-23 16:42:58 LOG: pid 20031: failover_handler: set new master node: 0 2010-07-23 16:42:58 LOG: pid 20031: failover done. shutdown host foo(5432)
このログは、DBノード1(ホスト名 foo)がダウンして切り離され、 新しくDBノード0がマスタとして扱われ出したことを示しています。 DBノード1をチェックし、異常原因を取り除いた後に、可能であればオンラインリカバリ機能を使っ てDBノード1を復帰させてください。
- failed to read kind from frontend
-
2010-07-26 18:43:24 LOG: pid 24161: ProcessFrontendResponse: failed to read kind from frontend. frontend abnormally exited
pgpool-IIから見てクライアントが突然セッションを切断した際にこのようなログが残ります。 原因としては、アプリケーションのバグ、アプリケーションが強制終了された、 やネットワークの一時的な障害が考えられます。 このログが出ても、DBが壊れるとか一貫性がなくなるような問題は起きませんが、 継続してこのログが出力されるようであれば、アプリケーションやネットワークの障害を調査することをおすすめします。
- kind mismatchエラー
-
レプリケーションモードで運用している場合に出ることがあるエラーです。
2010-07-22 14:18:32 ERROR: pid 9966: kind mismatch among backends. Possible last query was: "FETCH ALL FROM c;" kind details are: 0[T] 1[E: cursor "c" does not exist]
pgpool-IIは、SQLコマンドを各DBノードに送信したら、各DBノードから同じレスポンスが返ってくることを期待します。 このエラーは、異なるレスポンスが返ってきたことを示します。 Possible last query was:のあとに、このエラーを返す原因となった問い合わせのSQL文が表示されます。 そのあとで、各DBノードからのレスポンスの種類と、レスポンスがエラーの場合は、 PostgreSQLのエラーメッセージが表示されます。 ここでは、"0[T]"により、0番目のDBノードが"T"(行情報の開始)という応答を返したこと、 一方"1[E"で、DBノード1がエラーを返したとこと、そのエラーメッセージは 「cursor "c" does not exist」であったことがわかります。
注意: このエラーは、マスタースレーブモードでも出ることがあります。 たとえば、SETコマンドは、各セッションの状態を同じにするために、基本的にすべてのDBノードに送信されるからです。
データベースを調べて原因を特定し、もしDBの同期が崩れているようであれば、 オンラインリカバリを使って正しいデータと同期させてください。
- pgpool detected difference of the number of inserted, updated or deleted tuples
-
レプリケーションモードにおいて、pgpool-IIが、DBノード間でINSERT/UPDATE/DELETEが返す結果行の違いを検出しました。
2010-07-22 11:49:28 ERROR: pid 30710: pgpool detected difference of the number of inserted, updated or deleted tuples. Possible last query was: "update t1 set i = 1;" 2010-07-22 11:49:28 LOG: pid 30710: ReadyForQuery: Degenerate backends: 1 2010-07-22 11:49:28 LOG: pid 30710: ReadyForQuery: Affected tuples are: 0 1
この例では、update t1 set i = 1によって更新された行数が、DBノードで異なっています。 また、次の行では、DBノード1を切り離したこと、更にDBノード0での結果行数が0だったのに対して、DBノード1では、1行だったことを表しています。
正しくないデータを持っていると思われるDBノードを停止し、オンラインリカバリを使って 正しいデータと同期させてください。
制限事項
PostgreSQLの機能
- pg_terminate_backend()でバックエンドを終了させるとフェイルオーバしてしまいます。 これは、PostgreSQLがpostmasterをシャットダウンしたときと同じメッセージをpgpoolに送るためです。 今のところ対応方法はないので、この関数を使わないようにしてください。
認証・アクセス制御方式
- レプリケーションモードまたマスタ/スレーブモード時にはtrust, reject, clear
text password, pam, 認証方式だけが利用できます。
crypt認証は利用できません。
md5認証に関しては、PostgreSQLに該当ユーザをmd5認証付でPostgreSQLに登録し、
次にpgpoolに付属するpg_md5コマンドを使って、pool_passwdという認証ファイルを作成することにより
利用できるようになります。
pool_passwdは認証ファイルのデフォルトのファイル名です。
ファイル名はpool_passwdで変更することができます。
- DBユーザのアカウントでログインし、"pg_md5 --md5auth パスワード" または "pg_md5 --md5auth --username=ユーザ名 パスワード" を実行します。
- md5により暗号化されたユーザ名とパスワードがpool_passwdに登録されます。 pool_passwdがまだ存在しなければ、pgpool.confと同じディレクトリ内に作成されます。
- pool_passwdのフォーマットは、"ユーザ名:パスワード"となっています。
- pool_hba.confにmd5認証のエントリを作成します。 pool_hba.confについては、クライアント認証(HBA)のためのpool_hba.conf設定方法 を参照してください。
- 注意事項: pool_passwdに登録するパスワードは、PostgreSQLに登録したパスワードと 完全に同じでなければなりません。
- pool_passwdとPostgreSQLのmd5パスワードを変更したら、pgpool reload を実行してください。 pgpool-II 3.1またはそれよりも以前のバージョンでは、pgpool-IIの再起動が必要です。
- それ以外のモードでは、trust, reject, clear text password, pam, crypt, md5認証方式だけが利用できます。
一時テーブルの扱い
制限対象:マスタースレーブモード
一時テーブルの作成、更新は常にマスタ(primary)で行なわれます。 一時テーブルの検索も、pgpool-II 3.0以降では、マスタで行なわれるので、 一時テーブルを使っているかどうかを意識する必要はありません。 ただし、文字列として一時テーブル名をSELECTの中で使っている場合は一時テーブルかどうかの確認のしようがないので、 負荷分散されてしまい、その一時テーブルが見つからないか、 もしくは同じ名前の別のテーブルを検索してしまうことになります。 そのような問い合わせは避けるか、/*NO LOAD BALNCE*/のコメントを挿入してください。
SELECT 't1'::regclass::oid;
ちなみに、psqlの\dコマンドのように、システムカタログを問い合わせる中で 文字列としてのテーブル名を使っている場合は、pgpool-II 3.0以降ではマスタで検索が行なわれるので、問題になりません。 なぜなら、システムカタログへの検索は常にマスタで行なわれるからです。
レプリケーションモードで注意が必要な関数など
pgpool-IIでは同じ問い合わせを送っても異なる結果を返すようなデータ、 たとえば乱数やトランザクションID、OIDのようなものに関してはレプリケーションはしますが、 2台のホストでまったく同じ値がコピーされる保証はありません。
シリアル型に関しては、insert_lockを有効にしておけばテーブルロックを利用して同期が取られます。 シーケンスを扱う関数をSELECT setval()、SELECT nextval()で呼び出している場合は 自動的にレプリケーションされるので同期が取れます。
pgpool-II 2.3以降では、テーブルのデフォルト値での利用も含め、 CURRENT_TIMESTAMP, CURRENT_DATE, now()は、自動的にマスタ側から取得した時刻値に置き換えることによって レプリケーションできるようになっています。 ただし、以下の点に注意してください。
-
pgpool-II 3.1より前のバージョンではDEFAULTにタイムスタンプを返す式が
含まれているかどうかの判定は正確ではありません。例えば
CREATE TABLE rel1( d1 date DEFAULT CURRENT_DATE + 1 )
のようなものも現在のタイムスタンプとして書き換えを行います。 pgpool-II 3.1以降では、拡張プロトコルとPREPARE以外の場合にこの点が改善されており、 上記の例にあるような例も正しく処理されます(つまり、デフォルト値として明日の日付がセットされます)。なお、列の定義が、
foo bigint default (date_part('epoch'::text,('now'::text)::timestamp(3) with time zone) * (1000)::double precision)のように、データ型が日付、時刻以外になっている場合は書き換えは行ないません。
- INSERT ... SELECTでは、列のDEFAULTに対する書き換えを行いません。例えば、
CREATE TABLE rel1( c1 int, c2 timestamp default now() )
の時、INSERT INTO rel1(c1) VALUES(1)
はINSERT INTO rel1(c1, c2) VALUES(1, '2009-01-01 23:59:59.123456+09')
のように書き換えられますがINSERT INTO rel1(c1) SELECT 1
は書き換えられません。
PostgreSQL 8.2かそれより前のPostgreSQLをお使いの場合、 CREATE TEMP TABLEで作成されたテーブルはフロントエンドがセッションを終了しても削除されません。 これは、コネクションプールの効果でバックエンドから見るとセッションが継続しているように見えるからです。 セッションの終了時に明示的にDROP TABLEするか、トランザクションブロックの中で CREATE TEMP TABLE ... ON COMMIT DROPをお使い下さい。
PostgreSQL 8.3以降では、reset_query_listにDISCARD ALLを指定すれば自動的に削除されるので問題ありません。
クエリについて
pgpool-II では扱うことができないクエリについて説明します。
マルチバイト文字について
制限対象:全モード
現在の実装では、マルチバイト文字の変換処理を行いません。 クライアントエンコーディング、バックエンドノードのサーバエンコーディング、システムDB のサーバエンコーディングを一致させるようにしてください。
マルチステートメント
制限対象:全モード
マルチステートメント(';' で区切って複数の文をまとめた SQL)を pgpool が 正しく処理することができません。必ず文を分けて送信してください。
なお、psql を使って pgpool に接続した場合は、psql 内部でマルチステートメントを分解し、 1 つずつ送信するので、実際には問題になりません。
拡張問い合わせプロトコル
制限対象:パラレルモード
JDBC ドライバなどのような拡張問い合わせプロトコルには対応していません。 必ず簡易問い合わせプロトコルを使用してください。
SELECT
制限対象:パラレルモード
postgresql.conf の add_missing_from 設定値を off (デフォルト値)に設定してください。 add_missing_from 設定値が on の時に使えるクエリは正しくpgpoolで処理されない可能性 があります。
INSERT
制限対象:パラレルモード
データ分割をしているテーブルに対して INSERT を行う際には、分割ルールとなる値を
DEFAULT にはできません。
例えばテーブル t のカラム x が分割ルールの対象カラムだった場合には、
INSERT INTO t(x) VALUES (DEFAULT);
とはできません。また、以下の様に分割ルールとなる値が関数呼び出しの場合も 対応していません。
INSERT INTO t(x) VALUES (func());
このカラムには必ず明示的に値を与える必要があります。
また、SELECT INTO、 INSERT INTO ... SELECT、および以下のような
VALUES を用いた複数行の挿入には対応していません。
INSERT INTO t(x) VALUES (1),(2),(3);
UPDATE
制限対象:パラレルモード
分割ルールとなるカラムを更新すると分割ルールに従ったデータの整合性が崩 れる可能性があります。pgpool-II では特にデータの再配置ということは行い ません。
もし制約違反などにより一部のノードでエラーになった場合にロールバックす ることはできません。
WHERE 句にデータ分割を行ったテーブルを参照するサブクエリや関数呼び出しがある場合には正しく動かない可能性が あります。
例:UPDATE branches set bid = 100 where bid = (select max(bid) from beances);
SELECT ... FOR UPDATE
制限対象:パラレルモード
WHERE 句にデータ分割を行ったテーブルを参照するサブクエリや関数呼び出しがある場合には正しく動かない可能性が あります。
例:SELECT * FROM branches where bid = (select max(bid) from beances) FOR UPDATE;
COPY
制限対象:パラレルモード
COPY BINARY には対応していません。また、ファイルからのコピーにも対応していません。 COPY FROM STDIN と COPY TO STDOUT のみ対応しています。
ALTER/CREATE TABLE について
制限対象:パラレルモード
pgpool に情報を更新させるためには、pgpool を再起動する必要があります。
トランザクション
制限対象:パラレルモード
トランザクション中に発行される SELECT は dblink を経由する場合には別ト ランザクションになります。以下に例を示します。
BEGIN; INSERT INTO t(a) VALUES (1); SELECT * FROM t ORDER BY a; <-- 上の INSERT した値は見えない END;
また制約違反などにより一部のノードでエラーになった場合にロールバックすることはできません。
View/Rule
制限対象:パラレルモード
View や Rule は各ノードに同じ内容が定義されます。
CREATE VIEW sample AS SELECT * FROM a, b where a.i = b.i
上記のような テーブル結合を含んだVIEWは、a と b は同じノード内でのみ結合処理を行い、 各ノードからの実行結果を統合します。ノードをまたがった JOIN を行う View を作成することはできません。 Rule についても同様になります。
ただし、データ分割したテーブルを同じノード内でのみ結合したい場合に、VIEWを作成することは可能です。 この場合にはVIEWをpgpool_catalog.dist_defテーブルにVIEWを登録しておきます。
また、pgpool_catalog.dist_defテーブルのcol_nameとdist_def_funcには、 VIEWで定義したカラムとVIEWに対してINSERTが発行された場合に 何処のノードにクエリを問い合わせるのかを決定する関数を登録してください。
関数/トリガについて
制限対象:パラレルモード
関数は各ノードに同じ内容が定義されます。関数内で JOIN や他のノードのデータ操作を行うことはできません。
Natural Join について
制限対象:パラレルモード
Natural Join は利用できません。ON 結合条件または、USING(結合カラム) を明示的に 指定する必要があります。
USING 句について
制限対象:パラレルモード
JOIN 構文の中で利用される USING 句はクエリの書き換え処理によって ON 句に変換されます。 そのため、ターゲットリストに "*" を利用する問い合わせを行う場合には、同じ列名が出力されます。
デッドロックについて
制限対象:パラレルモード
ノード間をまたがるデッドロックを検出することができません。
例:accountsテーブルは以下のルールで分割されている。
aid <= 100000 ノード 0
aid >= 100000 ノード 1
A) BEGIN;
B) BEGIN;
A) SELECT * FROM accounts WHERE aid = 100001 FOR UPDATE;
B) SELECT * FROM accounts WHERE aid = 100000 FOR UPDATE;
A) SELECT * FROM accounts WHERE aid = 100000 FOR UPDATE;
B) SELECT * FROM accounts WHERE aid = 100001 FOR UPDATE;
この場合、単一のノードではデッドロックを検知できないため、pgpool は待 たされた状態になります。この現象は SELECT FOR UPDATE 以外にも行ロック を獲得するクエリで発生する可能性があります。
また、あるノードでデッドロックが発生した場合は、各ノードのトランザクショ ンの状態が異なる状況になります。そのため、デッドロックを検知した時点で 以下のログを出力して pgpool は該当のプロセスを終了させます。
pool_read_kind: kind does not match between master(84) slot[1] (69)
スキーマについて
制限対象:パラレルモード
public 以外のスキーマに属すようなオブジェクトの参照は必ず
スキーマ.オブジェクト
と指定するようにしてください。
set search_path = xxx
を指定し、スキーマ名を省略すると、pgpool がどの分散ルールを適用するか 判断できません。
テーブル名、カラム名について
制限対象:パラレルモード
pool_で始まるテーブル、カラム名は使えません。クエリ書き換えの際に内部処理で使用します。
システム DB
分割ルール
pgpool-II では分割ルールの対象のカラムは 1 つのみとします。x と y の OR 条件などといったものには対応していません。
ビルドに必要な環境
libpq
pgpool-II では libpq をリンクします。libpq のバージョンは 2.0 の場合、 configure に失敗します。必ず libpq 3.0 以降(PostgreSQL 7.4以降) をリンクするよ うにしてください。また、SystemDB のバージョンも PostgreSQL 7.4 以降が 必須になります。
クエリキャッシュ
ディスク上のクエリキャッシュ機能では、キャッシュの無効化を手動で行う必要があります。 オンメモリクエリキャッシュ機能にはこの制限は当てはまりません。
内部情報
pgpool-IIバージョン 2.0 以降では、1.x バージョンと比べ大幅な改良が加えられています。 1.x バージョンの情報とは互換性がないので注意してください。
パラレル実行エンジン
pgpool-IIにはパラレル実行エンジンが組み込まれています。
このエンジンは、パラレルモードのときに、各ノードに同じクエリを問い合 わせ、ノードの応答順に結果をフロントエンドに送信するエンジンのことを 指します。
クエリ書き換え
パラレルモードでpgpool-IIが行うクエリ書き換えについて説明します。
パラレルモードでは、クライアントが送信した検索系(SELECT処理)の問い合わせは、 大きく分けて以下の 2 つの処理を行います。
- クエリの解析
- クエリの書き換え
これら2つの処理について順に説明致します。
クエリの解析
はじめに
クライアントが送信した検索系の問い合わせは、SQLパーサを通してからシステムDBに登録されている情報を もとにクエリ解析を行います。クエリの解析には実行ステータスの遷移で評価しています。
ここで実行ステータスというのは、あるデータの集合が何処で取得または処理できるのか判断するものです。 例えば、pgpool_catalog.dist_defテーブルに登録されているテーブルのデータ集合全体は、 データが分割されているのですべてのノードから取得する必要があります。 逆に、pgpool_catalog.replicate_defテーブルに登録されているテーブルのデータ集合全体は、 すべてのノードから取得するのではなく、いずれかのノード から取得すれば十分です。
ここで実行ステータスというのは、あるデータの集合が何処で取得または処理できるのか判断するものです。 ここですべてのノードで処理する必要がある状態を P 状態、一つのノードで処理する必要がある状態を L 状態として定義します。
ここで実行ステータスというのは、あるデータの集合が何処で取得または処理できるのか判断するものです。 もう一つ、特別な状態として S 状態があります。 これは、すべてのノードから取得した全データに対して処理を行ったときの状態のことを示します。
ここで実行ステータスというのは、あるデータの集合が何処で取得または処理できるのか判断するものです。 例えば、ソート処理です。pgpool_catalog.dist_defテーブルに登録されている テーブルのデータに対するソート処理は、すべてのノードからデータを取得した後に実行する必要があります。
検索系クエリは、以下の処理順に解析され、実行ステータスが遷移していきます。 実行ステータスが遷移していく過程で S 状態となると、以降の処理は必ず S 状態となります。 そして最後のSELECTの最終実行ステータスの状態により、何処のDBで処理されるかが決定します。
- UNION、EXTRACT、INTERCECTが利用されているかどうか
- FROM 句の実行ステータス
- TARGETLIST による実行ステータスの変化
- WHERE 句 にる実行ステータスの変化
- GROUP BY 句による実行ステータスの変化
- HAVING 句による実行ステータスの変化
- ORDER BY 句による実行ステータスの変化
- LIMIT OFFSET 述語に実行ステータスの変化
- SELECTの最終実行ステータスの取得
SELECTの最終実行ステータスと処理される場所との関係は、以下のとおりです。
| 実行ステータス | 処理される場所 |
|---|---|
| L | いずれかのノードに問い合わせを行う |
| P | すべてのノード同じ問い合わせを行い、パラレル実行エンジンを通してクライアントに返却 |
| S | システムDBで処理を行った後にクライアントに返却 |
またサブクエリに対しても上記のルールが適応されます。 以下の単純なクエリでは、p1-tableがシステムDBのpgpool_catalog.dist_defテーブルに登録されている場合、 つまりデータの分割が 行われている場合には、サブクエリの最終実行ステータスが P となり、 その結果サブクエリの呼び出し元である SELECT の実行ステータスも P となります。
SELECT * FROM (SELECT * FROM P1-table) as P2-table;
次に具体的に実行ステータスがどのように遷移するのか説明します。 まず2. From句の実行ステータス から説明します。
FROM 句の実行ステータス
検索系クエリ(SELECT)は FROM 句によりデータの集合を定義します。 FROM句から構成せれるデータ集合は P 状態, L 状態、または S 状態を取ります。 FROM句に指定しているテーブルが一つの場合には、単純にテーブルの実行ステータスが FROM句から構成されるデータ集合全体の実行ステータスとなります。 FROM句に複数のテーブル、又はサブクエリがある場合 には、結合方法によって以下のように実行ステータスが決定します。
| 結合方式 | LEFT OUTER JOIN | RIGHT OUTER JOIN | FULL OUTER JOIN | その他 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 左\右 | P | L | S | P | L | S | P | L | S | P | L | S |
| P | S | P | S | S | S | S | S | S | S | S | P | S |
| L | S | L | S | P | L | S | S | L | S | P | L | S |
| S | S | S | S | S | S | S | S | S | S | S | S | S |
以下の例では、P1-tableが P 状態のテーブルでL1-table,L2-tableが L 状態のテーブルだとします。 すると上記の表により、P1-table (左)とL1-table (右) が結合し P 状態となり、 さらに P 状態と L 状態のL2-tableが結合してFROM句の実行ステータスは P 状態となります。
SELECT * FROM P1-table,L1-table,L2-table;
TARGETLIST と WHERE句の実行ステータス
基本的なクエリでは、FROM 句と同じ実行ステータスを継承します。 しかし、TARGETLIST と WHERE句の実行ステータスは、以下の場合に変化します。
- サブクエリがある場合
- FROM句が P 状態の場合、かつ、TARGETLISTに集約関数、DISTINCTがある場合
- FROM句で定義したテーブル(データ集合)に存在しないカラムが使われている場合
サブクエリの最終実行ステータスが P 状態、または、S 状態の場合には、 TARGETLIST、WHERE句の実行ステータスは、S 状態となります。 下記の例では、サブクエリで使われているテーブルが、P 状態の場合には、 サブクエリの最終実行ステータスはP 状態となります。 そのため L1-tableの実行ステータスに依存せずに、WHERE句の実行ステータスは S状態となり、 このクエリの実行場所はシステムDBとなります。
SELECT * FROM L1-table WHERE L1-table.column IN (SELECT * FROM P1-table);
FROM 句が P 状態の場合、かつ、TARGETLISTに集約関数がある場合は、 データを取得後に集計する必要があるため、S状態に遷移します。 また、特定の条件の下では、集約関数による最適化が行われます。
FROM句で定義したテーブル、サブクエリには存在しないカラムがWHERE句に使われている場合があります。 これは以下のような相関サブクエリ内で発生します。
SELECT * FROM L1-table WHERE L1-table.col1 IN (SELECT * FROM P1-table WHERE P1-table.col = L1-table.col1);
上記のサブクエリに使われている L1-table.col1は、L1-tableを外部参照しています。 この場合にサブクエリのWHERE句の実行ステータスは S 状態となります。
GROUP BY 句、HAVING 句、ORDER BY 句、LIMIT OFFSET 述語の実行ステータス
WHERE句の実行ステータスが P 状態の場合に、GROUP BY , HAVING 句、ORDER BY 句、 LIMIT OFFSET 述語があるとS状態に遷移します。 GROUP BY句が存在しないクエリはWHERE句の実行ステータスを継承します。 また、HAVING句が無い場合にはGROUP BY 句の実行ステータスを継承します。 ORDER BY 句、LIMIT OFFSET 述語も同様です。
UNION、EXTRACT、INTERSECTが使われている場合
UNION、EXTRAT、INTERSECTが使っているクエリは左側のSELECT文と右側のSELECT文の最終実行ステータスに依存します。 左側と右側のSELECT文の最終実行ステータスが共に L 状態の時には、L 状態となります。
また、左側と右側のSELECT文の最終実行ステータスが共に P 状態、かつUNION ALLの場合には P 状態となります。 その他の組み合わせの場合には、S状態となります。
SELECTの最終実行ステータスの取得
実行ステータスがすべて L 状態の場合にはL状態、すべて P 状態の場合には、P 状態となります。 それ以外は、S 状態となります。
L 状態の場合には、pgpool.confのloadbalance_modeがtrueの場合には負荷分散され、 それ以外の場合にはMASTERに問い合わせを行います。
また、P 状態の場合には、パラレル実行エンジンを使って並列処理が行われます。 S 状態の場合には、次のフェーズであるクエリ書き換えを行います。
クエリ書き換え
クエリの解析フェーズで取得した実行ステータスを使ってクエリの書き換えを行います。 例として P 状態の P1-table と L 状態の L1-table を使ったクエリで説明します・
SELECT P1-table.col, L1-table.col FROM P1-table,L1-table where P1-table.col = L1-table.col order by P1-table.col;
このクエリでは ORDER BY 句があるため S 状態となり、FROM句、WHERE句、TARGETLISTは P 状態となります。 このようなクエリでは以下のように書き換えられます。
SELECT P1-table.col, L1-table.col FROM
dblink(select pool_parallel(SELECT P1-table.col, L1-table.col FROM P1-table,L1-table where P1-table.col = L1-table.col))
order by P1-table.col;
ここでdblinkはpgpool-IIに問い合わせを送信します。 また、pool_parallelは引数のクエリをパラレル実行エンジンをにわたす関数です。 なお、上記はあくまでイメージであり実際に実行可能なクエリではありません。
上記の例のように、FROM句、WHERE句、TARGETLISTがすべて P 状態の場合には、 FROM句、WHERE句、TARGETLISTをまとめて並列処理を行います。
次の例を見てみます。
SELECT L1-table.col FROM L1-table WHERE L1-table.col % 2 = 0 AND L1-table.col IN (SELECT P1-table FROM P1-table) ;
この例では、FROM 句は L 状態、TARGETLISTも L 状態、WHERE句は P 状態のサブクエリを持っているため S 状態となります。 これは以下のように書き換えが行われます。
SELECT L1-table.col FROM dblink(SELECT loadbalance(SELECT L1-table.col FROM L1-table WHERE L1-table.col % 2 = 0 AND TRUE))
WHERE
L1-table.col %2 = 0 AND
L1-table.col IN
(
SELECT P1-Table FROM
dblink(select pool_parallel(SELECT P1-table FROM P1-table))
) ;
ここで、pool_loadbalanceはクエリをいずれかのノードに送信する関数です。
集約によるクエリ書き換え
集計を行うクエリ(集約関数、GROUP BY )は各ノードに計算させ、システムDBで再集計を行うことにより、 システムDBの負荷を減らしパフォーマンスも向上します。
まず、最初にpgpool-IIが実際に行うクエリの書き換えを見てみます。
FROM 句が P 状態で count(*) を使ったクエリは、以下のように書き換えが行われます。
select count(*) from P1-table;
-> クエリ書き換え
SELECT
sum(pool_c$1) as count
FROM
dblink(select pool_parallel('select count(*) from P1-table'))
AS pool_$1g (pool_c$1 bigint);
各ノードでcount(*) を計算した後に、システムDBで集計(sum)をすることによ り、目的が達成できます。
上記のようなクエリ書き換えが行われる条件は以下の場合です。
- FROM 句がP 状態
- ターゲットリストに集約関数(count, sum, min, max,avgのみ対応),GROUP BYに指定したカラムが使われている
- WHERE 句がP 状態
- HAVING 句 に使われている集約関数(count, sum, min, max,avgのみ対応), FROM句で定義されているカラム,GROUP BYに指定したカラムのみ使われている。
例) select P1-table.col,L1-table.col,count(*),avg(P1-table.col) from P1-table,L1-table wehre P1-table.col %2 = 0 group by P1-table.col,L1-table.coli having count(*) < 100
パラレルモードの注意事項
パラレルモードでは、クエリの解析の際にカラム名とタイプが必要になります。 そのため、サブクエリのTARGETLISTに式、関数を使っている場合には別名と型名をキャストでつける必要があります。 式、関数に型のキャストがない場合には、text型として処理されますので注意してください。
なお、集約関数の場合でかつ集約によるクエリ書き換えが行われる場合には、countはbigint型、sumはnumeric型となります。 min,maxの場合には、引数が日付型の場合には日付型として計算され、それ以外はnumericとして計算されます。 avgはsum/countとして処理されます。
パラレルモードのパフォーマンスについて
SELECTの最終実行ステータスとパフォーマンスのおおよその目安は以下のとおりです。
| 実行ステータス | パフォーマンス |
|---|---|
| L | パラレルクエリを利用しないのでpgpool-IIのオーバーヘッドを除き、単体ノードとの性能劣化はない |
| P | 並列処理を行うので高速、特にシーケンシャルスキャンの場合には効果がでる。また、データを分割することでテーブルサイズ(/1台)が小さくなることによりキャッシュに乗りやすくなる |
| S | 集約によるクエリ書き換えが行われると高速 |
リリースノート
3.3.2 (tokakiboshi) 2013/11/29
概要
このバージョンは 3.3.1 に対するバグ修正リリースです。
バグ修正
- レプリケーションモード稼働時、一部のタイムゾーンでタイムスタンプの書き換えが誤っていました。(Tatsuo Ishii)
タイムスタンプの書き換え処理では、現在日時を取得するあめに "SELECT now()" を実行します。 しかし一部のタイムゾーンにおいては、"02:30" のような場合に現在日時のためのバッファの大きさが 十分ではありませんでした。"0900" のように 30 分刻みでのタイムゾーンでないときは、この問題は発生しません。 そのため、これまでこの不具合が報告されたことはありませんでした。
この不具合は [pgpool-general: 2113] で報告され、Sean Hogan さんによって修正が提供されました。
- installer: redhat/rpm_installer/getsources.sh での pgpoolAdmin の バージョン指定方法を修正しました。 (Yugo Nagata)
- Makefile: Makefiles 内の pg_config を $(PG_CONFIG) に置き換えました。
したがって、PostgreSQL のメジャーバージョンが異なる場合には、コンパイル中で上書きされるようになります。(Tatsuo Ishii)
パッチは Christoph Berg さんから提供されました。([pgpool-general: 2127])
- watchdog:
-Werror=format-securityをつけてコンパイルしたときの、warning/error を修正しました。(Tatsuo Ishii)パッチは Christoph Berg さんから提供されました。([pgpool-general: 2127])
- configure: FreeBSD で問題があったため、-lcompat を削除しました。(Tatsuo Ishii)
bug#15 で報告されました。
- pgpool.conf で log_standby_delay を設定してないときに
segfault していたのを修正しました。(Tatsuo Ishii)
これは、pool_config.l での log_standby_delay の初期化が誤っていたためです。 bug#74 として報告されました。
- doc: パラレルモードの制限事項を追記しました。VALUES 句を使った複数行の INSERT はパラレルモードではサポートされていません。(Yugo Nagata)
- スタンバイノードがダウンしようとしているときに find_primary_node_repeatedly() が
呼ばれないようにしました。(Tatsuo Ishii)
これによってフェイルオーバの所要時間が短くなります。 bug#75 として報告され、 パッチを Tatsuo Ishii が編集しました。
- レプリケーションモードと拡張プロトコルを組み合わせた場合に、
データ不整合があったのでこれを修正しました。(Tatsuo Ishii)
JDBC ドライバを使った同時 INSERT で、ノード間でのデータ不整合があるという報告がありました。 この事象は以下の条件で必ず発生します。
- レプリケーションモードを使用している
- 拡張プロトコルを使用している
- parse で作成された portal が bind で再利用される
- autocommit が on である
- SERIAL(シーケンス)を使用している
pgpool-II の parse 関数は、クライアントが INSERT (+ 5 の状態)を発行すると、対象テーブルをロックされていることを 認識しています。しかし、bind 関数はそれを認識していませんでした。 一度 parse / bind / execute が完了すると、pgpool は 4 の理由により parse で獲得したロックを解放します。 そして JDBC は portal を再利用しようとし、ロックを獲得しないまま bind からのサイクルを開始してしまいます。 その結果、ロックのない INSERT がノード間でのデータ不整合を引き起こします。 この解決方法としては、bind でテーブルをロックするようにしました。
この問題は、たいていのユーザは JDBC を autocommit = off で使っているために、 今まで報告されることがありませんでした。off であれば、ユーザが commit / rollback を発行するまで、 parse によるロックが残存するためです。
この不具合は Steve Kuekes さんにより、[pgpool-general: 2142] で報告されました。
- クエリキャッシュにおけるメモリ確保サイズの不具合を修正しました。(Tatsuo Ishii)
execute() において、メモリ確保サイズが一部の場合において小さすぎました。
- クエリキャッシュ + 拡張プロトコルの組み合わせで使っている場合に、segfault する可能性があったのを
修正しました。(Tatsuo Ishii)
クエリが "cache safe" でないときに、bind_msg->param_offset が Bind() でセットされていませんでした。 しかし Execute() では無条件に bind_msg->param_offset を使おうとしていました。
この不具合は bug#76 で報告されました。
- クエリキャッシュの hash index エントリがいっぱいにならないようにしました。(Tatsuo Ishii)
hash index エントリがいっぱいになると、pgpool-II は hash index の残りが少なくとも 1 つはある前提だったため、 古いキャッシュエントリを再利用できませんでした。 これを改善するために、hash index エントリがいっぱいになったら、再利用できるキャッシュブロックを 探すようにしました。
この不具合は bug#70 で報告されました。
- installer: checkEnv() が何もせず必ず 0(成功)を返していました。(Nozomi Anzai)
- clock hand の不適切なサイズの共有メモリ確保を修正しました。(Tatsuo Ishii)
clock hand のメモリは、sizeof(pool_fsmm_clock_hand) 分確保されており、 この変数が「
static int *pool_fsmm_clock_hand」と定義されていることから、8 バイトでした。しかしこれは誤りで、実際に必要なのは「
sizeof(*pool_fsmm_clock_hand)」での 4 バイトでした。これは Coverity "1111476 Wrong sizeof argument" で発見されました。
- "show pool_status" で
memqcache_auto_cache_invalidation が常に
0 と表示されていました。 (Tatsuo Ishii)
この不具合は bug#80 で報告されました。
- read_password_packet() のエラーメッセージを修正しました。(Tatsuo Ishii)
- watchdog: 一部関数で、引数を指定するのに大きな値そのものを渡さず、そのポインタを渡すようにしました。 (Yugo Nagata)
- SSL 要求でのメモリリークを修正しました。(Tatsuo Ishii)
SSL での要求があったとき、pgpool 子プロセスは start up packet の読み込みをリトライしていました。 しかし子プロセスは、以前の start up packet のメモリを解放していませんでした。
これは Coverity "1111443 Resource" で発見されました。
- do_query() がタイムスタンプの書き換えに失敗したとき、メモリリークしていました。(Tatsuo Ishii)
この修正のために、free_select_result() で NULL 引数を受け取れるようにしました。
これは Coverity "1111454, 1111455 Resource leak" で発見されました。
- レプリケーションモードでのロードバランスにおける不具合を修正しました。(Tatsuo Ishii)
load_balance_mode = off のとき、書き込みを関数を使った SELECT はすべての DB ノードに送られるべきでした。
これは [pgpool-general: 2221] で報告されました。 また、この不具合は 3.3.1 で混入しました。
- watchdog: ping 結果を格納する文字列で、終端に NULL 文字を追加しました。(Yugo Nagata)
- "
DEALLOCATE portal|statement" 実行時の対象ノードの選定ロジックを修正しました。(Tatsuo Ishii)"
DEALLOCATE portal|statement" 実行時、最後の prepared statement や portal が見つからない場合に、 対象ノード選定マップがセットされていませんでした。 おそらく、そうした場合はエラーなので、実際には問題ありません。これは Coverity "1111491 Structurally dead code" で発見されました。
- MAX_NUM_BACKENDS の範囲チェックにおける不具合を修正しました。 (Tatsuo Ishii)
MAX_NUM_BACKENDS は DB ノードの最大数が限界値でした(現時点では 128)。 実際には 128 の DB ノードで試す人がいなかったために、発見されなかった不具合のようです。
これは Coverity "1111429, 1111430 and 1111431 Out-of-bounds write" で発見されました。
- フロントエンド接続情報を、すでに無効なバックエンドについて set/unset しないようにしました。(Tatsuo Ishii)
この不具合は bug#82 で報告されました。
- pgpool_catalog への public access を許可していませんでした。
これは、pgpool_catalog がレプリケーションモードで作成されている場合に、 ユーザテーブルにデータを INSERT すると発生します。
この不具合は [pgpool-general-jp: 1229] で報告されました。
- doc: trusted_servers に複数のサーバを指定すべきであることを記述しました。 (Yugo Nagata)
- pool_do_auth() のエラーケースで変数を初期化していませんでした。 (Tatsuo Ishii)
有効なバックエンドがいないとき、pgpool は認証フェーズのフロントエンドにごみの pid を返していました。 実際に、有効なバックエンドがいないために、フロントエンドは認証後に接続することができません。 もちろんこれは問題あるものではありません。
これは Coverity "1127331 Uninitialized scalar variable" で発見されました。
- ノード ID を使ったエラーメッセージの発行時に、ノード ID の範囲チェックをするようにしました。
(Tatsuo Ishii)
これは Coverity "1111433 "Out-of-bounds read" で発見されました。
- parse_copy_data() でのバッファオーバーランとリソースリークを修正しました。 (Tatsuo Ishii)
これは Coverity "1111427 Out-of-bounds write"、"1111453 Resource leak" で発見されました。
- CopyDataRaws() で segfault する可能性があったのを修正しました。(Tatsuo Ishii)
pool_get_id() がエラーを返した場合に VALID_BACKEND が配列外にアクセスしようとしていました。
これは Coverity "1111433 Out-of-bounds read" で発見されました。
- クエリキャッシュ有効 + プロトコルバージョン = 2 の組み合わせでの処理を修正しました。(Tatsuo Ishii)
プロトコルバージョンが 2 のとき、セッション状態が "idle" である前提でしたが、 実際にはそうではありませんでした。 プロトコルバージョンが 2 の場合はクエリキャッシュを使用しないことをおすすめします。
これは Coverity "1111488 Uninitialized scalar variable" で発見されました。
- pool_pools() での strftime() の用法を修正しました。(Tatsuo Ishii)
バッファが第 2 引数で期待する値にたいして十分な大きさではありませんでした。 実際にはそのような長い値がわたることはなく、問題ないものです。
これは Coverity "1111426 Out-of-bounds access" で発見されました。
- RPM: spec ファイルで、pgpool-II と PostgreSQL のバージョンを指定できるようにしました。(Nozomi Anzai)
- make_persistent_db_connection のリソースリークを修正しました。(Tatsuo Ishii)
この修正ののために、新しく free_persisten_db_connection_memory 関数を追加しました。
これは Coverity #1111468 で発見されました。
- watchdog: RTT が非常に短いときに trusted servers への コネクションチェックに失敗する不具合をを、修正しました。(Yugo Nagata)
- Coverity で見つかったさまざまな不具合を修正しました。(Tatsuo Ishii)
3.3.1 (tokakiboshi) 2013/09/06
概要
このバージョンは 3.3.0 に対するバグ修正リリースです。
バグ修正
-
tar ball 作成時にレグレッションテストを含めるよう修正しました。(Tatsuo Ishii)
3.3.0 リリースの tar ball にはレグレッションテストが含まれていませんでした。
- レグレッションテストの watchdog テストスクリプトを修正しました。(Tatsuo Ishii)
-
メモリオーバーランを修正しました。(Tatsuo Ishii)
このバグは [pgpool-general: 1956] で Sean Hogan さんにより指摘されました。
[pgpool-general: 1956] memory overrun bug?
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001984.html - コンパイル時のエラーを修正しました。(Yugo Nagata)
-
オンメモリクエリキャッシュ使用時に子プロセスが sig abort で異常終了するバグを修正しました。
(Tatsuo Ishii)
parse メッセージの後に複数の bind/execute メッセージが来た場合に発生していた、メモリの二重開放がこのバグの原因です。 parse メッセージが来ると、クエリコンテキストと共に一時的なキャッシュが作成され、 クエリの実行時にこの一時キャッシュを指すポインタが配列に追加されます。そして、続く複数の bind メッセージがこの同じポインタを使用することが、キャッシュ削除の際に二重開放を引き起こす原因となっていました。
このバグはバグトラック #68 にて harukat さんにより報告されました。
#68: child process termination with sigabort when memory_cache_enabled = on
http://www.pgpool.net/mantisbt/view.php?id=68 - いくつかのテストケースをレグレッションテストに追加しました。(Tatsuo Ishii)
- ドキュメントの pgpool-recovery のインストールの節の typo を修正しました。(Tatsuo Ishii)
- ログメッセージの typo を修正しました。 (Yugo Nagata)
- 日本語ドキュメントの typo を修正しました。 (Yugo Nagata)
-
レプリケーションモードにてロードバランスモードが off の場合には、SELECT
クエリをマスターノードにのみ送信するよう修正しました。(Tatsuo Ishii)
レプリケーションモードでロードバランスモードが off の場合には、明示的なトランザクションの中で SELECT クエリは、全てのノードにではなく、マスターノードにのみ送られなくてはなりません。
このバグは [pgpool-general: 2038] にて Rypl Lukas さんにより報告されました。
[pgpool-general: 2038] SELECT sent to both nodes in replication mode
http://www.sraoss.jp/pipermail/pgpool-general/2013-August/002066.html - pgpool_setup が単独で動作しなくなっていたのを修正しました。(Tatsuo Ishii)
3.3.0 (tokakiboshi) 2013/07/30
概要
このバージョンは 3.3 系列の最初の版で、3.2 系からの「メジャーバージョンアップ」にあたります。
互換性のない変更
以下は全て watchdog に関する変更です。詳細は以下の新機能の項目を 参照してください。
- デフォルトの監視方法がクエリモードからハートビートモードに変更されました。
- failover/failback コマンドが1つの pgpool-II でのみ実行されるようになりました。
- デフォルトで、アクティブ pgpool-II への昇格時には共有メモリ内のクエリキャッシュを 全て削除するようになりました。
- クエリモードで他の pgpool-II を監視する際に用いられるデータベース名、ユーザ名、パスワードは 専用のパラメータで指定されるようになりました。 以前は template1, recovery_user, recovery_password が使われていました。
新機能
watchdog
- UDP のパケットのハートビート信号を用いた新しい監視方法が追加されました。(Yugo Nagata)
「ハートビート」モードと「クエリ」モードのから監視方法を選ぶことができます。
- ハートビートモード
-
ハートビートモードは今回新しく追加された方法です。
このモードでは、watchdog はハートビート信号を用いて 他の pgpool-II プロセスの死活監視を行います。 watchdog は、他の pgpool-II の watchdog より定期的に送られるハートビート信号を受け取り、 これが一定期間以上途切れた場合にはその pgpool-II プロセスに障害が発生したと判断します。
冗長性を高めるため、複数のネットワーク用いたハートビート交換が可能です。
デフォルトではこのモードで動作し、これが推奨設定です。
- クエリモード
-
クエリモードでは従来と同じ動作になります。 このモードではwatchdog は pgpool-II のプロセスではなく「サービス」の応答を監視します。 このモードでは、監視対象の pgpool-II にクエリを発行しその応答をチェックします。
この方法では他の pgpool-II から接続を受ける必要があるため、 num_init_children が十分大きくない場合には 監視が失敗する場合があることに注意してください。
これは非推奨の監視方法であり、下位互換のために残されています。
以下のパラメータが追加されました。
- filover/failback コマンドを排他的に実行するインターロック機能が追加されました。(Yugo Nagata)
watchdog で複数の pgpool-II を連携した場合、failover/failback コマンド (failover_command, failback_command, follow_master_command)は1つの pgpool-II でのみ実行されます。
以前は、これらのコマンドは全ての pgpool-II で実行されていました。
- watchdog パケット通信に認証機構が追加されました。(Yugo Nagata)
間違った認証キーを持つ pgpool-II から送られた watchdog パケットは拒絶されます。(ハートビート信号を含む) 全ての pgpool-II は同じキーを pgpool.conf の wdauthkey パラメータに持っている必要があります。 間違った認証キーを持っていると、スタートアップパケットも他の pgpool-II から拒絶されるため、 起動することもできません。
- clear_memqcache_on_escalation パラメータを
追加しました。(Yugo Nagata)
これが on の場合は、pgpool-II がアクティブに昇格した時に、 共有メモリ上のメモリキャッシュが全てクリアされます。
これは、新しいアクティブの pgpool-II が以前のアクティブと矛盾する 古いキャッシュを使わないようにするためです。
- wd_escalation_command パラメータを追加しました. (Yugo Nagata)
このパラメータに指定されたコマンドは、pgpool-II がアクティブに昇格した時に実行されます。 実行のタイミングは、仮想 IP が立ち上がった直後です。
- wd_lifeccheck_dbname, wd_lifecheck_user,
wd_lifecheck_password パラメータを追加しました。(Yugo Nagata)
これらのパラメータは、クエリモードで監視の際に使用するデータベース名、ユーザ名、パスワードを提要します。 以前はそれぞれ templat1, recovery_user, recovery_password が使われていました。
- delegate_ip オプションが空の場合には、
仮想 IP の立ち上げ/切り替えを行わないようになりました。(Yugo Nagata)
これにより、各 pgpool-II に固定 IP を用いてアクセスするマルチマスタ的運用で、 仮想 IP を用意する必要がなくなりました。
- pcp_watchdog_info コマンドを追加しました。(Yugo Nagata)
これは watchdog ステータスを取得する pcp コマンドです。
その他
- PostgreSQL 9.2 の raw パーサを取り入れました。 (Nozomi Anzai, Tatsuo Ishii)
- pgpool_setup を追加しました。(Tatsuo Ishii)
これはカレントディレクトリ下 pgpool-II と PostgreSQL のテスト環境を構築するツールです。
ex.) $ ./pgpool_setup -m s usage: pgpool_setup [-m r|s][-n num_clusters][--no-stop] -m s: ストリームレプリケーションモードで構築(デフォルト) -m r: ネイティブレプリケーションモードで構築 -n num_clusters: num_clusters 台で PostgreSQL データベースクラスタノードを作成 -p base_port: ベースとなるポート番号を指定。最初の PostgreSQL ノードのポートは base_port, 次の PostgreSQL ノードのポートは base_port + 1, n 番目 の PostgreSQL ノードのポートは base_port + n-1, pgpool のポートは base_port + n, pcp のポートは base_port + n + 1 となる。 --no-stop: セットアップ終了後に pgpool-II, PostgreSQL を終了しない - pgpool-recovery, pgpool-regclass を CREATE EXTENSION を使って
インストールできるようになりました。(Tatsuo Ishii)
古いインストール方法も継続して利用可能です。
エクステンションの名前が "pgpool-recovery", "pgpool-regclass" ではなく "pgpool_recovery", "pgpool_regclass" であることに注意してください。 前者では二重引用符が必要であり CREATE EXTENSION コマンドでは不便なためです。
- pgpool_pgctl() 関数 を追加しました。(Nozomi Anzai)
これを用いると、SQL から pg_ctl stop/restart/reload の実行が可能です。(ただし、start は除きます。)
$ psql sales -c "select pgpool_pgctl('reload', 'fast')"; pgpool_pgctl -------------- t (1 row)この関数は実行結果を無視して常に 't' を返すため、ユーザは pg_ctl が成功したか失敗したか知ることができません。 この関数を使用するには、セキュリティ上の理由から PostgreSQL で「pgpool.pg_ctl」というカスタム変数を設定し、 データディレクトリへの権限を持ち pg_ctl を実行するユーザを限定する必要があります。
- pgpool-II と pgpoolAdmin の RPM をインストールするシェルスクリプトを追加しました。
(Nozomi Anzai, Yugo Nagata)
getsources.sh を実行することで作成された work/installer に RPM ファイルをコピーし、 このディレクトリを tar ボールで固めたものがインストーラパッケージとなります。 このインストーラは、RPM をインストールするだけではなく、postgresql.conf, pgpool.conf, pg_hba.conf recovery.conf, ファイルオーバやオンラインリカバリ用のスクリプトの設定も行ないます。
2ノード構成を前提としており、インストールスクリプトは両方のノードで実行する必要があります。
- 新しいパラメータ search_primary_node_timeout を追加しました。
(Muhammad Usama, Tatsuo Ishii)
このパラメータはファイルオーバ時にプライマリノードを探す最大の秒数を指定します。 パッチは Muhammad Usama さんが作成し、日本語マニュアルの作成と、英語マニュアルの若干の修正を Tatsuo Ishii が行いました。
- オンメモリクエリキャッシュと watchdog の 中国語のチュートリアルを追加しました。(Bambo Huang)
- レグレッションテストを作成しました。(Tatsuo Ishii)
バグ修正
- オンラインリカバリ時のフェイルバックの完了待機でタイムアウト処理をするようにしました。(Tatsuo Ishii)
これによりリカバリが永遠に終わらず pgpool-II が終了できなくなる状況を回避します。 この現象は特に follow_master_command の実行中に起こり得ました。
- ストリームレプリケーションモードでの follow_master_command 実行時に、 %H に新しいプライマリノードが正しく割り当てられないバグを修正しました。(Tatsuo Ishii)
- 他の pgpool-II からダウン通知を受け取った pgpool-II が既にアクティブである場合には、 昇格処理を実行しないよう修正しました。(Yugo Nagata)
- watchdog ソケット作成時に、connect() の前に select() を実行していたのを修正しました。(Yugo Nagata)
未接続のソケットで select() を実行したときの処理は未定義で、プラットフォームで異なります。 Linux では 2 を返し、結果としては無害です。 しかし、Solaris では 0 を返し、これはタイムアウトと区別がつかないため、 watchdog が正しく動いていませんでした。
- pgpool_regclass がインストールされていない場合に生じるエラーを修正しました。(Tatsuo Ishii)
pgpool_rgcalss が存在しない場合に、pool_has_pgpool_regcalss() で使われているクエリが失敗していました。 詳しくは、 [pgpool-general:1722] を参照してください。
- PostgreSQL がエラーを返したときに do_query() がハングしないよう修正しました。(Tatsuo Ishii)
典型的な症状が「pg_stat_activety によると SELECT が実行されたままのように見える」というものです。 これを解決するため、pgpool-II は当該プロセスを終了させ、既存のコネクションを捨てるように修正しました。 あまり行儀のよい方法ではありませんが、これが最善の方法と信じています。
- watchdog を有効にしたときに、フェイルオーバの最中に起こりうるデッドロックを修正しました。(Yugo Nagata)
このバグは、バグトラッカ #54 にて arshu arora さんによって報告されました。
#54: pgpool-II semaphore lock problem
http://www.pgpool.net/mantisbt/view.php?id=54 - COMMIT 時エラーに不要なバックエンド切り離しを行わないようにしました。(Tatsuo Ishii)
マスタースレーブモードで、COMMIT 時にマスターノードでエラーが発生していたとしても、 他のスレーブノードが正常な場合にはバックエンドを切り離す必要はありません。 これは、遅延トリガーのために "kind mismatch error" が発生しうるからです。
- 拡張プロトコルの際に do_query で発生しうるハングアップを修正しました。(Tatsuo Ishii)
これは insert_lock が有効で、pgpool_catalog.insert_lock が存在することに起こり得ます。 詳しくは [pgpool-general: 1684] を参照してください。
- トランザクション内の DML で、クエリキャッシュの無効化が失敗する場合があるのを修正しました。(Tatsuo Ishii)
CREATE TABLE t1(i INTEGER); CREATE TABLE t2(i INTEGER); SELECT * FROM t1; BEGIN; DELETE FROM t2 WHERE i = 0; INSERT INTO t1(i) VALUES(1); COMMIT; SELECT * FROM t1;
上の SQL で、COMMIT 発行時に pgpool は t2 のキャッシュを削除しようとしますが、実際には t2 の OID テーブルエントリがないのでこれは失敗します。そのときに、t1 の OID テーブルの確認までも失敗とみなされ、 直前の t1 の SELECT 結果のキャッシュが不正に残っていました。
この問題はバグトラッカ #58 で wms さんにより報告されました。
#58: query cache invalidation does not fire for multiple DML in transaction
http://www.pgpool.net/mantisbt/view.php?id=58 - pgpool_regclass を pg_catalog スキーマに登録するよう修正しました。(Tatsuo Ishii)
これは postgres_fdw のような、スキーマ検索パスが pg_catalog に限定されているクライアントに 対応するために必要です。
- "pgpool -m f stop" で起こるハングアップを修正しました。(Tatsuo Ishii)
これは管理を外れた子プロセスが終了されずに残ってしまうのが原因で、複数のバックエンドがダウンしたときや、 バックエンドの起動前に pgpool-II が起動した場合に発生することがありました。
- pg_md5 コマンドで起こりうるクラッシュを修正しました。(Muhammad Usama)
- オンメモリクエリキャッシュ有効時に発生するセグメンテーション違反が修正されました。(Tatsuo Ishii))
これは、拡張クエリモードで実行されたクエリが長い結果を返すときに発生します。 このバグはバグトラック #63 にて、harukat さんにより報告、解析され、テストケースが提供されました。
#63 Child process was terminated by segmentation fault with memcached
http://www.pgpool.net/mantisbt/view.php?id=63 - スタートアップパケットに PostgreSQL ユーザ情報が含まれていなかった場合に発生する子プロセスの
セグメンテーション違反を修正しました。(Yugo Nagata)
このバグは以下を実行することにより再現できます。
$ psql -p 9999 -U ''
enable_pool_hba が有効の場合は子プロセスがセグメンテーション違反で異常終了し、 無効の場合には以下のメッセージがログに出力されていました。
ERROR: pool_discard_cp: cannot get connection pool for user (null) database (null)
また、両方の場合で psql はフロントエンドに何のメッセージ出力せずに終了していました。 修正後は、スタートアップパケットに PostgreSQL ユーザが指定されていない場合には 以下のメッセージがログとフロントエンドの両方に出力されます。 これは PostgreSQLと同じ振る舞いです。
FATAL: no PostgreSQL user name specified in startup packet
- オンメモリクエリキャッシュを有効にした時の拡張クエリの処理におけるメモリ割り当てロジックを修正しました。(Tatsuo Ishii)
バインドパラメータ付きの拡張クエリで、1024 バイト以上の長いクエリ文字列が渡されたときに、 十分なメモリ割り当てができていませんでした。
- pcp_recovery_node コマンドで、
バックエンドノード番号をチェックするように修正しました。(Yugo Nagata)
不正な値が使用された場合、リカバリで実行されるスクリプトの引数に空の値が渡されており、 誤動作の原因となっていました。 特にベースバックアップを行うスクリプトで、rsync が関係のないファイルを削除してしまうことがありました。
- バックエンドエラー検出時に発生することがあるメインプロセスの
セグメンテーション違反を修正しました。(Tatsuo Ishii)
この問題はバグトラック #62 で tuomas さんにより報告されました。
#62 Slave network outage causes a segmentation fault on main process
http://www.pgpool.net/mantisbt/view.php?id=62 - child_life_time 使用時に発生しうる
ヘルスチェックのバグを修正しました。(Tatsuo Ishii)
バックエンドが正しく動作しているにも関わらずフェイルオーバが発生することがありました。 この問題は [pgpool-general: 1892] で larisa sabban さんにより報告されました。
[pgpool-general: 1892] Pgpool is unable to connect backend PostgreSQL
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001920.html - レプリケーションモードにおけるプリペアド文のパース処理を修正しました。
(Tatsuo Ishii)
レプリケーションモードで SELECT 以外のクエリをパースする際には、ノード間の 一貫性保持のため自動的にトランザクションが開始されますが、トランザクション を閉じる処理が行われていませんでした。そのため、実際に誤っているクエリだけ ではなく、その次にパース処理されたクエリもアボートされていました。 このバグは [pgpool-general: 1877] で Sean Hogan さんにより報告されました。
[pgpool-general: 1877] current transaction is aborted, commands ignored
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001905.html
改良
- man ページに -D オプションの記述を追加しました。(Tatsuo Ishii)
- watchdog のプロセスが異常終了した場合に、これが自動で再起動されるよう修正しました。(Yugo Nagata)
- watchdog 有効時に ping コマンドを実行する関数にエラーチェックを追加しました。(Tatsuo Ishii)
- sprintf strncpy などの安全でない関数を、より安全な snprintf, strlcpy に置き換えました。(Yugo Nagata)
- ログ出力、コメント、関数名で使われていた "sticky bit" という用語を
"setuid bit" に置き換えました。(Yugo Nagata)
この用語は本来とは違う意味で使われており、混乱の元となっていました。
- pool_hba.conf.sample の SSL に関する記述を修正しました。(Tatsuo Ishii)
- レプリケーションモードで、明示的なトランザクション内のロードバランスができるようになりました。(Tatsuo Ishii)
ロードバランスが行われる条件は以下のとおりです。
- replicate_select が off
- 書き込みを行う関数が使われていない
- トランザクション分離モードが SERIALIZABLE ではない
- DML/DDL がトランザクションの中で実行されていない
- 中国語マニュアルを最新の情報に更新しました。(Bambo Huang)
- ドキュメントの ssl_ca_cert と ssl_ca_cert_dir の記述を SSL セクションに移動しました。(Yugo Nagata)
- 日本語ドキュメントに ssl_ca_cert と ssl_ca_cert_dir の記述を加えました。(Yugo Nagata)
3.2.6 (namameboshi) 2013/09/06
概要
このバージョンは 3.2.5 に対するバグ修正リリースです。
バグ修正
-
バックエンドエラー検出時に発生することがあるメインプロセスのセグメンテーション違反を修正しました。
(Tatsuo Ishii)
この問題はバグトラック #62 で tuomas さんにより報告されました。
#62 Slave network outage causes a segmentation fault on main process
http://www.pgpool.net/mantisbt/view.php?id=62 -
child_life_time 使用時に発生しうるヘルスチェックのバグを修正しました。(Tatsuo Ishii)
バックエンドが正しく動作しているにも関わらずフェイルオーバが発生することがありました。この問題は [pgpool-general: 1892] で larisa sabbanさんにより報告されました。
[pgpool-general: 1892] Pgpool is unable to connect backend PostgreSQL
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001920.html -
マニュアルの「pgpool-IIの配置について」の項目を改訂しました。(Tatsuo Ishii)
watchdog の使用に関する記述を追加しました。
- doc/basebackup.sh スクリプトの ssh コマンドの間違いを修正しました。(Tatsuo Ishii)
-
レプリケーションモードにおけるプリペアド文のパース処理を修正しました。(Tatsuo Ishii)
レプリケーションモードで SELECT 以外のクエリをパースする際には、 ノード間の一貫性保持のため自動的にトランザクションが開始されますが、 トランザクションを閉じる処理が行われていませんでした。 そのため、実際に誤っているクエリだけではなく、その次にパース処理されたクエリもアボートされていました。
このバグは [pgpool-general: 1877] で Sean Hogan さんにより報告されました。
[pgpool-general: 1877] current transaction is aborted, commands ignored
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001905.html -
オンメモリクエリキャッシュ使用時に子プロセスが sig abort で異常終了するバグを修正しました。
(Tatsuo Ishii)
parse メッセージの後に複数の bind/execute メッセージが来た場合に発生していた、メモリの二重開放がこのバグの原因です。 parse メッセージが来ると、クエリコンテキストと共に一時的なキャッシュが作成され、 クエリの実行時にこの一時キャッシュを指すポインタが配列に追加されます。そして、続く複数の bind メッセージがこの同じポインタを使用することが、キャッシュ削除の際に二重開放を引き起こす原因となっていました。
このバグはバグトラック #68 にて harukat さんにより報告されました。
#68: child process termination with sigabort when memory_cache_enabled = on
http://www.pgpool.net/mantisbt/view.php?id=68 - 日本語ドキュメントの typo を修正しました。 (Yugo Nagata)
3.2.5 (namameboshi) 2013/07/10
概要
このバージョンは 3.2.4 に対するバグ修正リリースです。
バグ修正
- man ページに -D オプションの記述を追加しました。(Tatsuo Ishii)
- オンラインリカバリ時のフェイルバックの完了待機でタイムアウト処理をするようにしました。(Tatsuo Ishii)
これによりリカバリが永遠に終わらず pgpool-II が終了できなくなる状況を回避します。 この現象は特に Wfollow_master_command の実行中に起こり得ました。
- ストリームレプリケーションモードでの follow_master_command 実行時に、 %H に新しいプライマリノードが正しく割り当てられないバグを修正しました。(Tatsuo Ishii)
- watchdog ソケット作成時に、connect() の前に select() を実行していたのを修正しました。(Yugo Nagata)
未接続のソケットで select() を実行したときの処理は未定義で、プラットフォームで異なります。 Linux では 2 を返し、結果としては無害です。 しかし、Solarisでは 0 を返し、これはタイムアウトと区別がつかないため、watchdog が正しく動いていませんでした。
- pgpool_regclass がインストールされていない場合に生じるエラーを修正しました。(Tatsuo Ishii)
pgpool_rgcalss が存在しない場合に、pool_has_pgpool_regcalss() で使われているクエリが失敗していました。 詳しくは、[pgpool-general:1722] を参照してください。
[pgpool-general: 1722] [PgPool-II 3.2.4] pgpool_regclass now mandatory?
http://www.sraoss.jp/pipermail/pgpool-general/2013-May/001749.html - PostgreSQL がエラーを返したときに do_query() がハングしないよう修正しました。(Tatsuo Ishii)
典型的な症状が「pg_stat_activety によると SELECT が実行されたままのように見える」というものです。 これを解決するため、pgpool-II は当該プロセスを終了させ、既存のコネクションを捨てるように修正しました。
- watchdog を有効にしたときに、フェイルオーバの最中に起こりうるデッドロックを修正しました。(Yugo Nagata)
このバグは、バグトラッカ #54 にて arshu arora さんによって報告されました。
#54 pgpool-II semaphore lock problem
http://www.pgpool.net/mantisbt/view.php?id=54 - 拡張プロトコルの際に do_query で発生しうるハングアップを修正しました。(Tatsuo Ishii)
これは insert_lock が有効で、pgpool_catalog.insert_lock が存在することに起こり得ます。 詳しくは [pgpool-general: 1684] を参照してください。
[pgpool-general: 1684] insert_lock hangs
http://www.sraoss.jp/pipermail/pgpool-general/2013-May/001711.html - COMMIT 時エラーに不要なバックエンド切り離しを行わないようにしました。(Tatsuo Ishii)
マスタースレーブモードで、COMMIT 時にマスターノードでエラーが発生していたとしても、 他のスレーブノードが正常な場合にはバックエンドを切り離す必要はありません。 これは、遅延トリガーのために "kind mismatch error" が発生しうるからです。
- トランザクション内の DML で、クエリキャッシュの無効化が失敗する場合があるのを修正しました。(Tatsuo Ishii)
CREATE TABLE t1(i INTEGER); CREATE TABLE t2(i INTEGER); SELECT * FROM t1; BEGIN; DELETE FROM t2 WHERE i = 0; INSERT INTO t1(i) VALUES(1); COMMIT; SELECT * FROM t1;
上の SQL で、COMMIT 発行時に pgpool は t2 のキャッシュを削除しようとします が、実際には t2 のOID テーブルエントリがないのでこれは失敗します。そのとき に、t1 の OID テーブルの確認までも失敗とみなされ、直前の t1 の SELECT 結果 のキャッシュが不正に残っていました。
この問題はバグトラッカ #58 で wms さんにより報告されました。
#58 query cache invalidation does not fire for multiple DML in transaction
http://www.pgpool.net/mantisbt/view.php?id=58 - pgpool_regclass を pg_catalog スキーマに登録するよう修正しました。(Tatsuo Ishii)
これは postgres_fdw のような、スキーマ検索パスが pg_catalog に限定されているクライアントに 対応するために必要です。
- pg_md5 コマンドで起こりうるクラッシュを修正しました。(Muhammad Usama)
- オンメモリクエリキャッシュ有効時に発生するセグメンテーション違反が修正されました。(Tatsuo Ishii))
これは、拡張クエリモードで実行されたクエリが長い結果を返すときに発生します。 このバグはバグトラック #63 にて、harukat さんにより報告、解析され、テストケースが提供されました。
#63 Child process was terminated by segmentation fault with memcached
http://www.pgpool.net/mantisbt/view.php?id=63 - スタートアップパケットに PostgreSQL ユーザ情報が含まれていなかった場合に発生する
子プロセスのセグメンテーション違反を修正しました。(Yugo Nagata)
このバグは以下を実行することにより再現できます。
$ psql -p 9999 -U ''
enable_pool_hba が有効の場合は 子プロセスがセグメンテーション違反で異常終了し、 無効の場合には以下のメッセージがログに出力されていました。
ERROR: pool_discard_cp: cannot get connection pool for user (null) database (null)
また、両方の場合で psql はフロントエンドに何のメッセージ出力せずに終了していました。 修正後は、スタートアップパケットに PostgreSQL ユーザが指定されていない場合には 以下のメッセージがログとフロントエンドの両方に出力されます。 これは PostgreSQLと同じ振る舞いです。
FATAL: no PostgreSQL user name specified in startup packet
- オンメモリクエリキャッシュを有効にした時の拡張クエリの処理におけるメモリ割り当てロジックを修正しました。(Tatsuo Ishii)
バインドパラメータ付きの拡張クエリで、1024 バイト以上の長いクエリ文字列が渡されたときに、 十分なメモリ割り当てができていませんでした。
- マニュアルの ssl_sa_cert, ssl_ca_cert_dir オプションの説明を SSL セクションに移動しました。(Yugo Nagata)
- ssl_sa_cert, ssl_ca_cert_dir オプションの説明を 日本語マニュアルに追加しました。(Yugo Nagata)
- pcp_recovery_node コマンドで、
バックエンドノード番号をチェックするように修正しました。(Yugo Nagata)
不正な値が使用された場合、リカバリで実行されるスクリプトの引数に空の値が渡されており、 誤動作の原因となっていました。 特にベースバックアップを行うスクリプトで、rsync が関係のないファイルを削除してしまうことがありました。
3.2.4 (namameboshi) 2013/04/26
概要
このバージョンは 3.2.3 に対するバグ修正リリースです。
バグ修正
- connect_inet_domain_socket_by_port() 関数内で select(2) に渡されるタイムアウトパラメータを
より適切に修正しました。(Tatuo Ishii)
Solaris などいくつかのプラットフォームでは、タイムアウトのマイクロ秒に 1000000 以上の大きな値を指定することが許されていません。そのため、タイム アウト値を秒とマイクロ秒に分けて設定するようにしました。
- connect_inet_domain_socket_by_port() で alarm 割り込み時を受けた時に、
エラー処理を行うよう修正しました。(Tatsuo Ishii)
この関数が無効なファイルディスクリプタを返すためにヘルスチェックが混乱し、 エラー検出に長時間かかる原因となっていました。
[pgpool-general: 1458]
health check timeout in pgpool-II-3.2.3
http://www.pgpool.net/pipermail/pgpool-general/2013-March/001482.html - 拡張プロトコルの処理における timestamp の書き換えに関する
長い間見過ごされていてたバグを修正しました。(Tatsuo Ishii)
Parse() 関数は、parse メッセージの書き換えの際に palloc() を使ってメモリを確保していました。 書き換えられたメッセージは pool_create_sent_message() 関数などが管理するデータ領域に格納されますが、これが問題となっていました。 この関数ではデータが session context memory 中に存在することを想定しているのに対し、 palloc() では query context においてメモリの割り当てを行っており、この領域は query context 終了時に解放されます。しかし、他の関数もこのメモリ領域を解放しようとするため、 セグメンテーション違反や二重解放を含む様々な問題の原因となっていました。 この問題は、書き換えたメッセージを格納するメモリを session context を用いて確保するこで修正されました。 これは pgpool-II 3.0 以来ずっと存在していたバグです。
この問題は、Naoya Anzai さんによって解析され、パッチが提供されました。
[pgpoolgenera-jp: 1146]
拡張問い合わせプロトコルでセグメンテーションフォルト
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001145.html - md5 認証で長いユーザ名を処理する際のバグを修正しました。(Tatsuo Ishii)
ユーザ名が 32 バイトより長い場合、md5 認証が動作していませんでした。 この問題は [pgpool-general: 1526] で Thomas Martin さんにより報告されました。
[pgpool-general: 1526]
[pgPool-II 3.2.3] MD5 authentication and username longer than 32 characters.
http://www.pgpool.net/pipermail/pgpool-general/2013-March/001551.html - レプリケーション遅延の計算はスタンバイサーバがプライマリサーバより遅れている場合にのみ
行うよう修正しました。(Yugo Nagata)
タイミングによってスタンバイよりプライマリの方がレプリケーションが遅延しているように見える場合があり、 その場合には負値の遅延が計算されていました。 この値が符号無し変数に代入されると、実際には遅延が生じていないにも関わらず、 ログに遅延が負値で出力され、されに悪いことには、ロードバランス機能により SELECT クエリがプライマリに振り分けられ、その結果プライマリの負荷が高まることがありました。
この問題は Saitoh Hidenori さんによって報告、解析されました。
[pgpool-genera-jp: 1145]
レプリケーション遅延確認の不具合について
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001144.html - pgpool-recovery が PostgreSQL 9.3 に対応しました。 (Tatsuo Ishii)
パッチは Asif Rehman さんにより提供され、これに Tatsuo Ishii が若干の修正を加えました。
[pgpool-hackers: 180]
compile error in ppool-recovery
http://www.pgpool.net/pipermail/pgpool-hackers/2013-April/000179.html - pool_has_pgpool_regclass が pgpool_regclass() の実行権限をチェックするよう修正しました。 (Tatsuo Ishii)
pgpool_regclass が存在する場合でも、pgpool がこの関数を実行できない場合に、 バックエンドへの接続がハングしていました。この問題は、pgpool_regclass から実行権限を剥奪し、ネイティブレプリケーションモードで INSERT を実行 することで再現可能です。
この問題は bugtrack #53 で報告されました。
#53 pgpool_regclas hangs all connections
Date: 2013-04-04 13:35
Reporter: tmandke
http://www.pgpool.net/mantisbt/view.php?id=53 - detect_postmaster_down_error() のエラーメッセージを修正しました。(Tatsuo Ishii)
例えば、"LOG: detect_stop_postmaster_error: detect_error error" を "LOG: detect_postmaster_down_error: detect_error error" に修正するなどです。
- watchdog 使用時の root ユーザであるかのチェックを取り除きました。(Tatsuo Ishii)
詳しい議論は以下を参照してください。
[pgpool-general: 1627]
Re: watchdog root requirement.
http://www.pgpool.net/pipermail/pgpool-general/2013-April/001654.html - 別名を持つ UPDATE/DELETE の処理におけるオンメモリクエリキャッシュのバグを修正しました。(Tatsuo Ishii)
別名を持つ UPDATE/DELETE 文(例えば、UPDATE t1 AS foo ...)において、 "t1 AS foo" がテーブル名と認識されていたため、クエリキャッシュの無効化が うまく働いていませんでした。 これは、パースツリーのノードからクエリ文を生成する nodeToString() 関数から呼び出されている _outRangeVar() 関数に原因があります。 出力されたクエリ文から "AS foo" の部分を取り除くことで解決しました。
この問題はバグトラック #56 で報告されました。
#56 UPDATE with alias does not discard cache
Date: 2013-04-18 17:33
Reporter: harukat
http://www.pgpool.net/mantisbt/view.php?id=56
3.2.3 (namameboshi) 2013/02/18
概要
pgpool-II 3.2.2 に対するバグ修正リリースです。 おもに、3.2.2 のヘルスチェックに関する致命的な問題を修正するものです。
以下の条件がすべて満たされたとき、フェイルオーバ発生時に pgpool のメインプロセスが消滅し、 pgpool-II へのクライアントの接続がすべてハングします。 また、その状態から復帰するには、pgpool の子プロセスを手動で kill し、pgpool-II を 再起動するしかありませんでした。
- ヘルスチェックが有効である。
- PostgreSQL への接続を、UNIX ドメインソケットではなく TCP/IP で行なっている (※ pgpool.conf のバックエンドノード設定において "backend_hostnameN" が空欄でない)。
バグ修正
- 3.2.2 で入り込んだ connect_inet_domain_socket_by_port() の
バグを修正しました。 (Tatsuo Ishii)
接続において non blocking の connect() が EINPROGRESS や EALREADY という結果を返したときには、 select(2) を呼んで read / write ファイルディスクリプタの準備されるまで待つようにしました。
本来は select() が 0 以上を返したときにそうするべきところを、0 を返したときだけになっていました。 その結果、connect_inet_domain_socket_by_port() が実際には失敗しているのに 成功していたと誤って返していました。
またさらに、これによって health_check() がバックエンドが生きているものと誤認し、 バックエンドソケットに書き込みを行なおうとし、失敗していました。 これをトリガに notice_backend_error() が呼ばれ、SIGUSR1 シグナルが pgpool のメインプロセスの 親プロセスに送られます。 その結果、pgpool をシェルから起動していれば、シェルを kill する、ということになります。
pgpool をバックグラウンドで起動していれば #1 プロセスを kill します。 これは、pgpool を root として起動していなければ問題ありません。 もっとも root として起動していても、SIGUSR1 を受け取って /dev/initctl を再度 open するだけなので、 実際に問題はありません。
これらの困った問題は pgpool が誕生した時点から存在していましたが、 connect_inet_domain_socket_by_port() のバグによって表面化しました。 修正には、notice_backend_error() と child_exit() を変更し、 pgpool のメインプロセス自体から呼ばれたときには、自分自身を kill しないように、何も行なわないようにしました。
- 設定パラメータの一覧を表示する "SHOW pool_status" で pool_passwd が表示されていないのを修正しました。(Yugo Nagata)
- configure.in にある configure のヘルプの typo を修正しました。 (Yugo Nagata)
3.2.2 (namameboshi) 2013/02/08
概要
このバージョンは 3.2.1 に対するバグ修正リリースです。
バグ修正
- FreeBSD で発生するコンパイルエラーを修正しました。 (Tatsuo Ishii)
- デフォルトのスキーマ(通常は public)以外で作られたビューが
認識されていなかったバグを修正しました。(Tatsuo Ishii)
このバグのため、本来キャッシュされるべきでない、該当するビューのクエリ結果がキャッシュされていました。
この問題はバグトラック #30 で jgentsch さんによって報告され、パッチを提供頂きました。
#30 pgpool 3.2.1 - views in schema other than public are caching
Reporter: jgentsch
Date: 2012-10-19 23:13
http://www.pgpool.net/mantisbt/view.php?id=30 - md5 認証で競合が発生する不具合が修正されました。(Tatsuo Ishii)
pool_passwd のファイル識別子は pgpool の親プロセスで開かれたものが子プロセスに引き継がれてます。 複数の接続で同時に md5 認証を行う際には、pool_get_passwd が呼ばれ、ファイル識別子が走査されますが、 ファイル識別子が共有されるために md5 認証が失敗することがありました。 この問題は、個々の子プロセスで pool_passwd ファイルを開き直すことで解決されました。
この問題は [pgpool-general:1141] にて、Jason Slagle さんによって報告・解析されました。
[pgpool-general: 1141] Possible race condition in pool_get_passwd
From: Jason Slagle
Date: Sun, 28 Oct 2012 01:12:52 -0400
http://www.sraoss.jp/pipermail/pgpool-general/2012-October/001160.html - ロードバランスの条件について、より詳しい情報をマニュアルに追記しました。 (Tatso Ishii)
- オンメモリクエリキャッシュ使用時に発生するセグメンテーションフォルトを修正しました。
これはキャッシュアレイの処理のバグが原因です。 (Tatsuo Isii)
トランザクション中の一時キャッシュの結果を保持するためにキャッシュアレイ使用されます。 1つのトランザクションに 128 以上の SELECT がある場合には、キャッシュアレイの領域が realloc を用いて拡張されます。 しかし、その時に返却される新しいポインタではなく、古いポインタが使われ続けていました。
この問題はバグトラック #31 にて jgentsch さんによって報告されました。
#31 pgpool V3_2_STABLE - segfault in pool_memqcache.c:2529
Reporter:jgentsch
Date: 2012-10-23 06:25
http://www.pgpool.net/mantisbt/view.php?id=31 - pcp_attach_node, pcp_detach_node を
繰り返し実行したときに起こるハングアップを修正しました。 (Tatsuo Ishii)
pcp_attach_node, pcp_detach_node により ノードステータスが変更された時、failover() は子プロセスに SIGUSR1 シグナルを送り、 プロセスの終了とノードステータスの更新を行います。 その時に発せられた SIGCHLD シグナルは全て reaper() ハンドラで受信しますが、システムの 負荷とタイミングによりこれが失敗することがありました。pcp プロセスによる SIGCHLD シグナルの 受信に失敗した場合に、これがゾンビプロセスとなり、pcp プロセスが永遠に再起動されなくなって いました。
この問題はバグトラック #32(oleg_myrk さんによる)他で報告されました。
#32 PGPool hangs on pcp_attach/detach
Reporter: oleg_myrk
Date: 2012-10-24 00:01
http://www.pgpool.net/mantisbt/view.php?id=32 - pool_send_severity_message() で未初期化のメモリを使用しないよう修正しました。(Tatsuo Ishii)
このバグによりセグメンテーション違反が発生することがありました。 バグトラック #33 に投稿された valgrind 実行結果(dudee さんによる)にて報告されました。
#33 pgpool-II 3.2.1 segfault
Reporter: dudee
Date: 2012-10-30 19:16
http://www.pgpool.net/mantisbt/view.php?id=33 - 通常のテーブルと同名の一時テーブルがあるときに、クエリキャッシュの結果が不正になるバグを
修正しました。 (Tatsuo Ishii)
以下はバグを引き起こす処理の例です。
1) CREATE TABLE t1(i int); -- 通常のテーブルを作成 2) INSERT INTO t1 VALUES(1); 3) SELECT * FROM t1; -- クエリキャッシュが作成される 4) CREATE TEMP TABLE t1(i int); -- 一時テーブルの作成 5) SELECT * FROM t1; -- 誤ったクエリキャッシュが作成される!
#3 で t1 のキャッシュが生成されますが、#5 でこれが不正に使われており、 一時テーブル t1 が一時テーブルと見なされていないのが問題でした。
- ヘルプメッセージに -f オプションの説明を追加しました。 (Tatsuo Ishii)
- pcp または worker 子プロセスの終了イベントを受信したときに、reaper() で wait3()
ループを終了しないように修正しました。 (Tatsuo Ishii)
修正前は、reaper() は子プロセスの終了イベントを誤って無視してしまい、ゾンビプロセスを作り、 新しいプロセスを生成できないことがありました。
この問題は [pgpool-general-jp: 1123] にて、後藤さんより報告され、修正の示唆を頂きました。
[pgpool-general-jp: 1123] Re: オンラインリカバリ後にゾンビプロセスになる
From: GOTO, Daisuke
Date: Wed, 21 Nov 2012 19:56:17 +0900
http://www.sraoss.jp/pipermail/pgpool-general-jp/2012-November/001122.html - configure のヘルプメッセージの typo を修正しました。 (Yugo Nagata)
- wd_hostname を pool_process_reporting.c に追加しました。 (Yugo Nagata)
以前は SHOW pool_status, pcp_pool_status の結果に wd_hostname が出力されていませんでした。
- connect(2) が EISCONN(ソケットが接続済み)エラーを返したときには、
connect_inet_domain_socket_by_port() はエラーを出力しないよう修正しました。(Tatsuo Ishii)
これはノンブロッキングソケットでは起こり得る、正常のこととして扱われるべきです。 バグトラック #29 (by spork)と pgpool-general 1218(by Mikola Rose)で報告されました。
#29 pgpool 3.2.1 cannot connect to db hosts
Reporter: spork
Date: 2012-10-18 15:03
http://www.pgpool.net/mantisbt/view.php?id=29[pgpool-general: 1218] pgpool 3.2.1 - Health check failing to connect
From: Mikola Rose
Date: Tue, 4 Dec 2012 20:21:55 +0000
http://www.sraoss.jp/pipermail/pgpool-general/2012-December/001237.html - health_check() が template1 データベースに再接続を試みる前に、ヘルスチェックタイマーを
チェックするよう修正しました。 (Tastuo Ishii)
修正前は、ヘルスチェックタイマーが既に期限を向かえているために、0 番ノードへのヘルスチェックの 再接続が常に失敗していました。
- pool_search_relcache() が REAL_MASTER_NODE_ID ではなく MASTER, MASTER_NODE_ID
を使用するように修正しました。 (Tatsuo Ishii)
ストリーミングレプリケーションモードで 0 番ノードがフェイルバックした場合、pgpool は 子プロセスを再起動しません。そのとき、REAL_MASTER_NODE_ID は 0 番ノードの接続情報を探しにいきますが、 これはバックエンドへの新しい接続が確立するまで存在しません。 そのため、接続情報の参照によって、セグメンテーションフォルトが発生していました。 この状況でも、MASTER または MASTER_NODE_ID は以前にキャッシュされたマスターノード ID を見にいくため、 安全に使うことが出来ます。
- ストリーミングレプリケーションモードでレプリケーション遅延が大きくなったときに、
"portal not found" エラーが発生するバグを修正しました。 (Tatsuo Ishii)
これは delay_threshold が導入されて以来、ずっと存在していたバグです。
bind, describe, execute の実行時に遅延が域値を越えた場合、送り先の DB ノードは 変更されていました。しかし、parse がそれとは異なるノードに送られていた場合、送り先ノードには parse された ステートメントやポータルが存在しないために bind, describe, execute は 失敗していました。 修正後は、大きな遅延が発生した場合でも、これらは parse が実行されたノード以外には 送られないようになりました。
- pg_md5 で、ユーザからのパスワード入力の後には改行するように修正しました。 (Yugo Nagata)
- watchdog のポート番号が既に使用されていた場合にエラーメッセージを出力するよう修正しました。
(Yugo Nagata)
この問題は [pgpool-general: 1167] で Will Ferguson さんによって報告されました。
[pgpool-general: 1167] Re: Watchdog error - wd_init: delegate_IP already exists
From: Will Ferguson
Date: Tue, 6 Nov 2012 13:03:36 +0000
http://www.sraoss.jp/pipermail/pgpool-general/2012-November/001186.html - コネクションプールが存在しない場合には、child_exit() が send_frontend_exits()
を呼ばないよう修正しました。 (Tatsuo Ishii)
send_frontend_exits() は pool_connection_pool で指されてるオブジェクトを参照しているため、 修正前にはセグメンテーションフォルトが発生していました。バグトラック #44 の tuomas さんの報告によります。
#44 pgpool went haywire after slave shutdown triggering master failover
Reporter: tuomas
Date: 2012-12-11 00:33
http://www.pgpool.net/mantisbt/view.php?id=44 - オンメモリクエリキャッシュで、black_memqcache_table_list に テーブルが指定されている場合に white_memqcache_table_list に 指定されたテーブルのみがキャッシュされていたバグを修正しました。 (Yugo Nagata)
- pool_read() が不正なパケットを読み込んだ場合に、read_startup_packet() がアラームクロック
をリセットして StartupPacket を解放するよう修正しました。 (Nozomi Anzai)
修正前は、pgpool ポートの監視を行うプログラムの接続により、認証のタイムアウトが発生していました。 この問題は、バグトラック #35 で報告されました。
#35 Authentication is timeout
Reporter: tuomas
Date: 2012-11-20 11:54
http://www.pgpool.net/mantisbt/view.php?id=35 - pool_open() が誤ったバッファポインタを初期化していたバグを修正しました。 (Tatsuo Ishii)
このポインタは事前に memset() によって初期化されているため、実際にはこのバグによる害は ありませんでした。
- fail_over_on_backend_error が無効のため フェイルオーバが行われなかった場合には、ログメッセージを出力するようにしました。 (Tatsuo Ishii)
- LISTEN/NOTIFY の処理に関するバグを修正しました。 (Tatsuo Ishii)
1) ストリームレプリケーションモードにおいて以下の状況でハングアップが起きていました。
Session 1: LISTEN aaa; Session 2: NOTIFY aaa; Session 1: LISTEN aaa; --- ハング(LISTEN と NOTIFY が同じセッションで発行された場合には問題ありませんでした。)
pgpool では、パケットは全てのバックエンドから送られてくることを前提にしていました。 しかし、ストリーミングレプリケーションモードでは notifiction メッセージはプライマリノードからしか 送られて来ません。このハングは、スタンバイノードからのパケット読込を回避することで修正しました。
2) この修正後も、ストリーミングレプリケーションモードでプライマリノードが 0 番ノードの場合には、 #1 と同様のハングが発生していました。これは、MASTER_NODE_ID マクロが 常に REAL_MASTER_NODE_ID を返していたためです。 master/slave モードでは、これが PRIMARY_NODE_ID を返すように修正しました。
3) レプリケーションモードでは LISTEN/NOTIFY は全く動作していませんでした。このモード では NOTIFY は全てのバックエンドに送られます。しかし、その応答の順番はマスターが最初で、 次がスレーブとは限りません。最初にスレーブから応答した場合には、単にそれを破棄するのではなく、 マスターから読込を行うように pool_process_query() を修正しました。
4) レプリケーションモードで、LISTEN と NOTIFY が同じセッションから発行された場合、 db_command() が 'N', 'E', 'S', 'C' 以外のパケットを受信するために、そのセッションは切断されていました。 これは、'A'パケットをスタックに入れておき、都合の良いときに取り出すことで解決しました。 そのための関数、pool_push(), pool_pop(), pool_stacklen() が追加されています。
このバグはバグトラック #45 で rpashin さんにより報告されました。
#45 LISTEN/NOTIFY doesn't work if cluster contains more then 1 node in
streaming replication mode
Reporter: rpashin
Date: 2012-12-12 00:09
http://www.pgpool.net/mantisbt/view.php?id=45修正のサイズが大きいため、この修正は 3.1 以前にはバックパッチされません。 (これまでのところ、3.1 以前でこの障害の報告はありません。)
- connect(2) が EINPREGESS または EALREADY エラーを返したときには、
connect_inet_domain_socket_by_port() は エラーを出力せずに、select(2) を実行するよう
修正しました。 (Tatsuo Ishii)
ノンブロッキングソケットでは、"Connection timed out" エラーにもかかわらず、実際には 接続は確立されています。これを解決するためには、connect(2) が EINPROGRESS または EALREADY を返した場合には、再試行ループではなく select(2) を使って接続を待つ必要があります。
この問題は、バグトラック #46 で mcousin さんにより報告されました。
#46 Watchdog failing to connect sometimes
Reporter: mcousin
Date: 2012-12-15 01:01
http://www.pgpool.net/mantisbt/view.php?id=46 - watchdog 使用時は num_init_children を大きめに設定するよう、
マニュアルに注意書きを追記しました。 (Tatsuo Ishii)
詳しくは [pgpool-general: 1330] をご覧ください。
[pgpool-general: 1330] WatchDog and pgool sudden stop working
From: Tomas Halgas
Date: Fri, 18 Jan 2013 14:47:23 +0100
http://www.sraoss.jp/pipermail/pgpool-general/2013-January/001350.html - watchdog を有効にしたときに、 pgpool-II の起動時、フェイルオーバ時に発生する
セグメンテーションフォルトを修正しました。 (Yugo Nagata)
このバグの原因は pthread_detach と pthread_join を併用するという pthread の誤使用でした。 スレッドのステータス取得のため、pthread_join のみを用いることで修正しました。 なお、この問題は Fedora 17 などの比較的最近の OS で発生しましたが、 幸運にも他の OS では観察されていませんでした。
この問題は [pgpool-general: 1179] にて、Lonni J Friedman さんによって報告されました。
[pgpool-general: 1179] 3.2.1 segfaults at startup on Fedora17.
>
From: Lonni J Friedman
Date: Mon, 12 Nov 2012 15:58:29 -0800
http://www.sraoss.jp/pipermail/pgpool-general/2012-November/001198.html修正パッチはバグトラック #48 にて、chads さんによって提供頂きました。
pthread_detach is being used wrong; causes pgpool to segfault.
Reporter: chads
Date: 2013-01-16 05:44
http://www.pgpool.net/mantisbt/view.php?id=48 - [pgpool-general: 1046] で報告されたスプリットブレインが発生しないよう修正しました。(Yugo Nagata)
全てのバックエンドから切り離された pgpool-II にバックエンドを復帰させた時に、複数の アクティブ pgpool が存在してしまう状況(スプリットブレイン)が発生していました。 修正後は、一度全てのバックエンドから切り離された pgpool-II は、再起動されない限り、 ダウン状態に留まります。ダウン状態の pgpool-II はアクティブになれないため、 上述のスプリットブレインは回避されます。
[pgpool-general: 1046]
watchdog enabled delegate_IP on multiple nodes simultaneously
From: Lonni J Friedman
Date: Wed, 26 Sep 2012 09:05:09 -0700
http://www.sraoss.jp/pipermail/pgpool-general/2012-September/001064.html - アクティブ pgpool の終了時にハングすることがあったのを修正しました。(Yugo Nagata)
アクティブ pgpool は終了時に仮想 IP を停止してパケットを他の pgpool に送ります。 しかし、仮想 IP が完全に停止する前にパケットが送信されることがありました。その場合、 パケットの送信元には仮想 IP がセットされるため、仮想IPの停止後はアクティブ pgpool パケットの 応答を受け取れなくなり、ハングしていました。
修正後は、アクティブ pgpool は仮想 IP の停止を確認した後に、パケットを送信します。
- マニュアルの「watchdogの制限事項」の項目を加筆・修正しました。 (Yugo Nagata)
- pgpool.conf.sample* およびドキュメント中の、「パラメータ変更に再起動が必要かどうか」の情報を 追記・修正しました。 (Yugo Nagata)
- pool_passwd に関する記述を pgpool_conf.sample*、 ドキュメント、 および
pool_process_reporting.c に追加しました。 (Yugo Nagata)
修正前は、SHOW pool_status, pcp_pool_status の出力に pool_passwd が含まれていませんでした。
3.2.1 (namameboshi) 2012/10/12
概要
このバージョンは 3.2.0 に対するバグ修正リリースです。
バグ修正
- send_cached_messages() を修正しました。 (Tatsuo Ishii)
これまでは、行データが 8192 byte 以上のときはバッファ長を 8192 byte に修正して キャッシュしているだけでした。
これを、引数としてわたってきたバッファ用の raw データのコピーを削除して、 send_message へのポインタを無視するようにしました。
- クエリキャッシュ機能により、拡張問い合わせが失敗していたのを修正しました。 (Nozomi Anzai)
- read_startup_packet() を修正しました。(Tatsuo Ishii)
パケット長が 0 以下のときは直ちに return するべきでしたが、そうなっていなく、 メモリ確保時にエラーになっていました。
これは pgpool-general:886 を参照してください。また、キャンセルアラームを追加しました。
[pgpool-general: 886] read_startup_packet: out of memory
From: Lonni J Friedman
Date: Wed, 8 Aug 2012 10:18:15 -0700
http://www.sraoss.jp/pipermail/pgpool-general/2012-August/000896.html - pgpool をシャットダウンするときに、watchdog のプロセス終了方法を修正しました。 (Tatsuo Ishii)
watchdog プロセスは kill(0,SIG) を呼んで watchdog 関連のプロセスを終了していました。 これによってかえって、親プロセスや pgpool や httpd プロセスまでもを終了させることがありました。 これは、pgpoolAdmin によって invoke されている場合に、すべてが同じプロセスグループになるためです。
将来は、どんな場合でもsetsid()によって新しいプロセスグループを作るべきだと思います。
- "-- コメント" で始まったりコメントが複数あるクエリで、 クエリキャッシュが使えなかったのを修正しました。(Nozomi Anzai)
- マルチステートメントのクエリはキャッシュしないようにしました。(Nozomi Anzai)
これまでは "SELECT 1;UPDATE..." のようなクエリもキャッシュしていましたが、誤りでした。
- ドキュメントに watchdog の制限を追記しました。(Yugo Nagata)
- s_do_auth() に NOTICE メッセージを追加しました。(Tatsuo Ishii)
これがなかったために、ヘルスチェックが false アラームを受け取りフェイルオーバしていました。
これはバグトラックで報告されました。
#25 s_do_auth doesn't handle NoticeResponse (N) message
Date: 2012-08-28 03:57
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=25 - s_do_auth() から、不要かつ混乱をまねくデバッグメッセージを削除しました。(Tatsuo Ishii)
- メモリキャッシュ有効時に Execute() でバッファオーバーランするのを修正しました。(Tatsuo Ishii)
bind パラメータのひとつが 0 より小さいとき、符号拡張のために "%02X" で 2 バイト以上の文字を生成する可能性がありました。
また、そのあとにバッファオーバランを招く可能性を排除するため、sprintf() ではなく snprintf() を使うようにしました。
- 2009 年 12 月にリリースした pgpool-II 2.3 以来ずっと存在した
free_select_result() のメモリーリークを修正しました。(Tatsuo Ishii)
実際にはこのバグは、レプリケーションモードでしか発生しません (タイムスタンプ書き換え時に偶然発生することがありました)。
これはバグトラック #24 で報告されました。
#24 Severe memory leak in an OLTP environment
Date: 2012-08-28 03:43
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=24 - cache_reporting() の typo を修正しました。(Tatsuo Ishii)
- SSL モードでの無限ループを修正しました。 (Tatsuo Ishii)
フロントエンドの SSL レイヤで溜っているデータがあるとき、 pool_process_query() がバックエンドに溜っているデータをチェックします。 もしそれが無かったときは再度ループして、フロントエンド/バックエンドがバッファを受け取っていないか is_cache_empty() を以ってチェックします。 しかし、フロントエンドの SSL レイヤでデータが溜っているのを一度検知すると、 バックエンドに行ってまたチェックしようとします(無限ループ)。
これを解決するには、フロントエンドの SSL レイヤに溜っているデータがあり かつ クエリが実行中でなければ、ProcessFrontendResponse() を呼んで フロントエンドへの新しいリクエストをするようにしました。
- is_system_catalog() で、可能ならば pgpool_regclass を使うようにしました。(Tatsuo Ishii)
- pool_get_insert_table_name() のメモリリークを修正しました。(Tatsuo Ishii)
nodeToString() でセッションコンテクストのメモリコンテクストを使ったあと、 セッション終了までは、メモリを開放していませんでした。
詳しくはバグトラックをご覧ください。
#24 Severe memory leak in an OLTP environment
Date: 2012-08-28 03:43
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=24 - OID マップファイルをロックするのに flock(2) ではなく fcntl(2) を使うようにしました。(Tatsuo Ishii)
flock(2) は環境に依存し、Solaris で使えませんでした。 パッチは Ibrar Ahmed さんからいただきました。
- Raw モードで稼働しているとき、get_next_master_node() で見落としがあったのを修正しました。(Tatsuo Ishii)
マスタノードがダウンしたとき、必ずマスタノード ID 0 を返していました。
詳細は [pgpool-general: 1039] をご覧ください。
[pgpool-general: 1039] Raw failover not working as expected on pgpool-II v3.2.0 From: Quentin White
Date: Tue, 25 Sep 2012 07:45:34 +0000
http://www.sraoss.jp/pipermail/pgpool-general/2012-September/001057.html - do_query() のセグメンテーションフォルトを修正しました。(Tatsuo Ishii)
クエリキャッシュが有効で拡張問い合わせが使われているとき、do_query() はシステムカタログに接続し、 pool_read2() を使います。 しかし、parse メッセージパケットを Parse() で取得し、パケットの内容が pool_read2() のバッファにあります。 このため、do_query() はパケットの内容を分割できず、セグメンテーションフォルトを引き起こしていました。
これを解決するために、メモリを確保し、パケット内容をコピーし、Parse() を飛ばすようにしました。 ただし、パケットの中にはクエリコンテクストが参照しているクエリ文字列も含まれています。 そのため、このクエリ文字列をコピーしてポインタをクエリコンテクストに保持する必要があります。
これは、Parse() だけの話でなく、他のプロトコルモジュールにもある問題と考えています。 本修正はそれらにも適用しますが、そのためには、ProcessFrontendResponse() を変更します。
この問題はバグトラック #21 で報告されました。
#21 pgpool-II 3.2.0 cannot execute sql through jdbc
Date: 2012-08-17 16:31
Reporter: elisechiang
http://www.pgpool.net/mantisbt/view.php?id=21 - PCP 通信で UNIX ドメインソケットパスをセットするのを、
シグナルハンドラのセットアップ前に行なうように修正しました。(Yugo Nagata)
これまでは、このパス情報がなかったために、プロセス終了時のソケットの削除が失敗していました。
パッチは Gilles Darold さんが提供しました。
[pgpool-hackers: 131] Found bug with watchdog resulting in pgpool segmentation fault From: Gilles Darold
Date: Thu, 13 Sep 2012 18:54:42 +0200
http://www.sraoss.jp/pipermail/pgpool-hackers/2012-September/000130.html - watchdog の ifup/ifdown や arping コマンドが存在しないときに メッセージを出すようにしました。 (Yugo Nagata)
- ずっとあった do_query() で "portal "" does not exist" エラーが出るのを修正しました。(Tatsuo Ishii)
1) 拡張問い合わせを使っていて、 2) unnamed portal が使われていて、 3) 明示的なトランザクションを使っていないとき、 ユーザの unnamed portal が Sync メッセージで削除されていました。
これは、Sync メッセージがトランザクションを終了して unnamed portal を削除するためです。 このために "portal "" does not exist" というエラーが出ていました。
これを修正するために、Sync ではなく Flush メッセージを使うようにしました。 二者の主な違いとしては、Flush は Ready For Query メッセージを返さないことです。 したがって do_query() は、来るべきであろうメッセージをすべて待ってから return するようになります。
バックエンドからメッセージが来る順序はランダムに見えますが、do_query() は それを状態のビットを以って管理しています。
3.2.0 (namameboshi) 2012/08/03
概要
このバージョンは 3.2 系列の最初の版で、3.1 系からの「メジャーバージョンアップ」にあたります。
互換性のない変更
- メモリベースのメモリキャッシュ機能を追加したため、旧来のメモリキャッシュ機能は削除しました。
- これにともない、enable_query_cache パラメータを削除しました。
新機能
- メモリベースのクエリキャッシュを追加しました。
(Tatsuo Ishii, Nozomi Anzai, Yugo Nagata)
オリジナルは Masanori Yamazaki さんが作成し、開発グループで改良しました。
- 概要
- キャッシュストレージの選択
-
メモリキャッシュのストレージには、共有メモリと memcached のどちらかを選択することができます (併用はできません)。
- 共有メモリを使用するクエリキャッシュは高速で、memcached の立ち上げも必要なく、手軽に利用できます。 ただし、共有メモリサイズの上限によって保存できるキャッシュの量に制限があります。
- memcached をキャッシュストレージに使用する場合は、ネットワークアクセスのオーバヘッドがあるものの、 比較的自由にキャッシュメモリの大きさを設定できます。
- 制限事項
-
-
オンメモリクエリキャッシュでは、テーブルに変更があると、関連するキャッシュを自動的に削除して
古いデータが返却されないようにする機能があります。
このため、pgpool は常に UPDATE や INSERT や ALTER TABLE などのコマンドが発行されたかどうかを
モニタしています。
しかし、トリガ、外部キーや DROP TABLE CASCADE などの働きによって暗黙的にテーブルが更新されたことは pgpool-II からはわからないため、この機能が働きません。
この問題を回避するためには、 memqcache_expire を使って一定時間経過したキャッシュを削除するようにするか、 black_memqcache_table_list を使って、該当テーブルが キャッシュされないようにしてください。 -
複数の pgpool-II を動かす環境で共有メモリを使ったオンメモリクエリキャッシュを使用すると、
ある pgpool-II 経由でテーブルが更新された時に、他の pgpool-II のキャッシュが削除されず、
古いデータを読みだしてしまうことがあります。
このような環境では、キャッシュストレージに memcached を使ってください。
-
オンメモリクエリキャッシュでは、テーブルに変更があると、関連するキャッシュを自動的に削除して
古いデータが返却されないようにする機能があります。
このため、pgpool は常に UPDATE や INSERT や ALTER TABLE などのコマンドが発行されたかどうかを
モニタしています。
- 新しいパラメータ
-
- メモリキャッシュ全般に関するパラメータ memory_cache_enabled、 memqcache_method、 memqcache_expire、 memqcache_maxcache、 memqcache_oiddir を追加しました。(Tatsuo Ishii)
- 共有メモリを使ったメモリキャッシュに関するパラメータ memqcache_total_size、 memqcache_max_num_cache、 memqcache_cache_block_size を追加しました。 (Tatsuo Ishii)
- memcached を使ったメモリキャッシュに関するパラメータ memqcache_memcached_host、 memqcache_memcached_port を追加しました。 (Tatsuo Ishii)
- リレーションキャッシュに関するパラメータ relcache_expire、 relcache_size を追加しました。(Tatsuo Ishii)
- 一時テーブルかどうかをチェックするフラグ check_temp_table パラメータを 追加しました。(Tatsuo Ishii)
- テーブル、一時テーブル、ビューのキャッシュ可否を指定するパラメータ、 white_memqcache_table_list、 black_memqcache_table_list を追加しました。 (Nozomi Anzai)
- memqcache_auto_cache_invalidation
パラメータを追加しました。(Yugo Nagata)
true であれば、DDL/DML/DCL が発行されたら memqcache_expire を待たずに クエリキャッシュを削除します。
- SHOW pool_cache を追加しました。クエリキャッシュのヒット率や、 キャッシュストレージの状況を表示します。(Tatsuo Ishii)
- configure に --with-memcached オプションを追加しました。(Tatsuo Ishii)
- pgpool コマンド に "-C, --clear-oidmaps" オプションを追加しました。
(Nozomi Anzai)
memcached を使ったメモリキャッシュを行なっている pgpool が -C つきで起動・再起動したときは、 oid マップを削除せず再利用します。
メモリ上にキャッシュが置かれるので高速であるばかりでなく、データが更新されると自動的にキャッシュが無効になり、 pgpool-II の再起動の必要がありません。
オンメモリクエリキャッシュは、問い合わせの SELECT 文(拡張問い合わせの場合は更にバインドパラメータ)と 検索結果をペアで記録し、2 回目以降に同じ SELECT 文が発行された場合に、キャッシュから結果を返します。 通常の SELECT 文処理と違って、PostgreSQL にアクセスしないだけでなく、 pgpool 内部の SQL パース処理などを経由しないため、非常に高速です。
反面、キャッシュにヒットしない場合は通常の SELECT 文の処理に加えてキャッシュ処理のオーバヘッドが生じるので、 かえって遅くなります。また、あるテーブルが更新された場合、そのテーブルを参照している すべてのキャッシュが自動削除されるため(自動削除しない設定も可能)、 更新処理が多いシステムではオンメモリクエリキャッシュを有効にしていることでかえって遅くなります。 キャッシュのヒット率が 70% 以下の場合は、オンメモリクエリキャッシュの設定を有効にしないほうが良いでしょう。
- Watchdog 機能 を追加しました。(Atsushi Mitani, Yugo Nagata)
Atsushi Mitani が作成し、Yugo Nagata がテストしました。
- 概要
-
watchdog プロセスは pgpool-II 本体から起動される、高可用性を目的としたプロセスです。以下の機能を提供します。
- pgpool サービスの死活監視
-
watchdog は、pgpool のプロセスではなくサービスの応答を監視します。 監視対象の pgpool から PostgreSQL に問い合わせを行ない、その応答をチェックします。
また watchdog は、pgpool から上位のサーバ(アプリケーションサーバなど)への接続も監視します。 上位サーバから PostgreSQL への接続・応答を pgpool のサービスとして死活監視します。
- watchdog プロセスの相互監視
-
各 watchdog はお互いの監視対象のサーバの情報を交換します。 これにより、pgpool サーバの情報を最新に保てるだけでなく、 各 watchdog プロセスの相互 監視を行なっています。
- 障害発生検知時のアクティブ、スタンバイ切り替え
-
pgpool のサービスに障害を検知した場合、watchdog は他の watchdog に障害検知を通知します。 故障した pgpool がアクティブの場合、他の watchdog は新しいアクティブを投票で決め、 アクティブ・スタンバイの切り替えを行ないます。
- サーバ切り替えと連動した仮想 IP アドレスの自動付け替え
-
スタンバイが新しいアクティブに昇格する際、新アクティブ機の watchdog は アクティブ用の仮想 IP インターフェースを起動します。 一方、旧アクティブ機の watchdog はアクティブ用仮想 IP インターフェースを停止します。
これにより、サーバが切り替わった後もアクティブは同じ IP アドレスでサービスを継続することができます。
- サーバ復旧時、スタンバイ機としての自動登録
-
障害機の復旧や新規サーバを追加する場合、watchdog はサーバの情報を他のwatchdog に通知し、 他の watchdog からはアクティブや他のサーバの情報を受け取ります。
これにより追加したサーバはスタンバイ機として自動的に追加されます。
- 新しいパラメータ
-
- watchdog を使用するかどうかを指定するパラメータ use_watchdog 追加しました。(Atsushi Mitani)
- pgpool-II の死活監視に関するパラメータ wd_interval、 wd_life_point、 wd_lifecheck_query を追加しました。(Atsushi Mitani)
- アプリケーションサーバなど上部サーバへの接続に関するパラメータ trusted_servers、 ping_path を追加しました。(Atsushi Mitani)
- watchdog の相互死活監視に関するパラメータ wd_hostname、 wd_port、 other_wd_port、 other_pgpool_hostname、 other_pgpool_port を追加しました。 (Atsushi Mitani)
- 仮想 IP に関するパラメータ delegate_IP、 ifconfig_path、 if_up_cmd、 if_down_cmd、 arping_path、 arping_cmd を追加しました。(Atsushi Mitani)
- チュートリアル
オンメモリクエリキャッシュ と Watchdog 機能 のチュートリアルを作成しました。(Nozomi Anzai)
改良
- HP-UX や AIX のような vsyslog を持たないプラットフォームもサポートするようにしました。(Tatsuo Ishii)
- ヘルスチェックで、リトライ回数とリトライ間隔秒数を指定できるようにしました。
このために、health_check_max_retries と
health_check_retry_delay というパラメータを新設しています。(Tatsuo Ishii)
パッチは Matt Solnit さんが作成しました。
Subject: [Pgpool-hackers] Health check retries (patch)
From: Matt Solnit
Date: Fri, 18 Nov 2011 16:28:44 -0500 - クエリの解析に失敗したとき、クライアントの IP とポート番号をログに書き出すようにしました。(Tatsuo Ishii)
これは、log_connections を有効にしていなくても、 問題のあるクエリを発行したのがどのクライアントかを知るのに有用です。 特にログ出力の多く忙しい Webシステムで役立ちます。
- pool_process_query() が無限ループする場合があったのを修正しました。(Tatsuo Ishii)
これは、以下がそろったときに起こる可能性がありました。
- クエリが実行中でない
- マスタ以外のノードがデータを保持している
以下で報告されました。
Subject: [pgpool-general: 43] Re: [Pgpool-general] seemingly hung pgpool process consuming 100% CPU
From: Lonni J Friedman
Date: Tue, 6 Dec 2011 16:23:41 -0800 - SHOW pool_nodes に role の列を足しました。 この列には Primary か Standbyかが出力されます。(Tatsuo Ishii)
- PostgreSQL 9.2 に対応しました。(Tatsuo Ishii)
- SHOW pool_status の出力結果に、 backend_data_directory, ssl_ca_cert, ssl_ca_cert_dir がなかったので追加しました。 また、pgpool.conf の順にソートしました。(Nozomi Anzai)
- pgpool.conf のサンプルファイルで、system db に関するパラメータをコメントアウトしました。(Nozomi Anzai)
- failover/failback/followmaster コマンド に新しいパラメータを追加しました。(Tatsuo Ishii)
%r: new master port number %R: new master database cluster path
- md5 認証のパスワードを変更が reload でできるようにしました。(Tatsuo Ishii)
これまでは pgpool-II を再起動する必要がありました。 このパッチは Gurjeet Singh さんが作成しました。
- マニュアルの見た目を改善しました。また、パラメータ名などページ内リンクを増やしました。(Nozomi Anzai)
- is_set_transaction_serializable() 関数から使用されていない引数 query を削除しました。(Tastuo Ishii)
- pgpool.conf の on memory query cache セクションのコメントを他のセクションと同じ様式に修正しました。(Tatsuo Ishii)
- pgpool.conf.sample-master-slave, pgpool.conf.sample-replication, pgpool.conf.sample-stream に 抜けていたオプション health_check_max_retries, health_check_retry_delay を追加しました。(Tastuo Ishii)
バグ修正
- Raw モードでのメモリリークを修正しました。(Tatsuo Ishii)
- Raw モードでのフェイルオーバ・フェイルバックを修正しました。(Tatsuo Ishii)
- 対象ノードがマスタでないときに、フェイルオーバしませんでした。
- ノードが接続受付状態でないとき、どのノードをマスタにするか選定できませんでした。
- connect() 中にヘルスチェックのリトライができるようにしました。(Tatsuo Ishii)
これは、システムがセキュリティ上の理由で接続先に接続できなかったという メッセージを返さないように設定されているときに、sigalarm がブロックされているという報告によります。 変更の一部は Stevo Slavic さんが提供しました。
Subject: [pgpool-general: 131] Healthcheck timeout not always respected
From: From: Stevo Slavic
Date: Tue, 10 Jan 2012 21:16:01 +0100 - 各ノードにおいて、トランザクション状態によって COMMIT / ABORT するかどうかを判定できるように、
pool_send_and_wait() を修正しました。(Tatsuo Ishii)
マルチステートメントが送信されたとき、明示的なトランザクション内にあるプ ライマリか、明示的なトランザクション内でないスタンバイで発生する可能性が ありました。
これは、[pgpool-general-jp: 1049] で報告されました。
Subject: [pgpool-general-jp: 1049] COMMITでエラー
From: 稲村暢亮
Date: Mon, 30 Apr 2012 13:48:48 +0900 - Solaris でのロードバランスを修正しました。(Tatsuo Ishii)
Solaris での random() 関数の仕様のために問題があったため、rand() に変更しました。
この事象は [pgpool-general: 396] で報告されました。
[pgpool-general: 396] strange load balancing issue in Solaris
From: Aravinth
Date: Sat, 28 Apr 2012 07:26:58 +0530 - パラレルモードでないとき、pcp_systemdb_info コマンドが segfault してたのを修正しました。(Nozomi Anzai)
- "unnamed prepared statment does not exist" というエラーが出るのを修正しました。(Tatsuo Ishii)
このエラーは pgpool が内部的に発行しているクエリで発生し、 クライアントが発行する unnamed ステートメントを破壊していました。
拡張問い合わせクエリが実行されたときには、内部的に発行するクエリのステートメントとポータルに 名前をつけるようにしました。
- ホットスタンバイモードでクエリ衝突が起きたときにハングアップするのを修正しました。(Yugo Nagata)
これは、以下の手順で再現します。
(S1) BEGIN; (S1) SELECT * FROM t; (S2) DELETE FROM t; (S2) VACUUM t;
- [pgpool-general: 672]
で報告された、process_query() のバグを修正しました。(Tatsuo Ishii)
プライマリでは処理するデータがなく スタンバイにはある状態のときに、 プライマリの処理を待ってしまうことがありました。
Subject: [pgpool-general: 672] Transaction never finishes
From: Luiz Pasqual
Date: Thu, 28 Jun 2012 09:55:23 -0300 - wait_for_query_response() が、frontend がないときには何もしないように修正しました。(Tatsuo Ishii)
バックエンドをリセットする reset_query_list のクエリを実行に 時間がかかったときに発生する可能性があり、またクラッシュすることがありました。
- マスタ・スレーブモードでの BEGIN TRANSACTION の扱いを修正しました。(Tatsuo Ishii)
これは [pgpool-general: 714] で報告されました。
3.1 以降、BEGIN TRANSACTION をすべてのノードに送るようにしました。 PostgreSQL の仕様では、スタンバイノードには BEGIN TRANSACTION READ WRITE を送ることはできませんが、 BEGIN WORK ISOLATION LEVEL SERIALIZABLE についてチェックしておらず、スタンバイノードに送信していました。 もちろんこれは誤りで、スタンバイノードが SERIALIZABLE モードになることは許されていません。
そのため、BEGIN WORK ISOLATION LEVEL SERIALIZABLE をチェックするようにしました。
Subject: [pgpool-general: 714] Load Balancing / Streaming Replication / Isolation Level serializable
From: Philip Hofstetter
Date: Wed, 11 Jul 2012 17:04:26 +0200 - SET TRANSACTION ISOLATION LEVELSERIALIZABLE などのクエリはプライマリのみに送るよう
send_to_where() を修正しました。(Tatsuo Ishii)
マスタ・スレーブモードで、以前はこのクエリはプライマリだけではなくスタンバイにも送られていましたが、 もちろんこれはエラーとなります。同じようなクエリとして以下のものがあります。
- SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE
- SET transaction_isolation TO 'serializable'
- SET default_transaction_isolation TO 'serializable'
これは [pgpool-general: 715] で報告されました。
Subject: [pgpool-general: 715] Re: Load Balancing / Streaming Replication / Isolation Level serializable
From: Tastuo Ishii
Date: Thu, 12 Jul 2012 00:16:58 +0900 - オンメモリクエリキャッシュで memcached を利用している場合、
memcached サーバが停止していてもエラーを起こさないようにしました。(Tatsuo Ishii)
これは主に、memcached_get() が MEMCACHED_NOTFOUND 以外のエラーを返した場合には、 pool_fetch_cache() が "cache not found" を装うように修正することで対処しました。 また、その場合には後のエラーを防ぐために pool_config->memory_cache_enabled を 0 にセットするようにしました。
- rerun libtoolize with --copy and --force option を実行しました。(Tatsuo Ishii)
これにより環境によって発生するビルドの問題が回避できます。以下のコマンドが実行されました。
libtoolize --copy --force aclocal autoheader automake -a autoconf
- SSL_read() が不明のエラーを返した場合には EOF の検出とみなし、呼出元の pool_read() には
0 を返すよう pool_ssl_read() を修正しました。(Tatsuo Ishii)
これは libpq と同じ振る舞いです。また、これにより pool_read() での望ましくないフェイルオーバを回避することが出来ます。 これは、pool_read() は下層の I/O 関数(read(2), pool_ssl_read)が -1 を返したときにフェイルオーバを引き起こすからです。
- SSL エラー時に、リトライすべきときにしていなかったのを修正しました。 (Tatsuo Ishii)
- ハングアップを起こさないよう pool_process_query() を修正しました。 (Tatsuo Ishii)
プライマリ以外のノードがパケットを送信した際に、pgpool はセッションを終了しようとしてハングアップすることがありました。 これは ssl_read が エラーではなく EOF を返すようになり、フェイルオーバが実行されなくなっためです。 例えば [pgpool-gerenal: 766] では以下のような報告があります。
2012-07-17 00:11:03 NZST [15692]: [257-1] ERROR: canceling statement due to conflict with recovery 2012-07-17 00:11:03 NZST [15692]: [258-1] DETAIL: User query might have needed to see row versions that must be removed. 2012-07-17 00:11:03 NZST [15692]: [259-1] STATEMENT: <SNIP> 2012-07-17 00:11:03 NZST [15696]: [366-1] FATAL: terminating connection due to conflict with recovery 2012-07-17 00:11:03 NZST [15696]: [367-1] DETAIL: User query might have needed to see row versions that must be removed.
このケースでは、pool_process_query() は POOL_END ではなく POOL_ERROR を返すべきです。
Subject: [pgpool-general: 766] Re: pgpool dropping backends too much
From: Karl von Randow
Date: Thu, 19 Jul 2012 16:07:41 +1200 - バックエンドから来たたくさんのクエリ結果を読み込んでいる間に
フロントエンドが終了したときに、pgpool はバックエンドからの読み込みを続行し、
すべてのクエリが送られるまでフロントエンドへの書き込みを行ないます。(Tatsuo Ishii)
クエリ結果が巨大だとこれは非常に長い時間を要します。 pgpool のセッションを極力早く終了するには、レプリケーションモード以外では、 フロントエンドへの書き込みに失敗したらエラーを返すように、pool_flush_it を変更しました。 レプリケーションモードでは、以前どおりの挙動、すなわちバックエンド間での同期書き込みを行ないます。
そのほか、SimpleForwardToFrontend が、pool_write_and_flush がエラーを返してきたときに それを無視せず、認識するようにしました。
3.1.9 (hatsuiboshi) 2013/09/06
概要
このバージョンは 3.1.8 に対するバグ修正リリースです。
バグ修正
- doc/basebackup.sh スクリプトの ssh コマンドの間違いを修正しました。(Tatsuo Ishii)
-
レプリケーションモードにおけるプリペアド文のパース処理を修正しました。(Tatsuo Ishii)
レプリケーションモードで SELECT 以外のクエリをパースする際には、 ノード間の一貫性保持のため自動的にトランザクションが開始されますが、 トランザクションを閉じる処理が行われていませんでした。 そのため、実際に誤っているクエリだけではなく、その次にパース処理されたクエリもアボートされていました。
このバグは [pgpool-general: 1877] で Sean Hogan さんにより報告されました。
[pgpool-general: 1877] current transaction is aborted, commands ignored
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001905.html - 日本語ドキュメントの typo を修正しました。 (Yugo Nagata)
3.1.8 (hatsuiboshi) 2013/07/10
概要
このバージョンは 3.1.7 に対するバグ修正リリースです。
バグ修正
- man ページに -D オプションの記述を追加しました。(Tatsuo Ishii)
-
オンラインリカバリ時のフェイルバックの完了待機でタイムアウト処理をするようにしました。(Tatsuo Ishii)
これによりリカバリが永遠に終わらず pgpool-II が終了できなくなる状況を回避します。 この現象は特に follow_master_command の実行中に起こり得ました。
- ストリームレプリケーションモードでの follow_master_command 実行時に、%H に新しいプライマリノードが正しく割り当てられないバグを修正しました。 (Tatsuo Ishii)
-
PostgreSQL がエラーを返したときに do_query() がハングしないよう修正しました。
(Tatsuo Ishii)
典型的な症状が「pg_stat_activety によると SELECT が実行されたままのように見える」というものです。 これを解決するため、pgpool-II は当該プロセスを終了させ、既存のコネクションを捨てるように修正しました。
-
拡張プロトコルの際に do_query で発生しうるハングアップを修正しました。
(Tatsuo Ishii)
これは insert_lock が有効で、pgpool_catalog.insert_lock が存在することに起こり得ます。 詳しくは [pgpool-general: 1684] を参照してください。
[pgpool-general: 1684] insert_lock hangs
http://www.sraoss.jp/pipermail/pgpool-general/2013-May/001711.html -
COMMIT 時エラーに不要なバックエンド切り離しを行わないようにしました。
(Tatsuo Ishii)
マスタースレーブモードで、COMMIT 時にマスターノードでエラーが発生していたとしても、他のスレーブノードが正常な場合にはバックエンドを切り離す必要はありません。 これは、遅延トリガーのために "kind mismatch error" が発生しうるからです。
-
pgpool_regclass を pg_catalog スキーマに登録するよう修正しました。
(Tatsuo Ishii)
これは postgres_fdw のような、スキーマ検索パスが pg_catalog に限定されているクライアントに対応するために必要です。
- pg_md5 コマンドで起こりうるクラッシュを修正しました。(Muhammad Usama)
-
スタートアップパケットに PostgreSQL ユーザ情報が含まれていなかった場合に発生する子プロセスのセグメンテーション違反を修正しました。(Yugo Nagata)
このバグは以下を実行することにより再現できます。
$ psql -p 9999 -U ''enable_pool_hba が有効の場合は子プロセスがセグメンテーション違反で異常終了し、無効の場合には以下のメッセージがログに出力されていました。
ERROR: pool_discard_cp: cannot get connection pool for user (null) database (null)また、両方の場合で psql はフロントエンドに何のメッセージ出力せずに終了していました。 修正後は、スタートアップパケットに PostgreSQL ユーザが指定されていない場合には以下のメッセージがログとフロントエンドの両方に出力されます。 これは PostgreSQLと同じ振る舞いです。
FATAL: no PostgreSQL user name specified in startup packet - マニュアルの ssl_sa_cert, ssl_ca_cert_dir オプションの説明を SSL セクションに移動しました。(Yugo Nagata)
- ssl_sa_cert, ssl_ca_cert_dir オプションの説明を日本語マニュアルに追加しました。(Yugo Nagata)
-
pcp_recovery_node コマンドで、バックエンドノード番号をチェックするように修正しました。(Yugo Nagata)
不正な値が使用された場合、リカバリで実行されるスクリプトの引数に空の値が渡されており、誤動作の原因となっていました。 特にベースバックアップを行うスクリプトで、rsync が関係のないファイルを削除してしまうことがありました。
3.1.7 (hatsuiboshi) 2013/04/26
概要
このバージョンは 3.1.6 に対するバグ修正リリースです。
バグ修正
- 設定パラメータの一覧を表示する "SHOW pool_status" で pool_passwdが表示されていないのを修正しました。(Yugo Nagata)
-
拡張プロトコルの処理における timestamp の書き換えに関する長い間見過ごされていてたバグを修正しました。(Tatsuo Ishii)
Parse() 関数は、parse メッセージの書き換えの際に palloc() を使ってメモリを確保していました。 書き換えられたメッセージは pool_create_sent_message() 関数などが管理するデータ領域に格納されますが、これが問題となっていました。 この関数ではデータが session context memory 中に存在することを想定しているのに対し、 palloc() では query context においてメモリの割り当てを行っており、この領域は query context 終了時に解放されます。しかし、他の関数もこのメモリ領域を解放しようとするため、 セグメンテーション違反や二重解放を含む様々な問題の原因となっていました。 この問題は、書き換えたメッセージを格納するメモリを session context を用いて確保するこで修正されました。 これは pgpool-II 3.0 以来ずっと存在していたバグです。
この問題は、Naoya Anzai さんによって解析され、パッチが提供されました。
[pgpoolgenera-jp: 1146]
拡張問い合わせプロトコルでセグメンテーションフォルト
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001145.html -
md5認証で長いユーザ名を処理する際のバグを修正しました。(Tatsuo Ishii)
ユーザ名が 32 バイトより長い場合、md5 認証が動作していませんでした。 この問題は [pgpool-general: 1526] で Thomas Martin さんにより報告されました。
[pgpool-general: 1526]
[pgPool-II 3.2.3] MD5 authentication and username longer than 32 characters.
http://www.pgpool.net/pipermail/pgpool-general/2013-March/001551.html - レプリケーション遅延の計算はスタンバイサーバがプライマリサーバより遅れている場合にのみ行うよう修正しました。(Yugo Nagata)
タイミングによってスタンバイよりプライマリの方がレプリケーションが遅延 しているように見える場合があり、その場合には負値の遅延が計算されていました。 この値が符号無し変数に代入されると、実際には遅延が生じていないにも関わらず、 ログに遅延が負値で出力され、されに悪いことには、ロードバランス機能により SELECT クエリがプライマリに振り分けられ、その結果プライマリの負荷が高まる ことがありました。
この問題は Saitoh Hidenori さんによって報告、解析されました。
[pgpool-genera-jp: 1145]
レプリケーション遅延確認の不具合について
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001144.html - pgpool-recovery が PostgreSQL 9.3 に対応しました。 (Tatsuo Ishii)
パッチは Asif Rehman さんにより提供され、これに Tatsuo Ishii が若干の修正を 加えました。
[pgpool-hackers: 180]
compile error in ppool-recovery
http://www.pgpool.net/pipermail/pgpool-hackers/2013-April/000179.html - pool_has_pgpool_regclass が pgpool_regclass() の実行権限をチェックするよう修正しました。 (Tatsuo Ishii)
pgpool_regclass が存在する場合でも、pgpool がこの関数を実行できない場合に、 バックエンドへの接続がハングしていました。この問題は、pgpool_regclass から実行権限を剥奪し、ネイティブレプリケーションモードで INSERT を実行 することで再現可能です。
この問題は bugtrack #53 で報告されました。
#53 pgpool_regclas hangs all connections
Date: 2013-04-04 13:35
Reporter: tmandke
http://www.pgpool.net/mantisbt/view.php?id=53 - detect_postmaster_down_error() のエラーメッセージを修正しました。(Tatsuo Ishii)
例えば、"LOG: detect_stop_postmaster_error: detect_error error" を "LOG: detect_postmaster_down_error: detect_error error" に修正するなどです。
3.1.5 (hatsuiboshi) 2013/02/08
概要
このバージョンは3.1.5に対するバグ修正リリースです。
- md5 認証で競合が発生する不具合が修正されました。(Tatsuo Ishii)
pool_passwd のファイル識別子は pgpool の親プロセスで開かれたものが子プロセスに引き継がれてます。 複数の接続で同時に md5 認証を行う際には、pool_get_passwd が呼ばれ、ファイル識別子が走査されますが、 ファイル識別子が共有されるために md5 認証が失敗することがありました。 この問題は、個々の子プロセスで pool_passwd ファイルを開き直すことで解決されました。
この問題は [pgpool-general:1141] にて、Jason Slagle さんによって報告・解析されました。
[pgpool-general: 1141] Possible race condition in pool_get_passwd
From: Jason Slagle
Date: Sun, 28 Oct 2012 01:12:52 -0400
http://www.sraoss.jp/pipermail/pgpool-general/2012-October/001160.html - pcp_attach_node, pcp_detach_node を繰り返し実行したときに起こるハングアップを
修正しました。 (Tatsuo Ishii)
pcp_attach_node, pap_detach_node によりノードステータスが変更された時、failover() は子プロセスに SIGUSR1 シグナルを送り、プロセスの終了とノードステータスの更新を行います。 その時に発せられた SIGCHLD シグナルは全て reaper() ハンドラで受信しますが、 システムの負荷とタイミングによりこれが失敗することがありました。 pcp プロセスによる SIGCHLD シグナルの受信に失敗した場合に、これがゾンビプロセスとなり、 pcp プロセスが永遠に再起動されなくなっていました。
この問題はバグトラック #32(oleg_myrk さんによる)他で報告されました。
#32 PGPool hangs on pcp_attach/detach
Reporter: oleg_myrk
Date: 2012-10-24 00:01
http://www.pgpool.net/mantisbt/view.php?id=32 - pool_send_severity_message() で未初期化のメモリを使用しないよう修正しました。
(Tatsuo Ishii)
このバグによりセグメンテーション違反が発生することがありました。 バグトラック #33 に投稿された valgrind 実行結果(dudee さんによる)にて報告されました。
#33 pgpool-II 3.2.1 segfault
Reporter: dudee
Date: 2012-10-30 19:16
http://www.pgpool.net/mantisbt/view.php?id=33 - 通常のテーブルと同名の一時テーブルがあるときに、クエリキャッシュの結果が不正になる
バグを修正しました。 (Tatsuo Ishii)
以下はバグを引き起こす処理の例です。
1) CREATE TABLE t1(i int); -- 通常のテーブルを作成 2) INSERT INTO t1 VALUES(1); 3) SELECT * FROM t1; -- クエリキャッシュが作成される 4) CREATE TEMP TABLE t1(i int); -- 一時テーブルの作成 5) SELECT * FROM t1; -- 誤ったクエリキャッシュが作成される!
#3 で t1 のキャッシュが生成されますが、#5 でこれが不正に使われており、一時テーブル t1 が 一時テーブルと見なされていないのが問題でした。
- ヘルプメッセージに -f オプションの説明を追加しました。 (Tatsuo Ishii)
- pcp または worker 子プロセスの終了イベントを受信したときに、reaper() で wait3()
ループを終了しないように修正しました。 (Tatsuo Ishii)
修正前は、reaper() は子プロセスの終了イベントを誤って無視してしまい、ゾンビプロセスを作り、 新しいプロセスを生成できないことがありました。
この問題は[pgpool-general-jp: 1123]にて、後藤さんより報告され、修正の示唆を頂きました。
[pgpool-general-jp: 1123] Re: オンラインリカバリ後にゾンビプロセスになる
From: GOTO, Daisuke
Date: Wed, 21 Nov 2012 19:56:17 +0900
http://www.sraoss.jp/pipermail/pgpool-general-jp/2012-November/001122.html - pool_search_relcache() が REAL_MASTER_NODE_ID ではなく MASTER, MASTER_NODE_ID
を使用するように修正しました。 (Tatsuo Ishii)
ストリーミングレプリケーションモードで 0 番ノードがフェイルバックした場合、pgpool は 子プロセスを再起動しません。そのとき、REAL_MASTER_NODE_ID は 0 番ノードの接続情報を 探しにいきますが、これはバックエンドへの新しい接続が確立するまで存在しません。 そのため、接続情報の参照によって、セグメンテーションフォルトが発生していました。 この状況でも、MASTER または MASTER_NODE_ID は以前にキャッシュされた マスターノード ID を見にいくため、安全に使うことが出来ます。
- ストリーミングレプリケーションモードでレプリケーション遅延が大きくなったときに、
"portal not found" エラーが発生するバグを修正しました。 (Tatsuo Ishii)
これは delay_threshold が導入以来、ずっと存在していたバグです。
bind, describe, execute の実行時に遅延が域値を越えた場合、送り先の DB ノードは 変更されていました。しかし、parse がそれとは異なるノードに送られていた場合、送り先ノードには parse された ステートメントやポータルが存在しないために bind, describe, execute は 失敗していました。 修正後は、大きな遅延が発生した場合でも、これらは parse が実行された ノード以外には送られないようになりました。
- pg_md5 で、ユーザからのパスワード入力の後には改行するように修正しました。 (Yugo Nagata)
- watchdog のポート番号が既に使用されていた場合にエラーメッセージを出力するよう修正しました。
(Yugo Nagata)
この問題は [pgpool-general: 1167] で Will Ferguson さんによって報告されました。
[pgpool-general: 1167] Re: Watchdog error - wd_init: delegate_IP already exists
From: Will Ferguson
Date: Tue, 6 Nov 2012 13:03:36 +0000
http://www.sraoss.jp/pipermail/pgpool-general/2012-November/001186.html - コネクションプールが存在しない場合には、child_exit() が send_frontend_exits()
を呼ばないよう修正しました。 (Tatsuo Ishii)
send_frontend_exits() は pool_connection_pool で指されてるオブジェクトを参照しているため、 修正前にはセグメンテーションフォルトが発生していました。バグトラック #44 の tuomas さんの報告によります。
#44 pgpool went haywire after slave shutdown triggering master failover
Reporter: tuomas
Date: 2012-12-11 00:33
http://www.pgpool.net/mantisbt/view.php?id=44 - pool_read() が不正なパケットを読み込んだ場合に、read_startup_packet() がアラームクロック
をリセットして StartupPacket を解放するよう修正しました。 (Nozomi Anzai)
修正前は、pgpool ポートの監視を行うプログラムの接続により、認証のタイムアウトが発生していました。 この問題は、バグトラック #35 で報告されました。
#35 Authentication is timeout
Reporter: tuomas
Date: 2012-11-20 11:54
http://www.pgpool.net/mantisbt/view.php?id=35 - pool_open() が誤ったバッファポインタを初期化していたバグを修正しました。 (Tatsuo Ishii)
このポインタは事前に memset() によって初期化されているため、実際にはこのバグによる害は ありませんでした。
- ドキュメント中の、「パラメータ変更に再起動が必要かどうか」の情報を追記・修正しました。(Yugo Nagata)
- pool_passwd に関する記述を pgpool_conf.sample*、および,ドキュメントに追加しました。 (Yugo Nagata)
3.1.5 (hatsuiboshi) 2012/10/12
概要
このバージョンは3.1.4に対するバグ修正リリースです。
バグ修正
- read_startup_packet() を修正しました。(Tatsuo Ishii)
パケット長が 0 以下のときは直ちに return するべきでしたが、そうなっていなく、 メモリ確保時にエラーになっていました。
これは pgpool-general:886 を参照してください。また、キャンセルアラームを追加しました。
[pgpool-general: 886] read_startup_packet: out of memory
From: Lonni J Friedman
Date: Wed, 8 Aug 2012 10:18:15 -0700
http://www.sraoss.jp/pipermail/pgpool-general/2012-August/000896.html - s_do_auth() に NOTICE メッセージを追加しました。(Tatsuo Ishii)
これがなかったために、ヘルスチェックが false アラームを受け取りフェイルオーバしていました。
これはバグトラックで報告されました。
#25 s_do_auth doesn't handle NoticeResponse (N) message
Date: 2012-08-28 03:57
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=25 - s_do_auth() から、不要かつ混乱をまねくデバッグメッセージを削除しました。(Tatsuo Ishii)
- SSL モードでの無限ループを修正しました。 (Tatsuo Ishii)
フロントエンドの SSL レイヤで溜っているデータがあるとき、 pool_process_query() がバックエンドに溜っているデータをチェックします。 もしそれが無かったときは再度ループして、フロントエンド/バックエンドがバッファを受け取っていないか is_cache_empty() を以ってチェックします。 しかし、フロントエンドの SSL レイヤでデータが溜っているのを一度検知すると、 バックエンドに行ってまたチェックしようとします(無限ループ)。
これを解決するには、フロントエンドの SSL レイヤに溜っているデータがあり かつ クエリが実行中でなければ、ProcessFrontendResponse() を呼んで フロントエンドへの新しいリクエストをするようにしました。
- is_system_catalog() で、可能ならば pgpool_regclass を使うようにしました。(Tatsuo Ishii)
- pool_get_insert_table_name() のメモリリークを修正しました。(Tatsuo Ishii)
nodeToString() でセッションコンテクストのメモリコンテクストを使ったあと、 セッション終了までは、メモリを開放していませんでした。
詳しくはバグトラックをご覧ください。
#24 Severe memory leak in an OLTP environment
Date: 2012-08-28 03:43
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=24 - do_query() のセグメンテーションフォルトを修正しました。(Tatsuo Ishii)
クエリキャッシュが有効で拡張問い合わせが使われているとき、do_query() はシステムカタログに接続し、 pool_read2() を使います。 しかし、parse メッセージパケットを Parse() で取得し、パケットの内容が pool_read2() のバッファにあります。 このため、do_query() はパケットの内容を分割できず、セグメンテーションフォルトを引き起こしていました。
これを解決するために、メモリを確保し、パケット内容をコピーし、Parse() を飛ばすようにしました。 ただし、パケットの中にはクエリコンテクストが参照しているクエリ文字列も含まれています。 そのため、このクエリ文字列をコピーしてポインタをクエリコンテクストに保持する必要があります。
これは、Parse() だけの話でなく、他のプロトコルモジュールにもある問題と考えています。 本修正はそれらにも適用しますが、そのためには、ProcessFrontendResponse() を変更します。
この問題はバグトラック #21 で報告されました。
#21 pgpool-II 3.2.0 cannot execute sql through jdbc
Date: 2012-08-17 16:31
Reporter: elisechiang
http://www.pgpool.net/mantisbt/view.php?id=21
3.1.4 (hatsuiboshi) 2012/08/06
概要
このバージョンは3.1.3に対するバグ修正リリースです。
また、PostgreSQL 9.2 に対応しました。
バグ修正
- 各ノードにおいて、トランザクション状態によって COMMIT / ABORT するかどうかを判定できるように、
pool_send_and_wait() を修正しました。(Tatsuo Ishii)
マルチステートメントが送信されたとき、明示的なトランザクション内にあるプ ライマリか、明示的なトランザクション内でないスタンバイで発生する可能性が ありました。
これは、[pgpool-general-jp: 1049] で報告されました。
Subject: [pgpool-general-jp: 1049] COMMITでエラー
From: 稲村暢亮
Date: Mon, 30 Apr 2012 13:48:48 +0900 - Solaris でのロードバランスを修正しました。(Tatsuo Ishii)
Solaris での random() 関数の仕様のために問題があったため、rand() に変更しました。
この事象は [pgpool-general: 396] で報告されました。
[pgpool-general: 396] strange load balancing issue in Solaris
From: Aravinth
Date: Sat, 28 Apr 2012 07:26:58 +0530 - SHOW pool_status の出力結果に、 backend_data_directory, ssl_ca_cert, ssl_ca_cert_dir がなかったので追加しました。(Nozomi Anzai)
- パラレルモードでないとき、pcp_systemdb_info コマンドが segfault してたのを修正しました。(Nozomi Anzai)
- "unnamed prepared statment does not exist" というエラーが出るのを修正しました。(Tatsuo Ishii)
このエラーは pgpool が内部的に発行しているクエリで発生し、 クライアントが発行する unnamed ステートメントを破壊していました。
拡張問い合わせクエリが実行されたときには、内部的に発行するクエリのステートメントとポータルに 名前をつけるようにしました。
- ホットスタンバイモードでクエリ衝突が起きたときにハングアップするのを修正しました。(Yugo Nagata)
これは、以下の手順で再現します。
(S1) BEGIN; (S1) SELECT * FROM t; (S2) DELETE FROM t; (S2) VACUUM t;
- pid ファイルの読み書きを改善しました。(Tatsuo Ishii)
- [pgpool-general: 672]
で報告された、process_query() のバグを修正しました。(Tatsuo Ishii)
プライマリでは処理するデータがなく スタンバイにはある状態のときに、 プライマリの処理を待ってしまうことがありました。
Subject: [pgpool-general: 672] Transaction never finishes
From: Luiz Pasqual
Date: Thu, 28 Jun 2012 09:55:23 -0300 - マスタ・スレーブモードでの BEGIN TRANSACTION の扱いを修正しました。(Tatsuo Ishii)
これは [pgpool-general: 714] で報告されました。
3.1 以降、BEGIN TRANSACTION をすべてのノードに送るようにしました。 PostgreSQL の仕様では、スタンバイノードには BEGIN TRANSACTION READ WRITE を送ることはできませんが、 BEGIN WORK ISOLATION LEVEL SERIALIZABLE についてチェックしておらず、スタンバイノードに送信していました。 もちろんこれは誤りで、スタンバイノードが SERIALIZABLE モードになることは許されていません。
そのため、BEGIN WORK ISOLATION LEVEL SERIALIZABLE をチェックするようにしました。
Subject: [pgpool-general: 714] Load Balancing / Streaming Replication / Isolation Level serializable
From: Philip Hofstetter
Date: Wed, 11 Jul 2012 17:04:26 +0200 - SET TRANSACTION ISOLATION LEVELSERIALIZABLE などのクエリはプライマリのみに送るよう
send_to_where() を修正しました。(Tatsuo Ishii)
マスタ・スレーブモードで、以前はこのクエリはプライマリだけではなくスタンバイにも送られていましたが、 もちろんこれはエラーとなります。同じようなクエリとして以下のものがあります。
- SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE
- SET transaction_isolation TO 'serializable'
- SET default_transaction_isolation TO 'serializable'
これは [pgpool-general: 715] で報告されました。
Subject: [pgpool-general: 715] Re: Load Balancing / Streaming Replication / Isolation Level serializable
From: Tastuo Ishii
Date: Thu, 12 Jul 2012 00:16:58 +0900
3.1.3 (hatsuiboshi) 2012/01/31
概要
このバージョンは3.1.2に対するバグ修正リリースです。
バグ修正
- m4 ファイルを追加しました。これにより古い OS で起こるコンパイルの問題を回避できます。(Tatsuo Ishii)
- フェイルオーバを適切に処理するよう detect_postmaster_down_error() 関数を修正しました。(Tatsuo Ishii)
以前はバックエンドソケットの読み込みに失敗することがありました。
- シグナル割り込みによって、セマフォが解放されないままプロセスが終了することがあるバグを 修正しました。(Tatsuo Ishii)
- reset_query 時のメモリリークを修正しました。 (Tatsuo Ishii)
- pool_ssl_read() 関数が大きいサイズのデータを読み込めるよう修正しました。(Tatsuo Ishii)
以下の報告によるものです。
http://www.pgpool.net/pipermail/pgpool-general/2012-March/000299.html - syslog を有効にしたときに起こるデッドロックを修正しました。(Tatsuo Ishii)
このバグは以下で報告され、パッチは Gilles Darold さんにより提供頂きました。
http://www.pgpool.net/mantisbt/view.php?id=9 - マスター・スレーブモードで複数の文を扱えるように修正しました。(Tatsuo Ishii)
以前は BEGIN, END 等を用いた複数文からなるクエリはエラーとなっていました。
- マスタサーバがダウンした際に、子プロセスが NULL ポインタを参照しようとするバグを修正しました。(Tatsuo Ishii)
このバグは以下で報告されました。
http://www.pgpool.net/mantisbt/view.php?id=51 - マスターノードIDの初期値が正しく設定されるように pool_start_query() 関数を修正しました。(Tatsuo Ishii)
このバグのためにセグメントフォルトが発生することがありました。
- pool_setall_node_to_be_sent() 関数において BACKEND_INFO マクロの代わりに
private_backend_status 変数を利用するよう修正しました。(Tatsuo Ishii)
これは状況により BACKEND_INFO が利用できなくなる場合があったためです。(Tatsuo Ishii)
- 子プロセスがレプリケーション遅延チェック要求を送り続けることがあるバグを修正しました。(Tatsuo Ishii)
以前はフェイルオーバ時にレプリケーション遅延をチェックする worker プロセスを限定した条件でしか 起動していませんでしたが、これは間違いで、常に再起動する必要があります。
- デバッグメッセージにヌル文字が含まれないように修正しました。 ヌル文字が含まれるログは、バイナリファイルであると認識されることがあります。(Toshihiro Kitagawa)
- 以下の場合に parser memory をリストアするよう SimpleQuery() 関数を修正しました。
- 組み込み show コマンド使用時
- パラレルクエリモード
- クエリキャッシュ使用時
- PREPARE 文でエラーが起きた際に発生するハングアップを修正しました。(Toshihiro Kitagagwa)
Tominari Katsumata さんの報告に基づきます。
- doc/pgpool-fr.html を Makefile.am に追加しました。 これはフランス語のドキュメントを追加した際に、追加し忘れたものです。(Tatsuo Ishii)
- デーモンモードで syslog を有効にしている際に md5 認証で発生するハングアップを修正しました。(Yugo Nagata)
3.1.2 (hatsuiboshi) 2012/01/31
概要
このバージョンは3.1.1に対するバグ修正リリースです。
バグ修正
- トランザクション隔離レベルの処理で、READ UNCOMMITTED と REPEATABLE READ が解釈できていませんでしたが、 これを修正しました。(Tatsuo Ishii)
- 以下のスレッドで報告されている無限ループを修正しました。(Tatsuo Ishii)
http://www.pgpool.net/pipermail/pgpool-genral/2011-December/000099.html
プライマリからから受け取ったバッファが空である一方で、スタンバイのどれかが 受け取ったバッファが空でないとき、pgpool へのパケットが送られてしまう、 という可能性が考慮されていませんでした。この事象は例えば、postgresql.conf を再読み込みしたときに発生することがありました。
この修正では、スタンバイからしか受け取れなかったバッファは無視するようにしました。
3.1.1 (hatsuiboshi) 2011/12/06
概要
このバージョンは3.1に対するバグ修正リリースです。
バグ修正
- black_functon_list と white_function_list の読み込み処理で メモリ破壊を起こすバグを修正しました(Tatsuo Ishii)。
- check_replication_time_lag の誤ったエラーメッセージを修正しました(Tatsuo Ishii)。
ストリーミングレプリケーションの遅れのチェックのために PostgreSQL に接続できなかった時に 誤ったメッセージを出していました。 3.1以降では health_check_user はこの目的のために使われていないので、 これは誤りです。
- メモリーリークを修正しました(Toshihiro Kitagawa)。
これは、基本的に3.0.5(commit 19a4ea9215da0b61728741fc0da2271958b09238)で行われた修正と同じものです。
- strncpy()を使った修正を多数行いました(Tatsuo Ishii)。
strncpy()が使われている箇所が複数あり、そこではコピー長とバッファサイズが同じであるケースが 考慮されていません。 このため、コピー後の文字列がNULL終端されていない可能性があり、多くの問題を後で引き起こすことになります。 この問題を修正するために、ほとんどの箇所をstrlcpy()で置き換えました。
- 可能な場合にはキャッシュされたバックエンドの状態情報を更新するようにしました(Tatsuo Ishii)。
これにより、Jeff Frostから以下のメールで報告された問題が解決されました。 すなわち、 follow_master_command が正しくバックエンドの状態を読み取れない問題です。
Subject: [Pgpool-general] diagnosing BackendError from pcp_recovery_node To: pgpool-general@pgfoundry.org Date: Wed, 05 Oct 2011 15:15:07 -0700
- Windows環境でのみ必要なPGDLLIMPORTIを削除しました。
これはgccを使わない環境で問題を引き起こします。 パッチはIbrar Ahmedさんが提供しました。
3.1.0 (hatsuiboshi) 2011/09/08
概要
このバージョンは3.1系列の最初の版で、3.0系からの「メジャーバージョンアップ」にあたります。
互換性のない変更
- insert_lock のロック方法を変更しました。(Toshihiro Kitagawa)
以前のinsert_lockは、シーケンステーブルに対して行ロックを行いましたが、 現在は、pgpool_catalog.insert_lockテーブルに対して行ロックを行います。 その理由は、シーケンステーブルに対するロックが内部エラーを引き起こすため、 PostgreSQLのコア開発者がそれを許可しないことを決定したためです。
したがって、pgpool-II経由でアクセスするすべてのデータベースにinsert_lockテーブルを あらかじめ作成しておく必要があります。 もし、insert_lockテーブルが存在しない場合は、挿入対象のテーブルに対してロックを行います。 これは、pgpool-II 2.2と2.3シリーズのinsert_lockと同じ動作です。
また、過去のバージョンと互換性のあるinsert_lockを使用したい場合は、 configureオプション(--enable-sequence-lock,--enable-table-lock)で 設定できます。
- backend_socket_dir パラメータを廃止しました。
その代わりに、backend_hostname が'/'で始まるならば、 それをUNIXドメインへのパスとみなします。 backend_hostnameが空ならば、デフォルトのUNIXドメインパス(/tmp)が使われます。 これは、libpqインタフェースの規約に従います。
パッチはJehan-Guillaume (ioguix) de Rorthaisさんから頂きました。
- フェイルオーバー時にpgpool_walrecrunning()を使用せず、
プライマリノードへの昇格が完了するまで待つようになりました。(Toshihiro Kitagawa)
関数を使用しない理由はプライマリノードを確実に見つけることができないためです。 しかし、この修正にはプライマリノードが現れないときに recovery_timeout の間 pgpool-IIが待ってしまう問題がまだ残っています。
- PostgreSQL DBノード情報を出力する pool_nodes に 「ノードID」を追加しました。(Jean-Paul Argudo)
- シーケンス関数(nextval, setval)の扱いを black/white_function_listの設定に完全に従うように変更しました。 以前、それらは常に書き込み関数として扱われていました。(Toshihiro Kitagawa)
新機能
- syslog に対応しました。 パッチはGilles Daroldさんから頂き、Guillaume Lelargeさんがレビューと編集をしました。
- PostgreSQL 9.0で導入されたapplication_nameに対応しました。(Tatsuo Ishii)
コネクションが再利用されたときに、スタートアップパケットのapplication_nameをバックエンドへ送信し、 ラメータステータスをフロントエンドに返します。
- pgpool-II内部で使用するシステムカタログキャッシュの有効時間を、
秒単位で指定できる設定項目relcache_expireが追加されました。(Tatsuo Ishii)
これにより、ALTER TABLEによってテーブル定義が変更された際に、 もはや有効でない結果を利用してしまうリスクが軽減されます。
- follow_master_command パラメータを追加しました。
このパラメータには、マスタースレーブモードのストリーミングレプリケーション構成において マスタノードがフェイルオーバーした後に実行されるコマンドを指定します。
パッチはGilles Daroldさんから頂きました。
- pcp_promote_node コマンドを追加しました。
このコマンドはpgpool-IIに対して新しいマスタノードへの昇格を行います。 これは、マスタースレーブモードのストリーミングレプリケーション構成のみで使用できます。
パッチはGilles Daroldさんから頂きました。
- pcp_pool_status コマンドを追加しました。
また、対応するC APIも追加されています。
パッチはJehan-Guillaume (ioguix) de Rorthaisさんから頂きました。
- バックエンドごとのパラメータ"backend_flag"を追加しました。(Tatsuo Ishii)
これは、バックエンドごとの動作を制御します。 今は"ALLOW_TO_FAILOVER"または"DISALLOW_TO_FAILOVER"が指定できます。
- health_check_password パラメータを追加しました(Nicolas Thauvin)
- sr_check_period、sr_check_user、
sr_check_password パラメータを追加しました。(Tatsuo Ishii)
これらは、ストリーミングレプリケーションの遅延チェックとプライマリノードの決定に使用されます。
- pg_md5コマンドに--username(または-u)オプションを追加しました。(Nicolas Thauvin)
これは、UNIXアカウントを持たないユーザの管理を可能にします。 日本語ドキュメントはTatsuo Ishiiさんが修正しました。
- pgpool_adm関数をpgpool_adm/に追加しました。(Jehan-Guillaume (ioguix) de Rorthais)
これらは、pcpコマンドのように動作するC言語で書かれたユーザ定義関数です。
- 簡体字中国語版のドキュメントを追加しました(Huang Jian, Sun Peng)
- 関数をアンインストールするためのSQLファイルをsql/に追加しました(Nicolas Thauvin)
- マスタースレーブモードにおいて、unloggedテーブルに対するSELECTは、 常にマスター(primary)で実行されるようになりました(Toshihiro Kitagawa)
バグ修正
- スタンバイノードでJDBCドライバのカーソルが使用できないバグを修正しました。(Toshihiro Kitagawa)
この修正によって、マスタースレーブモードではトランザクションコマンドが すべてのノードに送られるようになります。
- 空のクエリの処理に関するバグを修正しました。(Toshihiro Kitagawa)
空のクエリはSELECTクエリと同じ扱いになります。 この修正は、空のクエリのあとのロードバランスを可能にします
- カラム定義が"DEFAULT nextval(('"x_seq"'::text)::regclass)"のようになっていても insert_lock が正しく動作するように修正しました(Toshihiro Kitagawa)
- フェイルオーバー中はエラーメッセージを出力するようにpcp_attach_node コマンドを修正しました(Toshihiro Kitagawa)
- 拡張問い合わせプロトコルでpgpool-IIがクエリを解析できないときに出力されるログメッセージが クエリを表示するよう修正しました(Toshihiro Kitagawa)
- pgpool-IIマニュアルの backend_weight に関する説明を修正しました。 それは、pgpool.confの再読み込みで変更できます(Tatsuo Ishii)
- 英語のチュートリアルドキュメント内の表現の改善と修正を行いました。 修正の提案はHuang Jianさんによるものです(Tatsuo Ishii)
- rawモードでノードを復帰させたときにノードの状態が更新されないバグを修正しました(Guillaume Lelarge)
- ストリーミングレプリケーションモードにおけるレプリケーション遅延の計算が間違っていたのを修正しました(Tatsuo Ishii)
- フェイルオーバーのログメッセージにおける誤った関数名 "notice_backend_error"を、正しいもの"degenerate_backend_set"に置き換えました(Tatsuo Ishii)
- pgpool.conf解析後の不要なログ出力を削除しました(Tatsuo Ishii)
- バックエンドを新規追加した後に起こり得るpgpool/worker子プロセスのクラッシュを修正しました。 修正はGurjeet Singhさんの提案によるものです(Tatsuo Ishii)
- FOR SHARE/UPDATE句のあるサブクエリを含むSELECTがスレーブ(standby)に送られるバグを修正しました(Tatsuo Ishii)
- PREPARE文でデフォルト値のタイムスタンプ書き換えに失敗するバグを修正しました。 これは以前は動作していましたが、3.0で動作しなくなっていました(Toshihiro Kitagawa)
- getopt_long()がない環境でpcpコマンドのコンパイルが失敗するのを修正しました(Tatsuo Ishii)
- rawモード、enable_pool_hbaが無効、バックエンドが2台以上の場合に pgpool子プロセスがクラッシュするのを修正しました(Toshihiro Kitagawa)
- メモリリークをいくつか修正しました(Toshihiro Kitagawa)
改良
- ストリーミングレプリケーション構成でのオンラインリカバリにおいて、 リカバリ終了時に子プロセスを再起動しないようにしました。 そのため、既存のセッションはオンラインリカバリ中も継続することができます(Tatsuo Ishii)
- ストリーミングレプリケーションモードにおいて、pcp_attache_node が 既存のセッションを切断しなくなりました。 ほかのモードでは依然としてセッションが切断されます(Tatsuo Ishii)。
- PostgreSQL 9.0のパーサを移植しました。 これによりPostgreSQL 9.0で新しく導入された暗黙のインデックス名を使用した CREATE INDEXが実行できるようになりました。パッチは石田さんから頂きました。
- black_function_list と white_function_listパラメータに正規表現が使えるようになりました。 パッチはGilles Daroldさんから頂き、Guillaume Lelargeさんがレビューしました。
- 読みやすいようにpgpool.confのサンプルファイルを再構成しました(Gleu)
- pgpool-IIマニュアルのすべてのパラメータに‹a name="..."›タグを 追加しました(Haruka Takatsuka)
- pgpool-IIマニュアルのストリーミングレプリケーションにおけるオンラインリカバリの説明を改善しました(Tatsuo Ishii)
- ストリーミングレプリケーションモードにおけるレプリケーション遅延をチェックするための
関数を変更しました。(Tatsuo Ishii)
現在、pgpoolはpg_last_xlog_receive_location()の代わりにpg_last_xlog_replay_location()を使用します。 修正はAnton Yuzhaninovさんの提案によるものです
- カラムのデフォルト値に任意の式を指定してもタイムスタンプ書き換えが動作するようにしました。(Tatsuo Ishii)
以前は、now()が含まれているものを検知すると、単純にそれをnow()で置き換えてました。 これは、デフォルト値の誤った書き換えを引き起こします。 例えば、timezone('utc'::text, now())です。
しかし、これは簡易プロトコルのみへの適用であることに注意してください。 拡張プロトコル(例えばJava, PHP PDO)または、SQLの"PREPARE"にはまだ適用されていません
- レプリケーション遅延のチェックに失敗したときに出力されるエラーメッセージを改良しました(Nicolas Thauvin)
- エラーメッセージ"do_md5: read_password_packet failed"をデバッグレベルにしました(Toshihiro Kitagawa)
- pgpool-regclass()をPostgreSQL 9.1でコンパイルできるようにしました(Tatsuo Ishii)
- 英語版と日本語版のpgpool-IIマニュアルを更新、同期しました(Tatsuo Ishii)
3.0.13 (umiyameboshi) 2013/09/06
概要
このバージョンは 3.0.12 に対するバグ修正リリースです。
バグ修正
- doc/basebackup.sh スクリプトの ssh コマンドの間違いを修正しました。(Tatsuo Ishii)
-
レプリケーションモードにおけるプリペアド文のパース処理を修正しました。(Tatsuo Ishii)
レプリケーションモードで SELECT 以外のクエリをパースする際には、 ノード間の一貫性保持のため自動的にトランザクションが開始されますが、 トランザクションを閉じる処理が行われていませんでした。 そのため、実際に誤っているクエリだけではなく、その次にパース処理されたクエリもアボートされていました。
このバグは [pgpool-general: 1877] で Sean Hogan さんにより報告されました。
[pgpool-general: 1877] current transaction is aborted, commands ignored
http://www.sraoss.jp/pipermail/pgpool-general/2013-July/001905.html - 日本語ドキュメントの typo を修正しました。 (Yugo Nagata)
3.0.12 (umiyameboshi) 2013/07/10
概要
このバージョンは 3.0.11 に対するバグ修正リリースです。
バグ修正
- man ページに -D オプションの記述を追加しました。(Tatsuo Ishii)
-
オンラインリカバリ時のフェイルバックの完了待機でタイムアウト処理をするようにしました。(Tatsuo Ishii)
これによりリカバリが永遠に終わらず pgpool-II が終了できなくなる状況を回避します。 この現象は特に follow_master_command の実行中に起こり得ました。
-
PostgreSQL がエラーを返したときに do_query() がハングしないよう修正しました。
(Tatsuo Ishii)
典型的な症状が「pg_stat_activety によると SELECT が実行されたままのように見える」というものです。 これを解決するため、pgpool-II は当該プロセスを終了させ、既存のコネクションを捨てるように修正しました。
-
拡張プロトコルの際に do_query で発生しうるハングアップを修正しました。
(Tatsuo Ishii)
これは insert_lock が有効で、pgpool_catalog.insert_lock が存在することに起こり得ます。 詳しくは [pgpool-general: 1684] を参照してください。
[pgpool-general: 1684] insert_lock hangs
http://www.sraoss.jp/pipermail/pgpool-general/2013-May/001711.html -
COMMIT 時エラーに不要なバックエンド切り離しを行わないようにしました。
(Tatsuo Ishii)
マスタースレーブモードで、COMMIT 時にマスターノードでエラーが発生していたとしても、他のスレーブノードが正常な場合にはバックエンドを切り離す必要はありません。 これは、遅延トリガーのために "kind mismatch error" が発生しうるからです。
-
pgpool_regclass を pg_catalog スキーマに登録するよう修正しました。
(Tatsuo Ishii)
これは postgres_fdw のような、スキーマ検索パスが pg_catalog に限定されているクライアントに対応するために必要です。
- pg_md5 コマンドで起こりうるクラッシュを修正しました。(Muhammad Usama)
-
スタートアップパケットに PostgreSQL ユーザ情報が含まれていなかった場合に発生する子プロセスのセグメンテーション違反を修正しました。(Yugo Nagata)
このバグは以下を実行することにより再現できます。
$ psql -p 9999 -U ''enable_pool_hba が有効の場合は子プロセスがセグメンテーション違反で異常終了し、無効の場合には以下のメッセージがログに出力されていました。
ERROR: pool_discard_cp: cannot get connection pool for user (null) database (null)また、両方の場合で psql はフロントエンドに何のメッセージ出力せずに終了していました。 修正後は、スタートアップパケットに PostgreSQL ユーザが指定されていない場合には以下のメッセージがログとフロントエンドの両方に出力されます。 これは PostgreSQLと同じ振る舞いです。
FATAL: no PostgreSQL user name specified in startup packet - マニュアルの ssl_sa_cert, ssl_ca_cert_dir オプションの説明を SSL セクションに移動しました。(Yugo Nagata)
- ssl_sa_cert, ssl_ca_cert_dir オプションの説明を日本語マニュアルに追加しました。(Yugo Nagata)
-
pcp_recovery_node コマンドで、バックエンドノード番号をチェックするように修正しました。(Yugo Nagata)
不正な値が使用された場合、リカバリで実行されるスクリプトの引数に空の値が渡されており、誤動作の原因となっていました。 特にベースバックアップを行うスクリプトで、rsync が関係のないファイルを削除してしまうことがありました。
3.0.11 (umiyameboshi) 2013/04/26
概要
このバージョンでは、3.0.10における様々なバグが修正されています。
バグ修正
- 設定パラメータの一覧を表示する "SHOW pool_status" で pool_passwdが表示されていないのを修正しました。(Yugo Nagata)
-
拡張プロトコルの処理における timestamp の書き換えに関する長い間見過ごされていてたバグを修正しました。(Tatsuo Ishii)
Parse() 関数は、parse メッセージの書き換えの際に palloc() を使ってメモリを確保していました。 書き換えられたメッセージは pool_create_sent_message() 関数などが管理するデータ領域に格納されますが、これが問題となっていました。 この関数ではデータが session context memory 中に存在することを想定しているのに対し、 palloc() では query context においてメモリの割り当てを行っており、この領域は query context 終了時に解放されます。しかし、他の関数もこのメモリ領域を解放しようとするため、 セグメンテーション違反や二重解放を含む様々な問題の原因となっていました。 この問題は、書き換えたメッセージを格納するメモリを session context を用いて確保するこで修正されました。 これは pgpool-II 3.0 以来ずっと存在していたバグです。
この問題は、Naoya Anzai さんによって解析され、パッチが提供されました。
[pgpoolgenera-jp: 1146]
拡張問い合わせプロトコルでセグメンテーションフォルト
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001145.html -
md5認証で長いユーザ名を処理する際のバグを修正しました。(Tatsuo Ishii)
ユーザ名が 32 バイトより長い場合、md5 認証が動作していませんでした。 この問題は [pgpool-general: 1526] で Thomas Martin さんにより報告されました。
[pgpool-general: 1526]
[pgPool-II 3.2.3] MD5 authentication and username longer than 32 characters.
http://www.pgpool.net/pipermail/pgpool-general/2013-March/001551.html - レプリケーション遅延の計算はスタンバイサーバがプライマリサーバより遅れている場合にのみ行うよう修正しました。(Yugo Nagata)
タイミングによってスタンバイよりプライマリの方がレプリケーションが遅延 しているように見える場合があり、その場合には負値の遅延が計算されていました。 この値が符号無し変数に代入されると、実際には遅延が生じていないにも関わらず、 ログに遅延が負値で出力され、されに悪いことには、ロードバランス機能により SELECT クエリがプライマリに振り分けられ、その結果プライマリの負荷が高まる ことがありました。
この問題は Saitoh Hidenori さんによって報告、解析されました。
[pgpool-genera-jp: 1145]
レプリケーション遅延確認の不具合について
http://www.pgpool.net/pipermail/pgpool-general-jp/2013-March/001144.html - pgpool-recovery が PostgreSQL 9.3 に対応しました。 (Tatsuo Ishii)
パッチは Asif Rehman さんにより提供され、これに Tatsuo Ishii が若干の修正を 加えました。
[pgpool-hackers: 180]
compile error in ppool-recovery
http://www.pgpool.net/pipermail/pgpool-hackers/2013-April/000179.html - pool_has_pgpool_regclass が pgpool_regclass() の実行権限をチェックするよう修正しました。 (Tatsuo Ishii)
pgpool_regclass が存在する場合でも、pgpool がこの関数を実行できない場合に、 バックエンドへの接続がハングしていました。この問題は、pgpool_regclass から実行権限を剥奪し、ネイティブレプリケーションモードで INSERT を実行 することで再現可能です。
この問題は bugtrack #53 で報告されました。
#53 pgpool_regclas hangs all connections
Date: 2013-04-04 13:35
Reporter: tmandke
http://www.pgpool.net/mantisbt/view.php?id=53 - detect_postmaster_down_error() のエラーメッセージを修正しました。(Tatsuo Ishii)
例えば、"LOG: detect_stop_postmaster_error: detect_error error" を "LOG: detect_postmaster_down_error: detect_error error" に修正するなどです。
3.0.10 (umiyameboshi) 2013/02/08
概要
このバージョンでは、3.0.9における様々なバグが修正されています。
バグ修正
- md5 認証で競合が発生する不具合が修正されました。(Tatsuo Ishii)
pool_passwd のファイル識別子は pgpool の親プロセスで開かれたものが子プロセス に引き継がれてます。複数の接続で同時に md5 認証を行う際には、pool_get_passwd が 呼ばれ、ファイル識別子が走査されますが、ファイル識別子が共有されるために md5 認証 が失敗することがありました。この問題は、個々の子プロセスで pool_passwd ファイルを 開き直すことで解決されました。
この問題は [pgpool-general:1141] にて、Jason Slagle さんによって報告・解析されました。
[pgpool-general: 1141] Possible race condition in pool_get_passwd
From: Jason Slagle
Date: Sun, 28 Oct 2012 01:12:52 -0400
http://www.sraoss.jp/pipermail/pgpool-general/2012-October/001160.html - pool_send_severity_message() で未初期化のメモリを使用しないよう修正しました。
(Tatsuo Ishii)
このバグによりセグメンテーション違反が発生することがありました。 バグトラック #33 に投稿された valgrind 実行結果(dudee さんによる)にて報告されました。
#33 pgpool-II 3.2.1 segfault
Reporter: dudee Date: 2012-10-30 19:16 http://www.pgpool.net/mantisbt/view.php?id=33 - 通常のテーブルと同名の一時テーブルがあるときに、クエリキャッシュの結果が不正になる
バグを修正しました。 (Tatsuo Ishii)
以下はバグを引き起こす処理の例です。
1) CREATE TABLE t1(i int); -- 通常のテーブルを作成 2) INSERT INTO t1 VALUES(1); 3) SELECT * FROM t1; -- クエリキャッシュが作成される 4) CREATE TEMP TABLE t1(i int); -- 一時テーブルの作成 5) SELECT * FROM t1; -- 誤ったクエリキャッシュが作成される!
#3 で t1 のキャッシュが生成されますが、#5 でこれが不正に使われており、一時テーブル t1 が 一時テーブルと見なされていないのが問題でした。
- pcp または worker 子プロセスの終了イベントを受信したときに、reaper() で wait3()
ループを終了しないように修正しました。 (Tatsuo Ishii)
修正前は、reaper() は子プロセスの終了イベントを誤って無視してしまい、ゾンビプロセスを作り、 新しいプロセスを生成できないことがありました。
この問題は[pgpool-general-jp: 1123]にて、後藤さんより報告され、修正の示唆を頂きました。
[pgpool-general-jp: 1123] Re: オンラインリカバリ後にゾンビプロセスになる
From: GOTO, Daisuke Date: Wed, 21 Nov 2012 19:56:17 +0900 http://www.sraoss.jp/pipermail/pgpool-general-jp/2012-November/001122.html - pool_search_relcache() が REAL_MASTER_NODE_ID ではなく MASTER, MASTER_NODE_ID
を使用するように修正しました。 (Tatsuo Ishii)
ストリーミングレプリケーションモードで 0 番ノードがフェイルバックした場合、pgpool は 子プロセスを再起動しません。そのとき、REAL_MASTER_NODE_ID は 0 番ノードの接続 情報を探しにいきますが、これはバックエンドへの新しい接続が確立するまで存在しません。 そのため、接続情報の参照によって、セグメンテーションフォルトが発生していました。 この状況でも、MASTER または MASTER_NODE_ID は以前にキャッシュされたマスター ノード ID を見にいくため、安全に使うことが出来ます。
- ストリーミングレプリケーションモードでレプリケーション遅延が大きくなったときに、
"portal not found" エラーが発生するバグを修正しました。 (Tatsuo Ishii)
これは delay_threshold が導入以来、ずっと存在していたバグです。
bind, describe, execute の実行時に遅延が域値を越えた場合、送り先の DB ノードは 変更されていました。しかし、parse がそれとは異なるノードに送られていた場合、送り先ノードには parse された ステートメントやポータルが存在しないために bind, describe, execute は 失敗していました。 修正後は、大きな遅延が発生した場合でも、これらは parse が実行された ノード以外には送られないようになりました。
- pg_md5 で、ユーザからのパスワード入力の後には改行するように修正しました。 (Yugo Nagata)
- watchdog のポート番号が既に使用されていた場合にエラーメッセージを出力するよう修正しました。
(Yugo Nagata)
この問題は [pgpool-general: 1167] で Will Ferguson さんによって報告されました。
[pgpool-general: 1167] Re: Watchdog error - wd_init: delegate_IP already exists
From: Will Ferguson Date: Tue, 6 Nov 2012 13:03:36 +0000 http://www.sraoss.jp/pipermail/pgpool-general/2012-November/001186.html - コネクションプールが存在しない場合には、child_exit() が send_frontend_exits()
を呼ばないよう修正しました。 (Tatsuo Ishii)
send_frontend_exits() は pool_connection_pool で指されてるオブジェクトを参照しているため、 修正前にはセグメンテーションフォルトが発生していました。バグトラック #44 の tuomas さんの報告によります。
#44 pgpool went haywire after slave shutdown triggering master failover
Reporter: tuomas Date: 2012-12-11 00:33 http://www.pgpool.net/mantisbt/view.php?id=44 - pool_read() が不正なパケットを読み込んだ場合に、read_startup_packet() がアラームクロック
をリセットして StartupPacket を解放するよう修正しました。 (Nozomi Anzai)
修正前は、pgpool ポートの監視を行うプログラムの接続により、認証のタイムアウトが発生していました。 この問題は、バグトラック #35 で報告されました。
#35 Authentication is timeout
Reporter: tuomas Date: 2012-11-20 11:54 http://www.pgpool.net/mantisbt/view.php?id=35 - pool_open() が誤ったバッファポインタを初期化していたバグを修正しました。 (Tatsuo Ishii)
このポインタは事前に memset() によって初期化されているため、実際にはこのバグによる害は ありませんでした。
- ヘルプメッセージに -f オプションの説明を追加しました。 (Tatsuo Ishii)
- ドキュメント中の、「パラメータ変更に再起動が必要かどうか」の情報を追記・修正しました。(Yugo Nagata)
- pool_passwd に関する記述を pgpool_conf.sample*、および,ドキュメントに追加しました。 (Yugo Nagata)
3.0.9 (umiyameboshi) 2012/10/12
概要
このバージョンでは、3.0.8における様々なバグが修正されています。
バグ修正
- read_startup_packet() を修正しました。(Tatsuo Ishii)
パケット長が 0 以下のときは直ちに return するべきでしたが、そうなっていなく、 メモリ確保時にエラーになっていました。
これは pgpool-general:886 を参照してください。また、キャンセルアラームを追加しました。
[pgpool-general: 886] read_startup_packet: out of memory
From: Lonni J Friedman
Date: Wed, 8 Aug 2012 10:18:15 -0700
http://www.sraoss.jp/pipermail/pgpool-general/2012-August/000896.html - s_do_auth() に NOTICE メッセージを追加しました。(Tatsuo Ishii)
これがなかったために、ヘルスチェックが false アラームを受け取りフェイルオーバしていました。
これはバグトラックで報告されました。
#25 s_do_auth doesn't handle NoticeResponse (N) message
Date: 2012-08-28 03:57
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=25 - s_do_auth() から、不要かつ混乱をまねくデバッグメッセージを削除しました。(Tatsuo Ishii)
- SSL モードでの無限ループを修正しました。 (Tatsuo Ishii)
フロントエンドの SSL レイヤで溜っているデータがあるとき、 pool_process_query() がバックエンドに溜っているデータをチェックします。 もしそれが無かったときは再度ループして、フロントエンド/バックエンドがバッファを受け取っていないか is_cache_empty() を以ってチェックします。 しかし、フロントエンドの SSL レイヤでデータが溜っているのを一度検知すると、 バックエンドに行ってまたチェックしようとします(無限ループ)。
これを解決するには、フロントエンドの SSL レイヤに溜っているデータがあり かつ クエリが実行中でなければ、ProcessFrontendResponse() を呼んで フロントエンドへの新しいリクエストをするようにしました。
- is_system_catalog() で、可能ならば pgpool_regclass を使うようにしました。(Tatsuo Ishii)
- pool_get_insert_table_name() のメモリリークを修正しました。(Tatsuo Ishii)
nodeToString() でセッションコンテクストのメモリコンテクストを使ったあと、 セッション終了までは、メモリを開放していませんでした。
詳しくはバグトラックをご覧ください。
#24 Severe memory leak in an OLTP environment
Date: 2012-08-28 03:43
Reporter: singh.gurjeet
http://www.pgpool.net/mantisbt/view.php?id=24 - do_query() のセグメンテーションフォルトを修正しました。(Tatsuo Ishii)
クエリキャッシュが有効で拡張問い合わせが使われているとき、do_query() はシステムカタログに接続し、 pool_read2() を使います。 しかし、parse メッセージパケットを Parse() で取得し、パケットの内容が pool_read2() のバッファにあります。 このため、do_query() はパケットの内容を分割できず、セグメンテーションフォルトを引き起こしていました。
これを解決するために、メモリを確保し、パケット内容をコピーし、Parse() を飛ばすようにしました。 ただし、パケットの中にはクエリコンテクストが参照しているクエリ文字列も含まれています。 そのため、このクエリ文字列をコピーしてポインタをクエリコンテクストに保持する必要があります。
これは、Parse() だけの話でなく、他のプロトコルモジュールにもある問題と考えています。 本修正はそれらにも適用しますが、そのためには、ProcessFrontendResponse() を変更します。
この問題はバグトラック #21 で報告されました。
#21 pgpool-II 3.2.0 cannot execute sql through jdbc
Date: 2012-08-17 16:31
Reporter: elisechiang
http://www.pgpool.net/mantisbt/view.php?id=21
3.0.8 (umiyameboshi) 2012/08/06
- Solaris でのロードバランスを修正しました。(Tatsuo Ishii)
Solaris での random() 関数の仕様のために問題があったため、rand() に変更しました。
この事象は [pgpool-general: 396] で報告されました。
[pgpool-general: 396] strange load balancing issue in Solaris
From: Aravinth
Date: Sat, 28 Apr 2012 07:26:58 +0530 - パラレルモードでないとき、pcp_systemdb_info コマンドが segfault してたのを修正しました。(Nozomi Anzai)
- "unnamed prepared statment does not exist" というエラーが出るのを修正しました。(Tatsuo Ishii)
このエラーは pgpool が内部的に発行しているクエリで発生し、 クライアントが発行する unnamed ステートメントを破壊していました。
拡張問い合わせクエリが実行されたときには、内部的に発行するクエリのステートメントとポータルに 名前をつけるようにしました。
- pid ファイルの読み書きを改善しました。(Tatsuo Ishii)
- [pgpool-general: 672]
で報告された、process_query() のバグを修正しました。(Tatsuo Ishii)
プライマリでは処理するデータがなく スタンバイにはある状態のときに、 プライマリの処理を待ってしまうことがありました。
Subject: [pgpool-general: 672] Transaction never finishes
From: Luiz Pasqual
Date: Thu, 28 Jun 2012 09:55:23 -0300 - wait_for_query_response() が、frontend がないときには何もしないように修正しました。(Tatsuo Ishii)
バックエンドをリセットする reset_query_list のクエリを実行に時間がかかったときに 発生する可能性があり、またクラッシュすることがありました。
3.0.7 (umiyameboshi) 2012/04/23
概要
このバージョンでは、3.0.6におけるバグが修正されています。
バグ修正
- m4 ファイルを追加しました。これにより古い OS で起こるコンパイルの問題を回避できます。(Tatsuo Ishii)
- シグナル割り込みによって、セマフォが解放されないままプロセスが終了することがあるバグを修正しました。(Tatsuo Ishii)
- reset_query 時のメモリリークを修正しました。 (Tatsuo Ishii)
- 以下の場合に parser memory をリストアするよう SimpleQuery() 関数を修正しました。
- 組み込み show コマンド使用時
- パラレルクエリモード
- クエリキャッシュ使用時
- pool_ssl_read() 関数が大きいサイズのデータを読み込めるよう修正しました。以下の報告によるものです。(Tatsuo Ishii)
http://www.pgpool.net/pipermail/pgpool-general/2012-March/000299.html - PREPARE 文でエラーが起きた際に発生するハングアップを修正しました。Tominari Katsumata さんの報告に基づきます。(Toshihiro Kitagagwa)
3.0.6 (umiyameboshi) 2012/01/31
概要
このバージョンでは、3.0.5におけるバグが修正されています。
バグ修正
- 以下のスレッドで報告されている無限ループを修正しました。(Tatsuo Ishii)
http://www.pgpool.net/pipermail/pgpool-genral/2011-December/000099.html
プライマリからから受け取ったバッファが空である一方で、スタンバイのどれかが 受け取ったバッファが空でないとき、pgpool へのパケットが送られてしまう、 という可能性が考慮されていませんでした。
この事象は例えば、postgresql.conf を再読み込みしたときに発生することがありました。
この修正では、スタンバイからしか受け取れなかったバッファは無視するようにしました。
3.0.5 (umiyameboshi) 2011/10/31
概要
このバージョンでは、3.0.4における様々なバグが修正されています。
バグ修正
- 空のクエリの処理に関するバグを修正しました。空のクエリはSELECTクエリと同じ扱いになります。 この修正は、空のクエリのあとのロードバランスを可能にします(Kitagawa)
- カラム定義が"DEFAULT nextval(('"x_seq"'::text)::regclass)"のようになっていても insert_lockが正しく動作するように修正しました(Kitagawa)
- pgpool-IIマニュアルのbackend_weightに関する説明を修正しました。 それは、pgpool.confの再読み込みで変更できます(Tatsuo)
- rawモードでノードを復帰させたときにノードの状態が更新されないバグを修正しました(Guillaume Lelarge)
- FOR SHARE/UPDATE句のあるサブクエリを含むSELECTがスレーブ(standby)に送られるバグを修正しました(Tatsuo)
- PREPARE文でデフォルト値のタイムスタンプ書き換えに失敗するバグを修正しました。 これは以前は動作していましたが、3.0で動作しなくなっていました(Kitagawa)
- rawモード、enable_hbaが無効、バックエンドが2台以上の場合に pgpool子プロセスがクラッシュするのを修正しました(Kitagawa)
- メモリリークをいくつか修正しました(Kitagawa)
改良
- カラムのデフォルト値に任意の式を指定してもタイムスタンプ書き換えが動作するようにしました。 以前は、now()が含まれているものを検知すると、単純にそれをnow()で置き換えてました。 これは、デフォルト値の誤った書き換えを引き起こします。例えば、timezone('utc'::text, now())です。 しかし、これは簡易プロトコルのみへの適用であることに注意してください。 拡張プロトコル(例えばJava, PHP PDO)または、SQLの"PREPARE"にはまだ適用されていません(Tatsuo)
- エラーメッセージ"do_md5: read_password_packet failed"をデバッグレベルにしました(Kitagawa)
3.0.4 (umiyameboshi) 2011/06/01
概要
このバージョンでは、3.0.3における様々なバグが修正されています。
互換性のない変更
- ストリーミングレプリケーションにおいて、delay_threshold が 0またはヘルスチェックが無効ならば、遅延チェックは実施されません。 これはpgpool-IIマニュアルとおりの動作ですが、これまではヘルスチェックが無効の場合も 遅延チェックが実施されていました(Guillaume Lelarge)
バグ修正
- pgpool-regclass()をPostgreSQL 8.0以降でコンパイルできるように修正しました。7.4はまだエラーが出ます(Tatsuo Ishii)
- ストリーミングレプリケーション構成で/*NO LOAD BALANCE*/コメントを使用したときに ハングアップする可能性を修正しました(Toshihiro Kitagawa)
- Flush(H)メッセージやCloseComplete(C)メッセージを受信したときのハングアップを修正しました(Toshihiro Kitagawa)
- pgpool-IIがバックエンドに接続後、RedyForQuery(Z)メッセージを受信するタイミングによって起こり得る ハングアップを修正しました(Toshihiro Kitagawa)
- recovery_1st_stage_command と recovery_2nd_stage_command パラメータの説明を追加しました(Tatsuo Ishii)
- pgpool-II内部で使用するシステムカタログキャッシュのサイズを32から128に増やしました。 これは"unnamed prepared statement does not exist"エラーを軽減する効果があります。(Tatsuo Ishii, Toshihiro Kitagawa)
- pcp_connect()関数で二重free()を行うバグを修正しました。 パッチはJehan-Guillaume (ioguix) de Rorthaisさんから頂きました(Tatsuo Ishii)
- PQfinish()関数を誤って使用しているstart_recoery()のバグを修正しました(Tatsuo Ishii)
- クライアントのアイドル時間が client_idle_limit に達したときに、 フロントエンドに送信される正しくないエラーメッセージを修正しました(Tatsuo Ishii)
- pool_statusの「backend status」変数の名前を正しく修正しました。 スペースを'_'に置き換えました(Guillaume Lelarge)
- md5認証方式を採用してデーモンとして実行したときのハングアップを修正しました。 パッチは、Nicolas Thauvinさんから頂きました(Tatsuo Ishii)
- 拡張問い合わせプロトコルでSQL文が出力されるように、 log_per_node_statementを修正しました。 これは以前は動作していましたが、3.0で動作しなくなっていました(Toshihiro Kitagawa)
改良
- サンプルの設定ファイルの black_function_list に currval()とlastval()を追加しました。 もしそれらがロードバランスされると、nextval()やsetval()の結果がスレーブに反映される前に currval()またはlastval()が呼ばれることがあります(Tatsuo Ishii)
3.0.3 (umiyameboshi) 2011/02/23
概要
このバージョンでは、3.0.1における様々なバグが修正されています (pgpool-II 3.0.2のリリースはパッケージングの問題でキャンセルされました)。
互換性のない変更
- ストリーミングレプリケーションモードを使用する場合に、PostgreSQLサーバに C関数「pgpool_walrecrunning()」をインストールすることが推奨されます(後述)。 この場合、新しい変数「%P」がオンラインリカバリのスクリプトで利用できるようになります。 この関数をインストールしない場合は、従来と同じ動作になります(Tatsuo Ishii)
- rawモードでDBノードがひとつだけの場合、DBノードに問題が発生するとダウン状態になりますが、 DBノードが復旧したらpgpoolの再起動なしにDBノードを使用できるようにしました。 この変更は3.0に含まれていましたが、動作していませんでした(Tatsuo Ishii, Toshihiro Kitagawa)
バグ修正
- パスワード認証における移植性を損なうコードを修正しました。 これはFreeBSDユーザからのバグ報告に基づきます(Tatsuo Ishii)
- insert_lock がユーザテーブルの全行をロックするバグを 修正しました(Tatsuo Ishii, Toshihiro Kitagawa)
- ユーザ名の長さが32バイトのときにpgpool子プロセスがクラッシュする パスワード認証のバグを修正しました(Tatsuo Ishii)
- rawモードまたはバックエンドノード数が1のときに、pgpool子プロセスがクラッシュする md5認証のバグを修正しました。パッチはRob Shepherdさんから頂きました(Tatsuo Ishii)
- 以前からあった配列と複合型に対するタイムスタンプ書き換えのバグを修正しました。 パッチはAkio Ishidaさんから頂きました(Tatsuo Ishii)
- debug_level パラメータが動作しないバグを修正しました。 パッチはGilles Daroldさんから頂きました(Tatsuo Ishii)
- フェイルオーバー中に起こりうるpgpool子プロセスのクラッシュを修正しました(Toshihiro Kitagawa)
- ユーザがスキーマ名の付いた関数を呼んだときに white/black_function_list が 正しく動作するように修正しました(Tatsuo Ishii)
- コネクションキャッシュによってDROP DATABASEが失敗するバグを修正しました(Toshihiro Kitagawa)
- rawモードでフェイルオーバが失敗するバグを修正しました(Toshihiro Kitagawa)
- 1セッションで簡易問い合わせプロトコルと拡張問い合わせプロトコルの両方が使われたときに起こりうる pgpool子プロセスの終了を修正しました(Toshihiro Kitagawa)
- 拡張問い合わせプロトコルを使用中にエラーが発生すると起こりうるハングアップを修正しました(Toshihiro Kitagawa)
- PG_TRY/CATCHを使用しないようにpgpool-regclass()を修正しました。(Tatsuo Ishii)
PG_TRY/CATCHは、時々バックエンドが「PANIC: ERRORDATA_STACK_SIZE exceeded.」というメッセージとともに 終了するので安全でないように見えます。
- JDBCドライバがマスタノードに何度もBEGINを発行するロードバランスのバグを修正しました(Toshihiro Kitagawa)
- failback_command と fail_over_on_backend_error が 正しい値を表示するように pool_status を修正しました(Toshihiro Kitagawa)
- pool_status から recovery_password と system_db_password を削除しました(Toshihiro Kitagawa)
- ストリーミングレプリケーションモードでフェイルオーバを実行中に、 バックエンドのログに「unexpected EOF on client connection」が出ないように修正しました(Tatsuo Ishii)
- バックエンドがすべてダウンした場合に発生するpgpoolのクラッシュを修正しました(Tatsuo Ishii)
- レプリケーション遅延チェックがバックエンドとの永続的な接続を行わないように修正しました。(Tatsuo Ishii)
これは、レプリケーション遅延チェックの間でDBノードのダウンとアップが起きた場合に永続的な接続が 不正になる可能性があるためです。
- 英語ドキュメントを書き直してレビューしました(Marc Cousin, Gleu)
- 以下の条件を満たすとき SELECT クエリがマスタノードに送信されないバグを修正しました(Toshihiro Kitagawa)
- マスタースレーブモードである
- 拡張問い合わせプロトコルを使用している
- 明示的にトランザクションを開始している
- 更新クエリを実行した後である
- ストリーミングレプリケーションモード利用時のオンラインリカバリにおいて、
以下のシナリオがうまく動作しない問題を修正しました。
以下のシナリオでは、ノード0を最初のプライマリサーバ、ノード1を最初のスタンバイサーバとします。
- ノード0プライマリサーバがダウンし、ノード1スタンバイサーバが新しいプライマリサーバになる
- ノード0の旧プライマリサーバは、オンラインリカバリで新スタンバイサーバになる
- このときpgpool-IIは、ノード0の新スタンバイサーバを、プライマリサーバとみなしてしまう
改良
- ステータスファイルを読んでいるときに、特定のバックエンドがダウン状態ならば ログを出力するようにしました(Tatsuo Ishii)
- pgpoolが実行したクエリでエラーが発生した場合に、エラーメッセージを出力するようにしました(Tatsuo Ishii)
- sqlディレクトリに主要なMakefileを追加しました(Tatsuo Ishii)
3.0.2(umiyameboshi) 2011/02/17
概要
このバージョンは問題があったために、リリースが取り消されました。
3.0.1 (umiyameboshi) 2010/10/19
概要
このバージョンでは、3.0における様々なバグが修正されています。
バグ修正
- 認証されるサーバが複数ある場合にクラッシュするmd5認証のバグを修正しました(Tatsuo Ishii)
- 拡張問い合わせプロトコルにおいて、構文エラーのクエリを実行したときに 子プロセスがクラッシュするバグを修正しました(Toshihiro Kitagawa)
- ポータル情報のハンドリングにおける子プロセスが終了するバグを修正しました(Toshihiro Kitagawa)
- 拡張問い合わせプロトコルにおいて、ひとつのノードに送信されたクエリがエラーを起こしたときに ハングアップするバグを修正しました(Toshihiro Kitagawa)
- 英語ドキュメントの誤植を修正しました。Asaf Ohaionさんのパッチを取り込みました(Tatsuo Ishii)
3.0 (umiyameboshi) 2010/09/10
概要
このバージョンは3.0系列の最初の版で、2.2系や2.3系からの「メジャーバージョンアップ」にあたります。 PostgreSQL 9.0の新機能であるStreaming Replication/Hot Standby構成に対応するなど、 多くの機能が追加されると共に、内部構造が整理されて見通しが良くなって保守性が向上しています。
マスタースレーブモード全般で多くの改善がなされています。
- 明示的なトランザクション内のSELECTが負荷分散できるようになりました
- 不必要なDBノードにparse/bindメッセージが送られなくなりロック競合が減りました
- 不必要な内部トランザクションの起動がなくなり、オーバヘッドが軽減しています
- 一時テーブルを意識せずに安全に使えるようになりました
- 書き込みを伴う関数呼び出しを行なうSELECTをマスター(primay)でのみ実行するように制御できるようになりました
レプリケーションモードにおいても、書き込みを伴う関数呼び出しを行なうSELECTを負荷分散するかどうかの制御できるようになるなどの改良が加えられています。
新機能
- PostgreSQL 9.0の新機能であるStreaming Replication/Hot Standby(SR+HS)構成に対応しました(Tatsuo Ishii, Toshihiro Kitagawa)。
pgpool-IIは基本的にはmaster/slave modeとして動作しますが、その際に "master_slave_sub_mode" という 新しい設定項目に"stream"を設定することにより、SR+HS構成に最適な動作をします。 たとえば、更新クエリはPrimaryサーバにのみ送信し、SELECTはPrimaryとStandbyサーバに負荷分散することが可能です。
そのほか、Standbyサーバをオンラインリカバリで復旧したり、PrimaryとStandbyのレプリケーション同期を監視し、 遅れが大きいようならPrimaryにのみSELECTを送信させるようにすることも可能です。
詳細はStreaming Replicationへの対応"をご覧下さい。
- オンラインリカバリがStreaming Replication対応で動作しているmaster/slaveモードに対応しました(Tatsuo Ishii)
- Streaming Replicationモード用の新しい設定項目 "delay_threshold" が追加され、 レプリケーションの遅れが監視できるようになりました。 遅延が多い場合には、負荷分散しないようにすることができます(Tatsuo Ishii)
- show pool_status で、Streaming Replicationにおける レプリケーションの遅延が確認できるようになりました(Tatsuo Ishii)
- Streaming Replicationにおけるレプリケーションの遅延のログを制御する新しい設定項目 "log_standby_delay" が追加されました(Tatsuo Ishii)
- insert_lock が有効で、テーブルにシリアル型が含まれている場合、
テーブルロックではなく、該当シーケンスを行ロックするようにしました。(Tatsuo Ishii)
以前はテーブルロックをしていましたが、auto vacuumとロックが衝突したりして 性能が低下する問題がありました。
- 新しい"SHOW"コマンドが追加されました。すなわち、pool_nodes, pool_processes, pool_pools, pool_version です(Guillaume Lelarge)
- pcp_proc_info コマンドの出力結果に、 PostgreSQLバックエンドプロセスのプロセスIDとフロントエンドからの接続があるかどうかが追加されました(Tatsuo Ishii)
- 関数呼び出しを伴うSELECTを制御する設定項目 white_function_list と back_function_list が追加されました(Tatsuo Ishii)
- マスタースレーブモードにおいて、システムカタログを検索するSELECTは、整合性を保つために 常にマスター(primary)で実行されるようになりました(Tatsuo Ishii)
- マスタースレーブモードにおいて、一時テーブルを検索するSELECTは、整合性を保つために 常にマスター(primary)で実行されるようになりました(Tatsuo Ishii)
- マスタスレーブモードで、明示的なトランザクション内で実行されない更新クエリにおいて、
自動的にトランザクションを開始することを止めました。(Tatsuo Ishii)
これは不必要でした。これによって、パフォーマンスが向上しています。
- マスタスレーブモードで、明示的なトランザクション内で実行されるSELECTコマンドが 負荷分散できるようになりました(Tatsuo Ishii, Toshihiro Kitagawa)
- マスタスレーブモードで、必要なDBノードにのみコマンドが送られるようになりました。
(Tatsuo Ishii, Toshihiro Kitagawa)
これにより、たとえばパースコマンドが不必要なDBノードにおいても ロックを取ってしまうようなことがなくなりました。
- pgpoolの起動時に、ステータスファイルを無視するオプションが追加されました(Tatsuo Ishii)
- PostgreSQL 9.0のVACUUMの新しい書式をpgpool-IIのパーサがサポートしました(Tatsuo Ishii)
- フェイルオーバ/フェイルバックコマンドで、"%H"という特殊変数が利用できるようになりました。 これは、新しいマスターノードのホスト名を表します(Tatsuo Ishii)
- failover_if_affected_tuples_mismatch という設
定項目が追加されました(Tatsuo Ishii)
従来、レプリケーションモードでINSERT/UPDATE/DELETEの結果行数が異なると、 トランザクションをアボートしてセッションを強制切断していました。 failover_if_affected_tuples_mismatch を trueに設定すると、この現象が起きたときに、 不一致のあったDBノードを切り放して縮退運転に入るようになります。
- レプリケーションモードでDBノード間でINSERT/UPDATE/DELETEの結果行数の不一致が検出された際に、 DBノードにおける結果行数がログに記録されるようになりました(Tatsuo Ishii)
- レプリケーションモードとマスタスレーブモードで、md5認証がサポートされました(Tatsuo Ishii)
- オンラインリカバリで、強制的にフロントエンドへの接続を切断して
直ちにセカンドステージに入ることができるようになりました。(Tatsuo Ishii)
そのためには、client_idle_limit_in_recovery に -1 を設定します。
- RAWモードにおいて、DBノードが1個だけしか存在しない状態でDBがエラーを起したために DBノードを切り放したあとでDBノードが回復した場合に、pgpool-IIを再起動することになしに DBノードを利用できるようになりました(Tatsuo Ishii)
- pcpコマンドにおいて、ロングオプションがサポートされました(Guillaume Lelarge)
- debug_level という設定項目が追加され、 pgpool.confの再読み込みによってデバッグメッセージの出力をオン/オフできるようになりました(Tatsuo Ishii)
- pgpool.confで、postgresql.confと同じ真偽値表現が利用できるようになりました。 従来は、true/false, 1/0しか使えませんでした(Toshihiro Kitagawa)
- オンラインリカバリのセカンドステージをより安全に実行するために、 C言語関数 pgpool_switch_xlog を追加しました(Toshihiro Kitagawa)
- 異なるスキーマに同じ名前のテーブルが存在する場合に起きる不具合を回避するために、 C言語関数pgpool_regclassを追加しました(Tatsuo Ishii)
互換性のない変更
- replicate_select と load_balance_mode を
共にtrueに設定した場合、トランザクションブロックの外側で実行されるSELECT文は、
replicate_selectに従うようになりました。
以前は、load_balance_modeに従うようになっていました。
もしクライアントがこの動作を利用している場合は、replicate_selectをfalseにして back_function_list を設定することで同じ動作を実現できます。
バグ修正
- 型が時刻データ以外の列の場合、デフォルト値にnow()が含まれていても書き換えを行なわないようにしました。(Tatsuo Ishii)
今までは無条件に書き換えを行なっていたため、書き換えの結果、INSERT文などがエラーになっていました。
- タイムスタンプの書き換え処理対象となるテーブルのスキーマが無視されないようにしました。(Tatsuo Ishii)
ただし、この機能を有効にするためには、付属のユーザ定義関数"pgpool_regclass"のインストールが必要です。 この関数がインストールされていない場合は、依然としてスキーマが無視されてしまいます。
- pcpコマンドのタイムアウトの扱いにおけるバグが修正されました(Tatsuo Ishii)
- SSLが有効な状態で、大量のデータ通信が起るとハングする問題が修正されました(Tatsuo Ishii)
- DBノードが1個だけしか存在しない状態でDBがエラーを起したた際に、 間違ったDBノードがフェイルオーバするバグを修正しました(Tatsuo Ishii)
- オンラインリカバリ時のpostmasterの起動チェックにおけるバグを修正しました。(Tatsuo Ishii)
今まではpostmasterへの最初の接続が失敗すると、接続を無限に繰り返すようになっていました
2.3.3 (tomiteboshi) 2010/04/23
概要
このバージョンでは、2.3.2.2 以前の色々なバグが修正されています。
互換性のない変更
- このバージョンから、pgpool が以前より多くの共有メモリを使うようになったので注意してください。
これによる問題が pgpool の起動時に発生した場合は、pgpool のログを見てください。 "could not create shared memory segment: Cannot allocate memory" といったメッセージがあれば、 システムの共有メモリを増やしてください。
- パラレルモードが、レプリケーションモードかロードバランスモードが有効でないと
使えないようになりました。(Toshihiro Kitagawa)
pgpool-II ではずっと、レプリケーションモードかロードバランスモードが有効でないとき パラレルモードは正しく動作していませんでした。
- insert_lock のデフォルト値を false に変更しました。(Tatsuo Ishii)
これは、マスタ・スレーブモードでは true にしても無意味なためです。 Fujii Masao さんの指摘により修正しました。
新しく追加したドキュメント
- README.online-recovery を追加しました。このドキュメントには、オンラインリカバリの内部的なことが書いてあります。
バグ修正
- 子プロセスが segfault を起こす pgpool-II 1.0 から長い間存在したバグを修正しました。 これは、親プロセスが shmem サイズの計算を間違えていたことに起因します。 バグ解析(Toshihiro Kitagawa)、パッチ作成(Tatsuo Ishii)
- ドキュメントにパラレルモード用の以下の制約を追記しました。(Toshihiro Kitagawa)
- - NATURAL JOIN は使えません。
- - USING 句が、クエリ書き換え処理によって ON 句に変換されます。
- パラレルモードのとき、USING 句を含む JOIN 構文の書き換えで発生する可能性があった
クラッシュを修正しました。(Toshihiro Kitagawa)
この修正により、以下のような JOIN 構文が使えるようになります。
例:SELECT * FROM a JOIN b USING (aid) JOIN c USING (cid); SELECT * FROM a JOIN b USING (aid) JOIN c USING (cid) JOIN d USING
- パラレルクエリで、分散キー列の前に current_time を含む INSERT 文のパースができるように修正しました。
- SimpleForwardToBackend() を修正しました。(Toshihiro Kitagawa)
これにより、拡張プロトコルを使ったクライアントが bind エラーのようなエラーを発生させたときに、 pgpool がバックエンドの応答を待ち続けなくなります。 このバグは、マスタ・スレーブモード、raw モード、コネクションプールモードで発生していました。
これを修正したことによって、コマンドがエラーになったあと、エラーを回復させるために SYNC メッセージを送るようになります。
- select() を実行中の pgpool 子プロセスが、SIGINT/SIGQUIT シグナルを無視するように修正しました。 シグナルが送られても pgpool は select() を再実行しようとするので、結果的にシグナルが無視されます。(Tatsuo Ishii)
- connect_inet_domain_socket_by_port/connect_unix_domain_socket_by_port が SIGTERM/SIGINT/SIGQUIT シグナルを受け取っていないかチェックするように修正しました。 Daniel Codina さんからのバグ報告に基づきます。(Tatsuo Ishii)
- "kind mismatch" というエラーメッセージを生成する際にクラッシュする可能性があったので、これを修正しました。 以前は問題なかったのですが、2.3.2でエンバグしました。(Tatsuo Ishii)
- ヘルスチェックにおけるバグを修正しました。(Tatsuo Ishii)
コードが抜けたなどでネットワーク障害が発生したときに、connect() を呼んでいる間は ヘルスチェックが行なわれていませんでした。 これは、connect() が ALARM シグナルによって割り込まれた際に、 connect_unix_domain_socket() / connect_inet_domain_socket() が再試行していたためです。 この修正では、上記の関数に対して再試行をコントロールするような引数を追加しています。
これは、Daniel Codina さんのバグ報告と分析に基づく修正です。
- 2.3.2.2 で、SimpleForwardToBackend でのタイムスタンプの書き換えにおいてエンバグしていたので、
これを修正しました。(Tatsuo Ishii)
これは、バグトラック #1010771 にある Peter Pramberge さんらの報告に基づきます。
- パラレルクエリにおける "*" の書き換えを修正しました。 sho さんから提供いただいたパッチを取り込みました。(Toshihiro Kitagawa)
- connect_inet_domain_socket_by_port() でエラーメッセージを出力する際に、 strerror() ではなく hstrerror() を使うように修正しました。 (Tatsuo Ishii)
2.3.2.2 (tomiteboshi) 2010/02/22
概要
このバージョンでは、2.3.xにおける様々なバグを修正しています。 とくにタイムスタンプの書き換え時のクラッシュを含む致命的なバグが修正されているので、 すべての2.3ユーザは早急にアップグレードすることをお勧めします。
バグ修正
- タイムスタンプデータを含む拡張プロトコル問い合わせで、 "message: invalid string in message"のエラーを出してトランザクションが終了してしまう バグを修正しました(Tatsuo Ishii)
- タイムスタンプデータを含む拡張プロトコル問い合わせで、bind時にNULLを含むパラメータが存在すると pgpoolがクラッシュするバグを修正しました(Tatsuo Ishii)
- pgpool_status上ですべてのノードがダウンのときにはこれを無効とし、 「all node down症候群」が起きないようにしました(Tatsuo Ishii)
2.3.2.1 (tomiteboshi) 2010/02/11
概要
このバージョンでは、2.3.xにおいて、エラーとなるようなSQLを実行すると pgpoolへのセッションが切断されるバグを修正しています(Akio Ishida)。
2.3.2 (tomiteboshi) 2010/02/07
概要
このバージョンでは、2.3.1の色々なバグが修正されています。 特に、タイムスタンプの書き換え機能のバグが修正されているので、2.3, 2.3.1ユーザはなるべく早く 2.3.2にアップグレードすることをお勧めします。
また、2.3.2ではSSLサポート、ラージオブジェクトのレプリケーション機能が追加されています。
改良点
- フロントエンドとpgpool-II、pgpool-IIとPostgreSQLの間のSSL通信がサポートされました(Sean Finney)
- ラージオブジェクトのレプリケーションがサポートされました(Tatsuo Ishii)
- ヘルスチェックとオンラインリカバリの際に可能であればpostgresデータベースを使うようにしました。(Tatsuo Ishii)
postgresデータベースが存在しない場合はtemplate1が使われます(以前の動作と同じ)。 これにより、DROP DATABASEなどのコマンドがオンラインリカバリ中でも使えるようになりました。
- 問い合わせのパース処理でエラーが起きたときに、SQL文をログに出力するようにしました。(Tatsuo Ishii)
エンコーディングエラーなどが発生した際にはPostgreSQLのログにもSQL文が記録されないため、これは有効です。
- kind mismatchエラーが発生し、その原因がDEALLOCATEコマンドだった場合にDEALLOCATEが削除しようとした PREPARED文の元になったSQL文をログに出力するようにしました(Tatsuo Ishii)
バグ修正
- たまにタイムスタンプを書き換えた問い合わせがマスタ以外のDBノードに 不正なパケットを送ってしまう問題を修正しました(Tatsuo Ishii)
- V2プロトコルでタイムスタンプの書き換え処理がエラーになるのを修正しました(Toshihiro Kitagawa)
- master/slaveモード、かつトランザクション内で発行されるBind、Describe、Closeメッセージは マスタだけに送るようにしました(Tatsuo Ishii)
- 2.3でsmart shutdownによりすぐに停止しなくなったバグを修正しました(Toshihiro Kitagawa)
- フロントエンドからの不正なコマンドを受け付けないようにしました(Xavier Noguer)
- 移植性を高めるために、fprintfの引数に%dzを使用するようにしました(Tatsuo Ishii)
- コンパイラワーニングを修正しました(Tatsuo Ishii)
- master/slaveモードの際に、DEALLOCATEをすべてのノードに送らないようにして、 kind mismatchエラーを防ぐようにしました(Tatsuo Ishii)
2.3.1 (tomiteboshi) 2009/12/18
概要
このバージョンでは、2.3の色々なバグが修正されています。 特に、ある条件でDBに不正な数値が書き込まれるバグが修正されており、 以下の示す条件に合致する使い方をしている2.3ユーザは至急バージョンアップすることをお勧めします。
バグ修正と改良点
- 以下のすべての条件に合致する場合、DBに不正な値が書き込まれるバグを修正しました(Tatsuo Ishii)
- レプリケーションモードで動作
- 64bit OS
- INSERTまたはUPDATEにおいて、now(), CURRENT_TIMESTAMP, CURRENT_DATE, CURRENT_TIMEを直接含むか、 テーブルのデフォルト値に含んでいる
- 更にそのSQL内に32bit(10進で-2147483648から2147483647)の範囲を超える整数定数が含まれている
INSERT INTO t1(id, regdate) VALUES(98887776655, NOW());
この例では、98887776655が32bit値にカットされて書き込まれます。 - 18以上のDBノードを使用している場合に、show pool_statusでクラッシュするバグを修正しました。 このバグはshow pool_statusが実装されてからずっと存在していたものです。
- "kind mismatch"メッセージが出た際に、kindがERRORまたはNOTICEならば、
そのメッセージを表示するようにしました。(Tatsuo Ishii)
これにより、PostgreSQLのログを見なくてもkind mismatchエラーの原因を容易に調べることが できるようになりました。
2.3 (tomiteboshi) 2009/12/07
概要
このバージョンでは、レプリケーション機能に改良が加えられ、 時刻データ(CURRENT_TIMESTAMP, CURRENT_DATE, now()など)を正しく扱うことができるようになりました。
また、同時接続数が1(num_init_childrenが1)のときのレプリケーション性能向上しています。
また、pgpool-II再起動時に前回のDBノードのダウン状態を記録し、不用意に復旧ノードにデータを書き込んで データの不整合が起きることを防ぐことができるようになりました。
そのほか、クエリログが改良されてDBノード単位の状況が把握しやすくなり、 またフェイルオーバの挙動が細かく制御できるようになりました。
なお、pgpool-II 2.3には、pgpool-II 2.2.1から2.2.6までのすべてのバグ修正、改良が含まれています。
pgpool-II 2.2.からの非互換性
- [logdir]の下にpgpool_statusというファイルが作られるので、pgpoolの実行ユーザが読み書きできる権限を 与えておいてください。
改良点
- レプリケーションにおいて、時刻データ(CURRENT_TIMESTAMP, CURRENT_DATE, now()など)を
正しく扱うことができるようになりました。(Akio Ishida)
特にアプリケーションに変更を加えることなく、INSERT/UPDATE文、テーブルのデフォルト値に これらの時刻関数を含むケースでも正しくレプリケーションできます(いくつか制限事項があります。 詳細は制限事項を参照してください)。
- SQLパーサをPostgreSQL 8.4のものにバージョンアップしました(Akio Ishida)
- 同時接続数が1(num_init_children が1)のときの レプリケーション性能が20%から100%向上しました(Tatsuo Ishii)
- 新しいディレクティブ log_per_node_statement が追加されました(Tatsuo Ishii)
log_statement と似ていますが、DBノード単位でログが出力されるので、 レプリケーションや負荷分散の確認が容易です。 また、バックエンドのプロセスIDも表示されるので、バックエンドのログと併せての解析が容易になっています。
- 新しいディレクティブ fail_over_on_backend_error が追加され、 フェイルオーバの挙動がより細かく制御できるようになりました(Tatsuo Ishii)
- pgpool-II停止時にダウンしたDBノードの情報をステータスファイルに記録し、 pgpool-IIを起動したときにその情報をリストアできるようにしました(Tatsuo Ishii) ステータスファイルは [logdir]/pgpoo_status というファイルに書かれます。
- EXPLAINと、問い合わせがSELECTのときのEXPLAIN ANALYZEが負荷分散されるようになりました。(Tatsuo Ishii)
これによって、DBノードの間で大幅に問い合わせプランが異るために、 kind mismatchエラーが起きるのを防ぐことができます。
- 日本語ドキュメントの体裁を改良しました(Tatsuo Ishii)
- レプリケーションモード、マスタースレーブモード用のデフォルトpgpoo.conf.sampleが別途追加されました(Tatsuo Ishii)
- 時刻データのテストが追加されました(Akio Ishida)
2.2.6 (urukiboshi) 2009/12/01
概要
このバージョンでは、ロードバランスの重みパラメータweightの扱いが改善され、 また一時テーブルがマスター/スレーブモードで利用できるようになりました。 もちろんいつものように2.2.5以前の色々なバグが修正されています。
バグ修正
- DECLARE, CLOSE, FETCH, MOVEがロードバランスの対象にならなくなりました。(Tatsuo Ishii)
もしデータが更新され、トランザクションがコミットされた後にCLOSEが発行されるとデータの一貫性がなくなるからです (つまり、holdできるカーソルの場合のことを言っています)
- マスター/スレーブモードにおいて、拡張プロトコルのParseをマスター上でのみ実行するようにしました。(Tatsuo Ishii)
以前はすべてのノードでParseが実行されていたのですが、これだと 不必要なロックがスレーブでも取られてしまいます
- uninstallの前にすべてのランレベルからinitスクリプトを削除するようにしました(Devrim)
- 認証に失敗したときに適切なエラーメッセージを出すようにしました(Glyn Astill)
- ソケットへの書き込みに失敗したときにフロントエンド用なのかバックエンド用なのかわかるようにしました(Tatsuo Ishii)
- フロントエンド用のソケットに書き込み失敗したときにいちいちエラーを出さないようにしました(Tatsuo Ishii)
- マスター/スレーブモードで一時テーブルが使えるようになりました。(Tatsuo Ishii)
INSERT/UPDATE/DELETEは自動的にマスタのみに送られます。SELECTに関しては明示的にクエリの前に /*NO LOAD BALANCE*/というコメントを付けなければなりません。
2.2.5 (urukiboshi) 2009/10/4
概要
このバージョンでは、2.2.4以前の色々なバグが修正されています。
バグ修正
- コネクション数のカウントのミスにより、オンラインリカバリが終わらなくなるバグを修正しました(Tatsuo Ishii)
- 内部的にロックを発行する際にもフロントエンドが異常終了したことを検出して SQLコマンドをキャンセルするようにしました(Tatsuo Ishii)
- 接続の終了処理で無限ループに陥ることがあるバグを修正しました(Xavier Noguer, Tatsuo Ishii)
- 拡張プロトコルのパース処理でkind mismatch errorが起きた際に正しいSQL文を表示するようにしました(Tatsuo Ishii)
- ドキュメントを改善しました(Tatsuo Ishii)
2.2.4 (urukiboshi) 2009/8/24
概要
このバージョンでは、2.2.3以前の色々なバグが修正されています。
バグ修正
- pgpool-II 2.2.2で入ってしまったバグを修正しました。(Tatsuo Ishii)
フロントエンドがアボートするタイミングによっては、以後内部状態がリセットされず、 次のセッションでDMLやDDLがマスターノードのみ送られ、 ノード間でデータの不一致が生じることがありました。
- pgpool-II 2.2.3でバージョン2プロトコルのクライアントが動かなくなってしまっていたのを修正しました。(Tatsuo Ishii)
また、時間のかかるクエリを待っている間にフロントエンドが異常終了したことを検知する間隔を 1秒から30秒に変更しました。このチェックは、2.2.4ではプロトコルバージョンが3のときのみ有効です。
- 子プロセスを起動する前にシグナルのブロックやハンドラの設定を行なうようにしました。(Tatsuo Ishii)
これは、pgpool-IIを起動した直後にフェイルオーバなどの事象が発生して 子プロセスから親プロセスにシグナルが送られると、pgpool-IIの親プロセスが死んでしまうことがあるからです。
2.2.3 (urukiboshi) 2009/8/11
概要
このバージョンでは、2.2.2以前の色々なバグが修正されています。
バグ修正
- バックエンドに新しいコネクションを張る際に、バックエンドの一つが障害を起しているケースで、 後処理の中でpgpool-IIの子プロセスが落ちることがあるバグを修正しました(Tatsuo Ishii)
- パラレルクエリのバグを修正しました(Yoshiharu Mori)
- 拡張プロトコルの場合にもエラーメッセージの中で最後に使用したクエリが 表示できるようになりました(Akio Ishida)
- kind mismatch errorメッセージの作成で、メッセージ内容が壊れることがあるバグを修正しました(Tatsuo Ishii, Akio Ishida)
- バックエンドへの接続記述子の参照タイミングによってはpgpool-IIの子プロセスが 落ちることがあるバグを修正しました(Tatsuo Ishii)。
- pool_errorやpool_logの引数が間違っていた個所を修正しました(Akio Ishida)。
- statement_timeoutのタイムアウトによるエラー処理を改良しました。(Tatsuo Ishii)
実際にはタイムアウトまでにstatement_timeoutで設定した時間の倍かかっていたのを直しました。 また、masterだけがstatement_timeoutを返した場合にも対応できるようにしました。 以前はkind mismatchエラーになっていました (master以外がstatement_timeoutを返さないケースではkind mismatchエラーになります)。
- health checkをより強化し、postmasterがSIGSTOPで止ってしまっている場合も障害検知できるようにしました。
- バックエンドにSQLを投げ、その応答を待っている間にクライアントがpgpoolに対するコネクションを
切断したことが検出できるようになりました。(Tatsuo Ishii)
たとえば、WebアプリケーションではDBに対してリクエストを投げて、 応答がないとキャンセルするようなことが頻繁に起ります。 この場合、今まではpgpoolやPostgreSQLのプロセスが残ってしまい、同時接続数が枯渇したり、 ロックを取ったままのトランザクションが残るなどしてシステム全体に影響を与えることがありました。
今回の修正により、こうした状況が検出できるようになっただけでなく、 SQLの応答待ちの間にクライアントがコネクションを切断した際には、 SQLコマンドのキャンセルをpgpoolが行なって、ロック待ちなどのバックエンドプロセスが残るのを 防ぐことができるようになりました。
- 引数なしのCLUSTERコマンドはトランザクションの中では実行できないので、 自動トランザクションをスタートしないようにしました(Tatsuo Ishii)。
- 複数のプリペアドステートメントを使っている際に、セッションの終りで その一部だけが解放されるバグを修正しました(Akio Ishida)。
- sql/pgpool-recovery/pgpool-recovery.cがPostgreSQL 8.4でコンパイルできるようにしました(Tatsuo Ishii)。
- 拡張プロトコルを使っている場合に、クライアントとpgpoolの間でお互いに 待ち状態になってしまうことがあるバグを修正しました(Gavin Sherry)。
- COPY FROMを実行中にクライアントが処理を中断した場合に、バックエンドプロセスが 残ってしまうバグを修正しました(Tatsuo Ishii)。
2.2.2 (urukiboshi) 2009/5/5
概要
このバージョンでは、2.2.1以前の色々なバグが修正されています。 とりわけ、pgpoolがクライアントとの間でデータのやり取りをしている最中に、 pgpoolのクライアントが終了(X)パケットをpgpoolに送信せずに終了した場合に起る可能性があります。 このバグは過去のすべてのpgpoolに存在しています。
バグ修正
- フロントエンドにpgpoolがデータを送信する際のエラーを無視するようにしました。(Tatsuo Ishii)
これによって、バックエンドとの間で必要な処理が中断されないようになり、 バックエンドの間でデータの一貫性がなくなる問題が回避されるようになりました。
- マスタースレーブモードに関する2.2.1の修正の際に生じたバグを修正しました。 プリペアドステートメントを使い回すとハングアップする可能性がありました(Toshihiro Kitagawa)。
- SQLコマンドのPREPAREとプロトコルレベルのEXECUTEが混在するとバックエンドがクラッシュする バグを修正しました。このバグが、2.2で持ち込まれたものです(Tatsuo Ishii)。
- コネクションのリセット用の問合わせを実行中にエラーが起きた場合に、 PostgreSQLのログに"unexpected EOF on client connection"が記録される問題を修正しました(Tatsuo Ishii)。
2.2.1 (urukiboshi) 2009/4/25
概要
このバージョンでは、2.2の色々なバグが修正されています。
バグ修正
- master/slaveモードで、DEALLOCATEが失敗することがある問題を修正しました。 これは、最初のPREPAREがslaveで実行されないことによるものです(Toshihiro Kitagawa)
- pgpool.specなどを2.2対応にしました(Devrim)
- Version 2プロトコルではinsert_lockが無視されるようにしました(Tatsuo Ishii)
- パラメータ変更メッセージがバックエンドから届く度にログが出力されるのを止めました(Tatsuo Ishii)
- ドキュメントで追加し忘れたファイルを登録しました(Tatsuo Ishii)
2.2 (urukiboshi) 2009/2/28
概要
このバージョンでは、SERIALデータの扱いとオンラインリカバリに改良が行なわれています。 また、トランザクション分離レベルがシリアライザブルの場合に、DBノード間でデータの一貫性がなくなる可能性がある問題、 クエリのキャンセルができない問題が修正されました。
新機能
- insert_lock が有効な場合、SERIAL型を持つテーブルだけが ロックされるようになりました(Tatsuo Ishii)。
- 設定項目 client_idle_limit_in_recovery が追加されました。(Tatsuo Ishii)
オンラインリカバリの第2ステージでクライアントがアイドルのまま居座ることによって、 オンラインリカバリが進行しなくなることを防ぐことができます。
- 設定項目 pid_file_name が追加されました。(Tatsuo Ishii)
これは、pgpool-IIのpidファイルを指定します。 これにより、logdir は使用されなくなりました。
- DECLARE, FETCH, CLOSEで負荷分散されるようになりました(Tatsuo Ishii)。
- pcpコマンドにデバッグオプション(-d)が追加されました(Jun Kuriyama)。
- "kind mismatch"エラーの際に、原因となったクエリを表示するようにしました(Tatsuo Ishii)。
互換性
- フェイルオーバ時に必ずpgpoolの子プロセスを再起動するようにしました。(Tatsuo Ishii)
この結果、フェイルオーバ時には必ずpgpoolへのセッションが一端切れることになります。 こうしないと、ネットワークケーブル抜けなどの際に、 TCP/IPのレイヤで再送が行なわれ、長い時間そのままになってしまうことが あるからです。
- 設定項目 logdir は使われなくなりました。 代りに、pid_file_name を使ってください(Tatsuo Ishii)。
- insert_lock のデフォルト値がtrueになりました(Tatsuo Ishii)。
バグ修正
- pgpoolがデーモンモードで起動される際に、すべてのファイルディスクリプタを 閉じるようにしました。こうしないと、pgpoolAdminから起動された際に apacheのソケットファイルを引き継いでしまい、80番ポートが 専有されてしまいます(Akio Ishida)。
- トランザクションをシリアライズできないエラーが発生したときに、
すべてのDBノードのトランザクションをアボートするようにしました。
こうしないと、DBノードの間でデータの不整合が起きることがあります(Tatsuo Ishii)。
例を示します(Mはマスタ、Sはスレーブを示します)。
M:S1:BEGIN; M:S2:BEGIN; S:S1:BEGIN; S:S2:BEGIN; M:S1:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; M:S2:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; S:S1:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; S:S2:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; M:S1:UPDATE t1 SET i = i + 1; S:S1:UPDATE t1 SET i = i + 1; M:S2:UPDATE t1 SET i = i + 1; <-- blocked S:S1:COMMIT; M:S1:COMMIT; M:S2:ERROR: could not serialize access due to concurrent update S:S2:UPDATE t1 SET i = i + 1; <-- success in UPDATE and data becomes inconsistent!
- rawモードでMD5認証が使えるようにしました。ドキュメント上では使えるはずでした(Tatsuo Ishii)。
- "SET TRANSACTION ISOLATION LEVEL must be called before any query"の
エラーが発生した場合に"kind mimatch"エラーになることを防ぐようにしました(Tatsuo Ishii)。
以下のシナリオで問題が発生します。
M:S1:BEGIN; S:S1:BEGIN; M:S1:SELECT 1; <-- only sent to MASTER M:S1:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; S:S1:SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; M: <-- error S: <-- ok since no previous SELECT is sent. kind mismatch error occurs!
- FreeBSDにおいて、psでのprocess statusの表示で余計なスペースが含まれてしまうのを修正しました(Jun Kuriyama)
- BEGIN;を2度続けるとkind mismatch errorが発生するのを修正しました(Tatsuo Ishii)
- PostgreSQLがたくさんのDEBUGメッセージを出力する場合に、誤ってエラーと見なすバグを修正しました(Tatsuo Ishii)
- クエリのキャンセルが動くようになりました(Tatsuo Ishii)
- オンラインリカバリの後クライアントからの接続を受け付けるタイミングが早すぎるバグを修正しました。 このバグにより、ノードデータの貫性が保たれない可能性がありました(Tatsuo Ishii)
- SELECT, INSERT, UPDATE, DELETE以外のコマンドでも 必要ならばトランザクションブロックの内側で実行するようにしました。 これにより、エラー発生の際にロールバックしてノードの整合性を保つことができます(Tatsuo Ishii)
- オンラインリカバリ後、pgpool-IIの子プロセスがクラッシュすることがあるバグを修正しました。(Tatsuo Ishii)
これは、オンラインリカバリの後、新しくアタッチされたノードに接続がないのに、 そのノードに子プロセスが終了時に終了メッセージをバックエンドに送信しようとして起っていました。
- PostgreSQLがpostgresql.confを再読み込みした際にpgpoolがエラーを検出してしまうバグを修正しました。(Tatsuo Ishii)
これは、PostgreSQLが(たぶん)ドキュメントに書かれていないタイミングで 「パラメータ変更」パケットを送信してくるために起り、修正はそのことに対応したものです。
2.1 (inamiboshi) 2008/7/25
新機能
- failover_command と failback_command に、新しいマスタノード ID を表す '%m' をサポートしました。(Yoshiyuki Asaba)
- failover_command と failback_command に、古いマスタノード ID を 表す '%M' をサポートしました。(Yoshiyuki Asaba)
- リカバリのタイムアウト時間を指定する recovery_timeout パラメータを追加しました。(Taiki Yamaguchi)
- pg_md5 コマンドに -p オプションを追加しました。(Volkan Yazici, Taiki Yanaguchi)
- pgpool -v を実行するとバージョン番号を表示し、終了するようにし ました。(Yoshiyuki Asaba)
互換性
- pgpool_recovery と pgpool_remote_start 関数はスーパーユーザのみ 実行できるように権限チェックを強化しました。(Yoshiyuki Asaba)
- raw モードでスタンバイノードにはコネクションプールを作成しないようにしました。(Yoshiyuki Asaba)
- replication_timeout パラメータを削除しました。(Yoshiyuki Asaba)
- PCP クライアントコマンドのタイムアウトを無効にしました。(Taiki Yamaguchi)
- replicate_select = false の場合に、COPY TO STDOUT をレプリケー ションさせないようにしました。(Yoshiyuki Asaba)
修正
全般
- CloseComplete メッセージを受けとるとクラッシュする不具合を修正 しました。(Yoshiyuki Asaba)
- メッセージ転送処理を効率よくしました。(Yoshiyuki Asaba)
- Solaris 10 でコンパイルできるようにしました。(Yoshiyuki Asaba)
- ヘルスチェックとリカバリのログ出力を改良しました。(Tatsuo Ishii)
- 様々なメモリリークを修正しました。(Yoshiyuki Asaba)
- "failed to read kind from frontend" というエラーメッセージを ERRORレベルから LOG レベルに下げました。(Yoshiyuki Asaba)
- raw モードでフェイルオーバに失敗する不具合を修正しました。 (Taiki Yamaguchi)
- 不正なノードを追加・切り離しを行うとゾンビプロセスが発生する不 具合を修正しました。(Yoshiyuki Asaba)
- health_check_timeout が正しく動作しない不具合を修正しました。 (Kenichi Sawada)
- FreeBSD で ps コマンドの出力が正しくない不具合を修正しました。 (ISHIDA Akio)
- Unix domain ソケットが残っている場合のエラーメッセージを強化し ました。(Jun Kuriyama)
- 認証に失敗した場合のエラーメッセージを強化しました。(Tatsuo Ishii)
レプリケーション
- replicate_select を設定しても、常に false の挙動になる不具合を 修正しました。(Tatsuo Ishii)
- 拡張問い合わせプロトコルを使っていると、トランザクションを誤ってロー ルバックしてしまう不具合を修正しました。(Yoshiyuki Asaba)
- 非同期クエリを使っていると pgpool が不安定になる不具合を修正し ました。(Yoshiyuki Asaba)
- 拡張問合せプロトコルを使うと /* REPLICATION */などのヒント句が消えて しまう不具合を修正しました。(Yoshiyuki Asaba)
- DEALLOCATE ALL を実行するとクラッシュする不具合を修正しました。 (Yoshiyuki Asaba)
- immediate shutdown するとハングアップする不具合を修正しました。 (Yoshiyuki Asaba)
- 高負荷時にオンラインリカバリを実施すると、リカバリプロセスがハ ングアップする可能性のある不具合を修正しました。(Yoshiyuki Asaba)
- 拡張問合せプロトコルを使って SELECT を実行した際に、トランザク ションブロック内でクエリがエラーになると、pgpool がハングアップする 可能性のある不具合を修正しました。(Yoshiyuki Asaba)
マスタースレーブ
- トランザクションブロック内で、SET, PREPARE, DEALLOCATE を実行す ると、プロセスがダウンする不具合を修正しました。(Yoshiyuki Asaba)
- マスタースレーブモードでロードバランスが正しく動作していない不 具合を修正しました。(Yoshiyuki Asaba)
パラレルクエリ
- INSERT に失敗する不具合を修正しました。(Yoshiharu Mori)
- FROM 句に AS が含まれると構文エラーになる不具合を修正しました。(sho)
- クエリを複数回実行するとハングアップする不具合を修正しました。(Yoshiharu Mori)
- JOIN に失敗する不具合を修正しました。(Yoshiharu Mori)
- DISTINCT構文 の解析に失敗する不具合を修正しました。(Yoshiharu Mori)
2.0.1 (hikitsuboshi) 2007/11/21
- UPDATE もしくは DELETE を実行するとプロセスがダウンする不具合を 修正しました。(Yoshiyuki Asaba)
- master_slave を true に設定している場合に、SQL 構文エラーを検知 した時にマスタにのみそのクエリを送信するようにしました。(Yoshiyuki Asaba)
2.0 (hikitsuboshi) 2007/11/16
互換性
- ignore_leading_white_space のデフォルト値を true にしました。 (Yoshiyuki Asaba)
- replicate_strict を廃止しました。常に replicate_strict が true の挙動になります。(Yoshiyuki Asaba)
全般
- pgpool.conf をリロードできるようにしました。リロード時に分散ルールも同時にリロードします。(Yoshiyuki Asaba)
- SQL パーサを PostgreSQL 8.3 に対応しました。(Yoshiyuki Asaba)
- ノードを切り離した際にユーザが設定したコマンドを実行できるよう に、pgpool.conf に failover_command というパラメータを追加しました。 (Yoshiyuki Asaba)
- ノードを復帰した際にユーザが設定したコマンドを実行できるように、 pgpool.conf に failback_command というパラメータを追加しました。 (Yoshiyuki Asaba)
- pgpool.conf に client_idle_limit というパラメータを追加しました。 このパラメータではクライアントからのクエリの最大待ち時間を設定することができます。(Tatsuo Ishii)
レプリケーション
- トランザクションブロックに囲まれていないクエリをレプリケーションさせる場合、 内部的にトランザクションを開始させるようにしました。(Yoshiyuki Asaba)
- レプリケーションを高速化させるようにしました。(Yoshiyuki Asaba)
- ノードを再同期させて復帰させる、オンラインリカバリ機能を実装し ました。(Yoshiyuki Asaba)
- INSERT, UPDATE, DELETE した行数がすべて一致しなかった場合に、
トランザクションをアボートさせるようにしました。(Yoshiyuki Asaba)
x=# update t set a = a + 1; ERROR: pgpool detected difference of the number of update tuples HINT: check data consistency between master and other db node
- 複数のバックエンドから異なる結果が返ってきた場合に、同じ結果が 多数返ってきた結果を信頼する多数決方式を実装しました。(Yoshiyuki Asaba)
- V2 問合せプロトコルでロードバランスできるようにしました。(Yoshiyuki Asaba)
パラレルクエリ
- パラレルモードで部分レプリケーションをサポートしました。(Yoshiharu Mori)
1.3 (sohiboshi) 2007/10/23
- 新しく authentication_timeout という
パラメータを追加しました。(Yoshiyuki Asaba)
- このパラメータでは認証時間のタイムアウトを設定します。
- デフォルト値は 60 (1 分)です。
- スタートアップパケットの長さが 10000 バイト越えている場合には、接続を切断するようにしました。(Yoshiyuki Asaba)
- DEALLOCATE を実行するとまれに不正なメモリアクセスが発生する不具 合を修正しました。(Yoshiyuki Asaba)
- トランザクション内で SELECT を実行した後に SELECT を正しくロードバラ
ンスできない不具合を修正しました。(Yoshiyuki Asaba)
- この不具合は 1.2 で混入した不具合です。
- 64bit 環境でクエリキャッシュ機能を有効にすると、クラッシュする可能性のある不具合を修正しました(Yoshiyuki Asaba)
1.2.1 (tomoboshi) 2007/09/28
- 拡張問合せプロトコルの Parse メッセージの処理でデッドロックが発 生する可能性がある不具合を修正しました。(Yoshiyuki Asaba)
- Prepared statement を管理する領域がメモリリークしている不具合を 修正しました。(Yoshiyuki Asaba)
- 一部の OS でコンパイルエラーになる不具合を修正しました。(Yoshiyuki Asaba)
- master/slave モード内で SET, PREPARE, DEALLOCATE 文をレプリケーションさせるようにしました。(Yoshiyuki Asaba)
1.2 (tomoboshi) 2007/08/01
- pgpool.conf に replicate_select という新規パラメータを追加しま
した。デフォルト値は false です。(Yoshiyuki Asaba)
- true に設定した場合は、ロードバランスされない SELECT 文をレプリケーションします (pgpool-II 1.0 の挙動)。false の場合はマスタにのみ SELECT を送信します。
- シグナル処理を安全に行うようにしました。(Yoshiyuki Asaba)
- まれにゾンビプロセスが残ってしまったり、不安定になることがありました。
- トランザクション中に SELECT 文がエラーになると、ハングアップしてしまう不具合を修正しました。(Yoshiyuki Asaba)
- この不具合は 1.1 に入った不具合です。
- PREPARE/EXECUTE が master/slave モードで正しく動作しない不具合 を修正しました。(Yoshiyuki Asaba)
- デッドロックを検知すると、kind mismatch error が発生する不具合 を修正しました。(Yoshiyuki Asaba)
- 拡張問い合わせプロトコルを使ったドライバを使用した場合に、 構文解析時に警告が発生する SQL 文を実行するとハングアップもしくは プロセスがクラッシュする不具合を修正しました。(Yoshiyuki Asaba)
- コネクションキャッシュが一杯になるとメモリリークが発生する不具合を修正しました。(Yoshiyuki Asaba)
- セッションが残った状態で PostgreSQL を fast shutdown もしくは immediate shutdown すると、残ったセッションがハングアップする不具合 を修正しました。(Yoshiyuki Asaba)
- ロードバランス先を接続開始時に決定し、同じセッション内ではすべ て同じノードにクエリを送信するようにしました。(Yoshiyuki Asaba)
- connection_life_time を設定している場合に バッファオーバランが発生する可能性がある不具合を修正しました。(Yoshiyuki Asaba)
1.1.1 (amiboshi) 2007/06/15
- load_balance_mode を有効にしていると、"kind mismatch" エラーが 発生してしまう不具合を修正しました。これは 1.1 で入った不具合です。 (Yoshiyuki Asaba)
- プロトコルバージョン 2 を使ったドライバでレプリケーション使用す ると、pgpool がハングアップする不具合を修正しました(Yoshiyuki Asaba)
- 拡張問合せプロトコルを使用すると、まれにデッドロックが発生する 不具合を修正しました(Yoshiyuki Asaba)
1.1 (amiboshi) 2007/05/25
- HBA 認証をサポートしました(Taiki Yamaguchi)
- log_connections をサポートしました(Taiki Yamaguchi)
- log_hostname をサポートしました(Taiki Yamaguchi)
- ps コマンドで pgpool の状態がわかるようにしました(Taiki Yamaguchi)
- MacOS X でコンパイルエラーになる不具合を修正しました(Yoshiyuki Asaba)
- 拡張問い合わせプロトコルを使ったクエリをロードバランスできるようにしました(Yoshiyuki Asaba)
- レプリケーション設定時、SELECT は master にのみ送信するようにしました(Yoshiyuki Asaba)
- もし SELECT をレプリケーションさせる場合は /*REPLICATION*/ のように SELECT の前にコメントを付ける必要があります
- レプリケーション設定時、SELECT nextval() および SELECT setval() を自動的にレプリケーションさせるようにしました(Yoshiyuki Asaba)
- バックエンドへ接続中にシグナルに割り込まれると、フェイルオーバしてしまう不具合を修正しました(Yoshiyuki Asaba)
- PAM 認証のサンプルファイル pgpool.pam を $PREFIX/share/pgpool-II/ にインストールするようにしました(Taiki Yamaguchi)
- 巨大な SQL を実行しようとした場合に pgpool が無限ループに入る不具合を修正しました(Yoshiyuki Asaba)
1.0.2 (suboshi) 2007/02/13
- 巨大な SQL を実行しようとした場合に pgpool が無限ループに入る不具合を修正しました(Yoshiyuki Asaba)
- 拡張問合せプロトコルを使った場合にまれに pgpool が止まってしまう不具合を修正しました(Yoshiyuki Asaba)
- フェイルオーバ、フェイルバック時のログ出力を改善しました(Tatsuo Ishii)
- SHOW pool_status の結果にバックエンドステータス情報を追加しました(Tatsuo Ishii)
- レプリケーション時に UPDATE/DELETE の件数が実際の件数とは異なった結果を返す不具合を修正しました(Tatsuo Ishii)
- 古い gcc を使うと libpq のリンクに失敗する不具合を修正しました (Yoshiyuki Asaba)
- PHP:PDO や DBD-Pg を使った場合に、自動 DEALLOCATE が失敗してしまう不具合を修正しました(Yoshiyuki Asaba)
- SELECT FOR UPDATE, SELECT INTO をロードバランスさせないようにしました。 また、SELECT の前にコメントがある場合もロードバランスさせないようにしました。 これは pgpool-I との互換性のためです。(Yoshiyuki Asaba)
- configure 時の libpq のデフォルトパスを pg_config コマンドを使って取得するようにしました。 なお、--with-pgsql 関連のオプションは次のバージョンでは廃止予定です(Yoshiyuki Asaba)
- コネクションプール再利用時に、ソケットが壊れている場合は再接続するようにしました(Yoshiyuki Asaba)
- PostgreSQL 7.4.x の libpq を使ってビルドしようとすると、 configure スクリプトでエラーとなってしまう不具合を修正しました(Yoshiyuki Asaba)